
Datawhale 具身智能基础与机器人控制(一)
介绍了具身智能的基础概念与机器人控制方法。具身智能强调智能体通过身体与环境互动,涉及感知、决策和执行。文章首先讲解了机器人空间位姿描述方法,包括旋转矩阵和齐次变换矩阵,以及机械臂运动学的DH参数建模。其次介绍了PID控制原理及其在倒立摆控制中的应用。最后探讨了Habitat仿真环境在具身导航任务中的应用,包括环境搭建、传感器配置和任务组织。这些内容为具身智能研究提供了基础理论框架和实践方法。
Datawhale 具身智能基础与机器人控制(一)
task1的主线:
理解什么是具身智能,
理解机器人怎么描述空间和运动,
用 PID 这类控制方法让动作稳定下来,
用 Habitat 这样的仿真环境先练导航任务。
一、具身智能是什么
具身智能,就是智能体有一个“身体”,并通过身体和环境互动。
这里的身体可以是真实机器人,也可以是仿真里的 Agent。不只输入文字、输出文字,而是要看见环境、理解自己在哪、决定怎么动,并真的执行动作。
普通 AI 更像是在文字和数据里推理;具身智能要面对真实世界的约束,比如距离、角度、碰撞、重力、误差、延迟。它关心的不只是“知道什么”,还包括“怎么把事情做成”。
所以具身智能可以简单理解为:
智能的大脑(智能) + 可行动的身体(行动) + 会反馈的环境(感知)。
二、为什么要学机器人基础
机器人里最基础的事,是描述位置和姿态。一个点在相机坐标系里看到的位置,和它在机器人底座坐标系里的位置表示不同,必须做坐标变换。
空间位姿一般拆成两部分:旋转和平移。
绕 Z 轴旋转可以写成:
Rz(θ)=[cosθ−sinθ0sinθcosθ0001] R_z(\theta)= \begin{bmatrix} \cos\theta & -\sin\theta & 0 \\ \sin\theta & \cos\theta & 0 \\ 0 & 0 & 1 \end{bmatrix} Rz(θ)= cosθsinθ0−sinθcosθ0001
为了把旋转 RRR 和平移 PPP 放到一起,用齐次变换矩阵:
T=[RP01] T= \begin{bmatrix} R & P \\ 0 & 1 \end{bmatrix} T=[R0P1]
如果点 PPP 在坐标系 B 中的坐标是 PBP_BPB,想换到坐标系 A,就用:
PA=TABPB P_A = T_{AB}P_B PA=TABPB
齐次变换矩阵把旋转和平移统一放到一个矩阵里,方便把一个坐标系里的点换算到另一个坐标系里。
正运动学解决的是:已知关节角度,怎么算机械臂末端的位置和姿态。DH 参数法就是一种标准建模方法,用连杆长度、连杆扭角、关节偏距、关节角度来描述机械臂结构。
DH 参数法就是用来标准化描述机械臂连杆关系的。相邻两个连杆之间用四个量描述:
- aia_iai:连杆长度
- αi\alpha_iαi:连杆扭角
- did_idi:关节偏距
- θi\theta_iθi:关节角度
相邻连杆的变换矩阵可以写成:
Ti−1i=Rotz(θi)⋅Transz(di)⋅Transx(ai)⋅Rotx(αi) T_{i-1}^{i}=Rot_z(\theta_i) \cdot Trans_z(d_i) \cdot Trans_x(a_i) \cdot Rot_x(\alpha_i) Ti−1i=Rotz(θi)⋅Transz(di)⋅Transx(ai)⋅Rotx(αi)
多个连杆串起来,就是矩阵连乘:
T0n=T01T12...Tn−1n T_0^n = T_0^1T_1^2...T_{n-1}^n T0n=T01T12...Tn−1n
比如二连杆平面机械臂,末端位置可以直观看成:
x=l1cosθ1+l2cos(θ1+θ2) x=l_1\cos\theta_1+l_2\cos(\theta_1+\theta_2) x=l1cosθ1+l2cos(θ1+θ2)
y=l1sinθ1+l2sin(θ1+θ2) y=l_1\sin\theta_1+l_2\sin(\theta_1+\theta_2) y=l1sinθ1+l2sin(θ1+θ2)
机械臂末端的位置不是随便给的,是由关节角和连杆长度共同决定的。
三、为什么要学 PID 控制
运动学“理论上怎么到”,控制算法实现“现实里怎么到”。
PID 的核心根据误差调输出。设目标值和当前值的误差为:
e(t)=r(t)−y(t) e(t)=r(t)-y(t) e(t)=r(t)−y(t)
PID 输出为:
u(t)=Kpe(t)+Ki∫e(t)dt+Kdde(t)dt u(t)=K_pe(t)+K_i\int e(t)dt+K_d\frac{de(t)}{dt} u(t)=Kpe(t)+Ki∫e(t)dt+Kddtde(t)
P 看当前误差,误差大就多调;
I 看累计误差,消除长期偏差;
D 看误差变化趋势,抑制震荡和超调。
CartPole 实践实际用的是 PD 控制,主要用 P 和 D。因为倒立摆更关心快速拉回和平稳,不需要积分项。
CartPole 的目标很简单:小车位置保持在 0,杆子角度保持在 0。
状态写成:
X=[xx˙θθ˙]X= \begin{bmatrix} x \\ \dot{x} \\ \theta \\ \dot{\theta} \end{bmatrix}X= xx˙θθ˙
其中 xxx 是小车位置,θ\thetaθ 是杆子角度。
材料里对倒立摆做了小角度近似:
sinθ≈θ,cosθ≈1 \sin\theta \approx \theta,\quad \cos\theta \approx 1 sinθ≈θ,cosθ≈1
近似后可以整理成状态空间方程:
X˙=AX+BF \dot{X}=AX+BF X˙=AX+BF
也就是:
[x˙x¨θ˙θ¨]=A[xx˙θθ˙]+BF \begin{bmatrix} \dot{x} \\ \ddot{x} \\ \dot{\theta} \\ \ddot{\theta}\end{bmatrix} =A \begin{bmatrix} x \\ \dot{x} \\ \theta \\ \dot{\theta} \end{bmatrix} + B F x˙x¨θ˙θ¨ =A xx˙θθ˙ +BF
这一步把“倒立摆怎么动”变成了控制器能用的数学模型。PID、LQR、MPC 都是在这个模型基础上想办法算控制输入。
材料里的 PD 思路很朴素:
小车偏离中心,就根据位置误差和误差变化量修正;
杆子偏离竖直,就根据角度误差和误差变化量修正。
代码里的形式是:
u=Kpe+Kd(e−elast) u = K_p e + K_d(e-e_{last}) u=Kpe+Kd(e−elast)
CartPole 讲了控制闭环的实操:看状态,算误差,给力,再看新状态,再修正。
四、为什么要学 Habitat 导航
真实导航实验太贵,所以先在仿真里做。Habitat 这部分就是具身导航的入门环境。
Habitat 分两层:
Habitat-Sim 是仿真引擎,负责底层世界。包括加载 3D 场景、渲染 RGB 图、深度图、语义图,模拟智能体移动和碰撞。
Habitat-Lab 是任务框架,负责上层实验。定义任务、数据集、传感器、动作空间、评估指标。
Habitat-Sim 环境搭建时,教程用的是 habitat-sim=0.2.5。
Sim 里最重要的是:
- 场景:比如 MP3D、HM3D、Gibson、Replica。
- 传感器:RGB、Depth、Semantic。
- 动作:前进、左转、右转。
- 数据集:测试场景、示例对象、后续可能用到 HM3D v0.2。
传感器大概对应:
RGB 看外观;
Depth 看距离和空间结构;
Semantic 看每个像素属于什么类别。
如果语义图显示不正常,通常是因为没有加载 scene_dataset_config.json,语义 ID 没法映射到具体类别。
五、Habitat Lab 解决“导航任务怎么组织”的问题
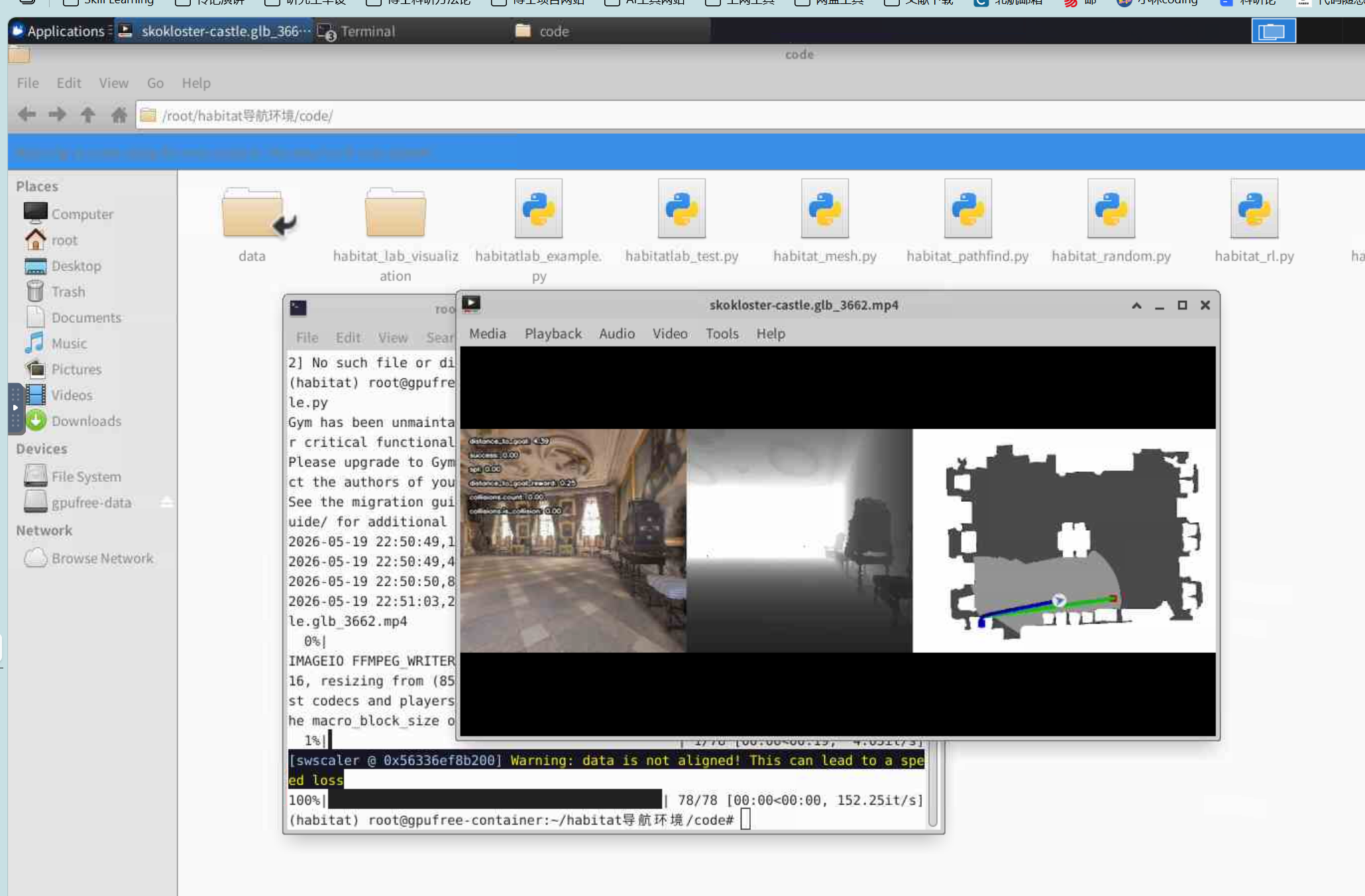
Habitat-Lab 最大的特点是用 YAML 配置任务。
PointNav 是这里的基础任务:给智能体一个目标点,让它从起点走到目标点。这个任务简单,但包含导航的基本要素:场景、起点、目标、观测、动作、终止条件和评估指标。
habitatlab_test.py 的运行流程可以记成五步:
- 加载 YAML 配置;
- 初始化环境;
- 重置环境拿到观测;
- 执行动作控制智能体;
- 达到最大步数或任务结束。
YAML 里最重要的几块是:
habitat.dataset:数据集路径、场景路径、训练或测试 split。habitat.environment:最大 episode 步数、时间限制。habitat.task:任务类型、奖励、成功条件、测量指标。habitat.simulator:底层模拟器、前进步长、转弯角度。habitat.simulator.agents:智能体高度、半径、RGB/Depth 传感器。
比如材料里的基础配置把最大步数设成:
habitat:
environment:
max_episode_steps: 500
传感器分辨率设成:
sim_sensors:
rgb_sensor:
width: 256
height: 256
depth_sensor:
width: 256
height: 256
注意YAML 里看到的不是全部配置。很多默认配置会在 Habitat-Lab 内部补齐,最后再传给 Habitat-Sim 创建真正的仿真环境。
教程地址:
https://github.com/datawhalechina/every-embodied/blob/main

电影级数字人,免显卡端渲染SDK,十行代码即可调用,工业级demo免费开源下载!
更多推荐
 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)