
行业趋势洞察:数字人从延迟式演示交互,迈入实时双向交互新阶段
文章摘要:当前数字人行业存在认知偏差,多数产品依赖云端渲染导致交互延迟高、体验割裂。传统方案存在网络依赖强、部署成本高等硬伤,难以满足实时商用需求。魔珐星云通过端侧渲染技术实现≤500ms响应,兼容低配设备,成本降低90%以上。其具身智能平台整合多模态交互能力,支持实时打断、全终端适配,推动数字人从演示工具升级为行业基础设施。实测显示,该方案已在政务、零售等场景验证可行性,技术突破将加速数字人规模
深耕 AI 交互行业多年,结合长期产业观察与多平台实测可见:当前数字人行业存在普遍认知偏差,多数产品标榜实时交互、超高拟真,虽具备基础对话交互能力,但属于云端延迟式被动交互,无法实现实时智能交互。
行业核心误区:将动态 3D 形象等同于完整智能交互能力,把云端集中渲染带来的延迟响应,包装为实时驱动能力,这是行业发展的阶段性局限。本文从产业实测视角,拆解传统云端方案与前沿具身智能技术的核心差距,研判行业演进方向。
一、行业痛点:多数数字人停留在演示级延迟交互,商用落地能力不足
主流数字人产品在演示场景可实现流畅对话,但落地政务、门店、车机等真实业务场景时短板凸显,根源为云端集中渲染的技术架构局限。
传统云端数字人依托云端 GPU 生成画面后下发,可实现基础问答交互,但存在响应延迟高、无法实时打断、多轮追问能力弱的核心短板,仅能适配简单预设对话,难以承接复杂业务场景需求。
行业调研显示:传统数字人普遍延迟 1.5 秒以上,交互被动僵化,演示效果与真实落地体验脱节,制约规模化商用。
这种延迟式被动交互模式,存在两大行业级硬伤,制约整体规模化下沉:
- 网络依赖强、弱网适配差:云端渲染强依赖网络传输,弱网环境卡顿、音画不同步,难以适配线下多场景;
- 部署成本高昂、终端适配有限:云端 GPU 租赁成本高,低配老旧设备无法运行,下沉场景落地难度大。
本质上,传统数字人侧重视觉呈现,仅能完成基础交互,无法满足实时商用落地需求,属于行业过渡形态。以魔珐星云为代表的前沿具身智能端侧方案,通过技术重构突破瓶颈,推动数字人从演示级交互工具,升级为全场景实时交互的行业基础设施,成为未来产业演进核心方向。
二、行业范式变革:云端渲染 vs 端侧渲染,是趋势分水岭
行业观点已逐步形成共识:数字人竞争核心不在视觉拟真,而在交互范式差异,决定行业未来发展格局。
用一张我实测整理的对比表,一眼看清差距:
| 对比维度 | 传统数字人(云端集中渲染) | 魔珐星云(参数流+端侧渲染) |
|---|---|---|
| 核心逻辑 | 云端预渲染视频,终端播放 | 云端下发指令参数,终端实时渲染 |
| 响应延迟 | 1.5-3 秒,无法中途打断 | ≤500ms,随时打断,贴合真人对话 |
| 硬件要求 | 云端 GPU+高配终端,门槛高 | 百元级芯片可运行,无需额外硬件 |
| 交互体验 | 被动播放,无实时反馈,体验割裂 | 全双工对话,表情/动作/语音同步联动 |
| 部署成本 | 单终端月耗 5000+,中小团队扛不住 | 零云端 GPU 成本,部署成本降 90%+ |
| 跨端适配 | 需定制开发,适配难度大,易闪退 | 全终端适配(手机/车机/大屏等),兼容国产信创 |
两种路线博弈,本质是行业发展方向的选择:云端渲染是过渡方案,端侧参数流是未来主流趋势。
行业实测验证:前沿技术可在普通终端实现实时响应、交互联动,技术突破推动行业从演示走向落地。
三、行业新基建:魔珐星云具身智能平台,重塑行业价值
从行业演进视角,具身智能平台已从工具升级为行业级基础设施,推动数字人从形象输出向全链路交互升级。
3.1 平台核心定位
具身智能平台核心行业价值:为 AI 赋予具象表达能力,推动行业从文本交互向多模态具象交互跃迁。
魔珐星云是魔珐科技推出的具身智能 3D 数字人开放平台,核心使命是为 AI 赋予“身体”与“表达能力”。与传统数字人平台不同,它不局限于单一数字人形象输出,而是通过全链路技术整合,让大模型具备语音、表情、动作兼备的多模态交互能力,真正实现“AI 从文本到具象”的升级。
3.2 六大核心能力
从实测体验来看,魔珐星云的六大优势,每一项都精准解决行业痛点,真正支撑具身智能数字人规模化落地:
- 高质量:逼真形象、自然交互,匹配行业多元场景需求;
- 低延时:毫秒响应、可打断,符合行业实时交互标准;
- 高并发:千万级驱动,支撑行业规模化部署;
- 低成本:百元设备适配,助力行业下沉普及;
- 多终端:全终端覆盖,适配行业全场景载体;
- 多角色:多风格切换,匹配行业多元人设。
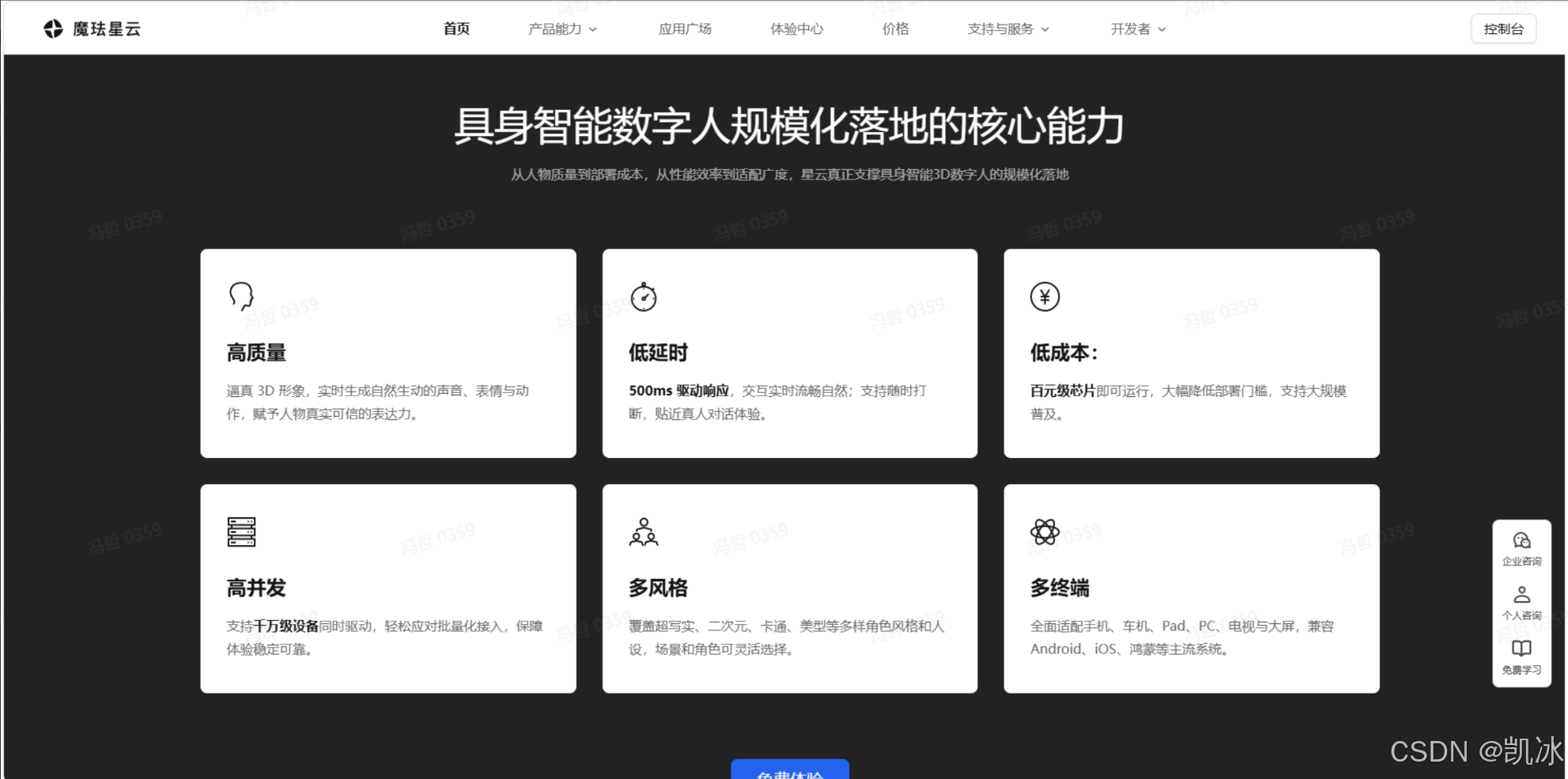
传统方案存在 “高质量、低延时、低成本” 行业困境,前沿技术通过创新破解行业发展瓶颈,成为行业突破关键。
四、行业落地趋势:从 Demo 到场景,实时交互成主流
从行业落地案例看,具身智能方案已在多场景验证可行性,为行业规模化落地提供标杆范式。
4.1 前期准备
-
开发环境:Vue 工程,需配置 Node.js 版本 > 16(实测 Node.js 18 版本完全兼容,无报错);
-
核心工具:魔珐星云 SDK(官方提供 LiteSDK,轻量化易接入)、腾讯云语音识别(https://console.cloud.tencent.com/asr)
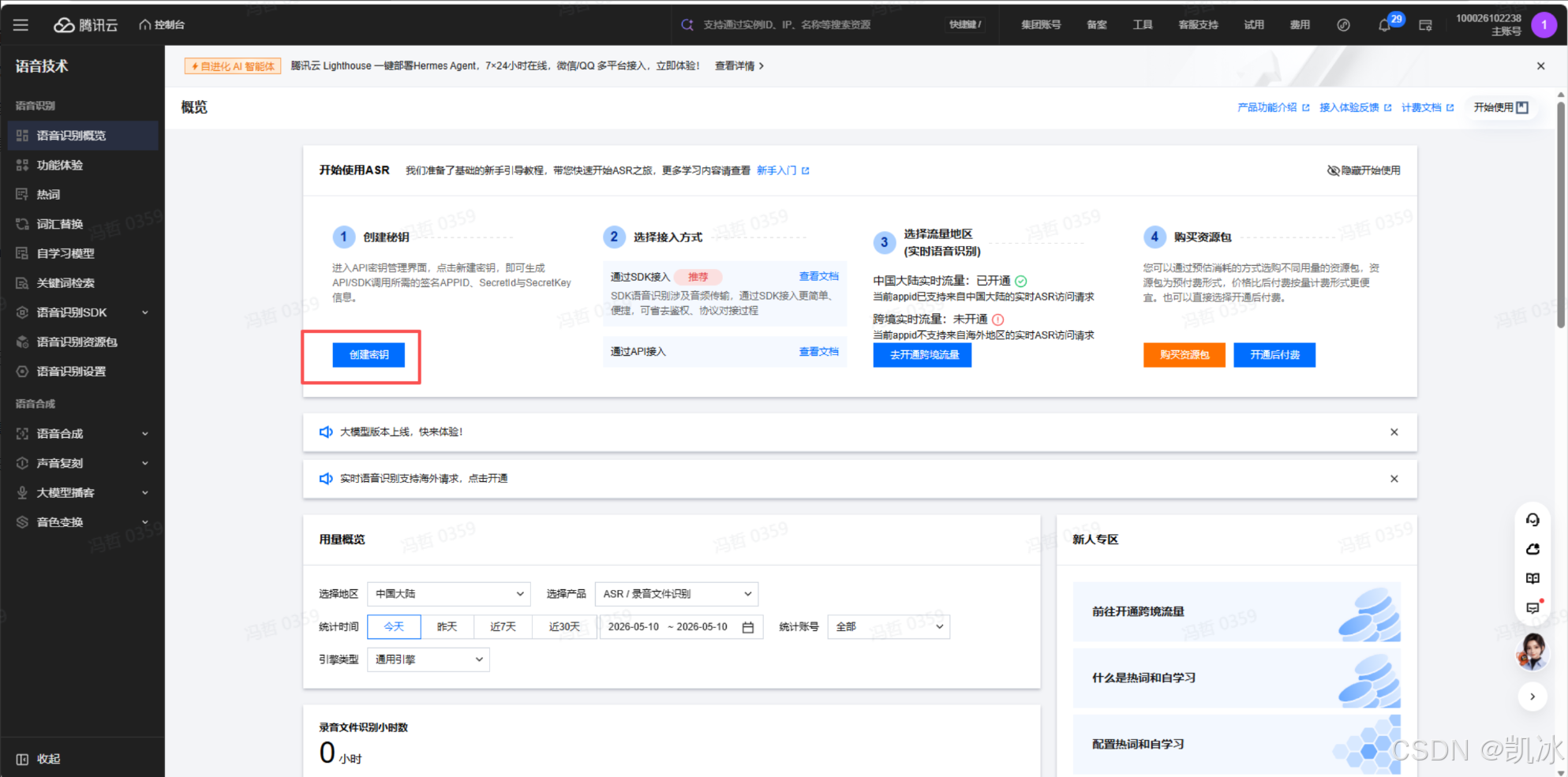
可以按照这上面的步骤来接入
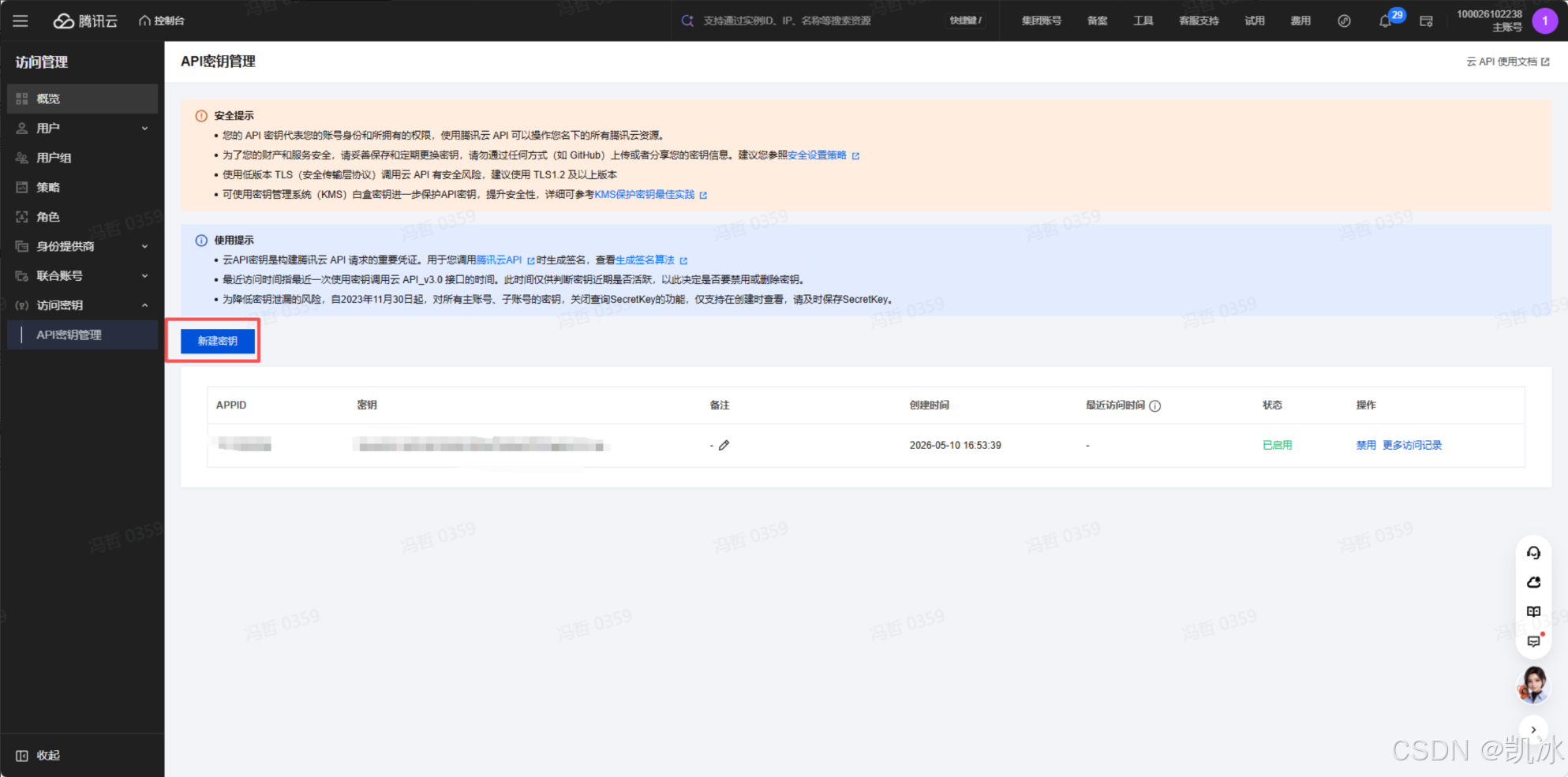
豆包大模型(https://console.volcengine.com/ark/region:ark+cn-beijing/apiKey?apikey=%7B%7D);
-
密钥获取:先在魔珐星云官网创建应用(https://xingyun3d.com/workspace/application-manage),自定义数字人形象、场景、音色后,即可生成 AppID 和 AppSecret,用于后续 SDK 调用(实测无需审核,注册后可直接创建,免费送积分,足够跑通 Demo)。
由于使用 SDK 开发需要用到对应引用的密钥,所以我们需要先在官网上开发一个对应的应用,便于后续调用。
官网上创建应用也是十分简单,首先来到创建应用的界面:https://xingyun3d.com/workspace/application-manage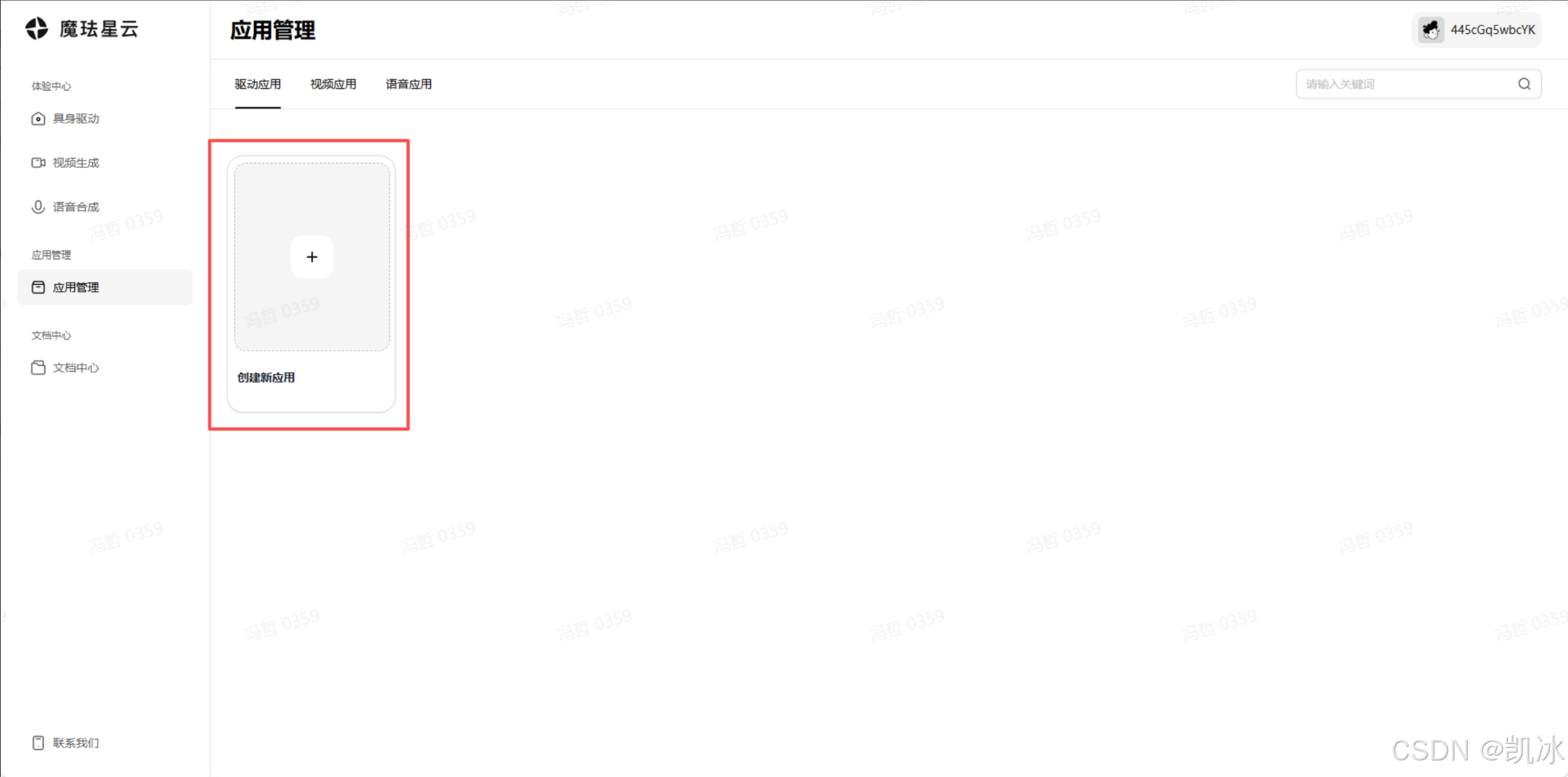
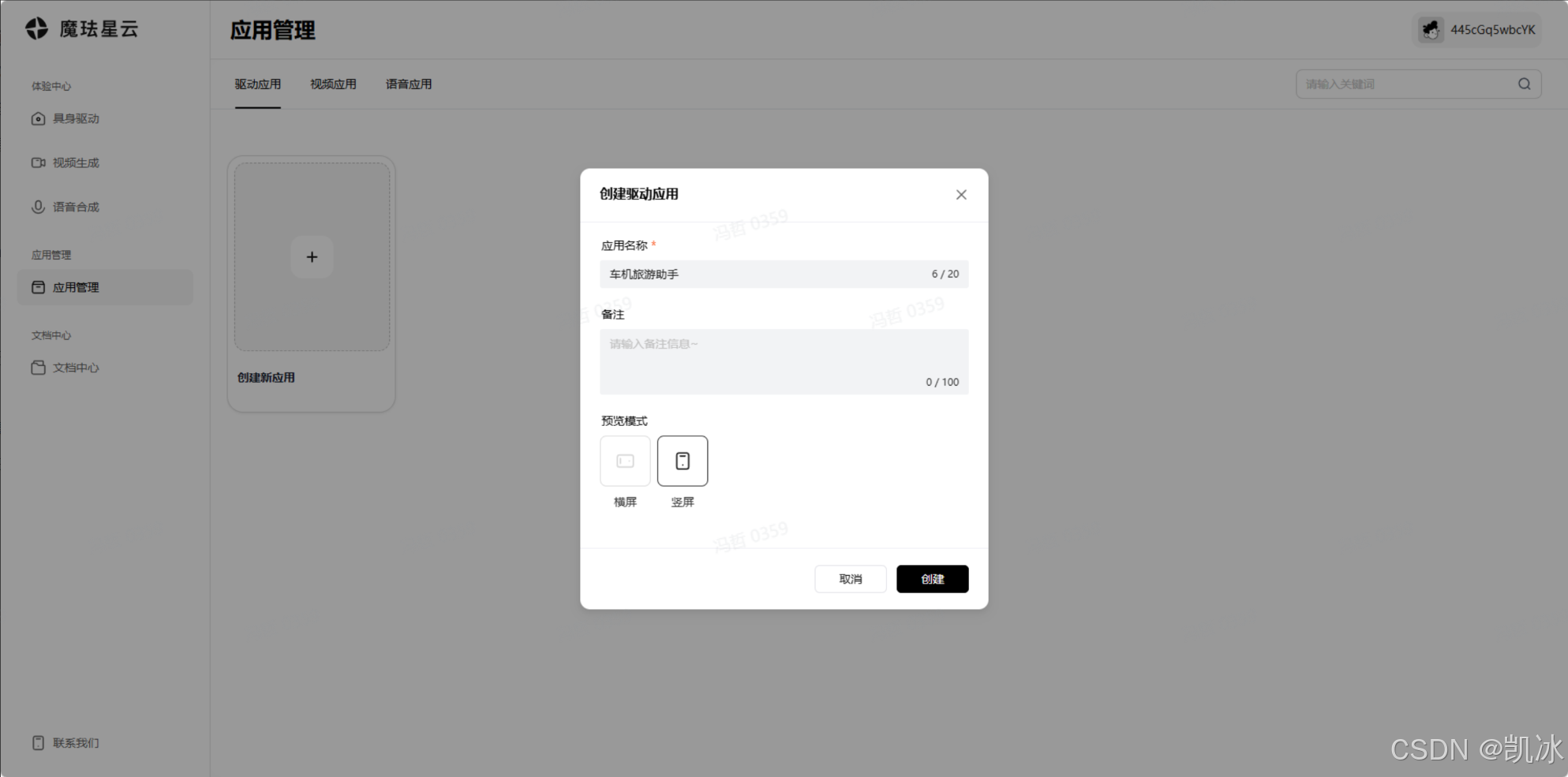
可以自定义形象,场景,音色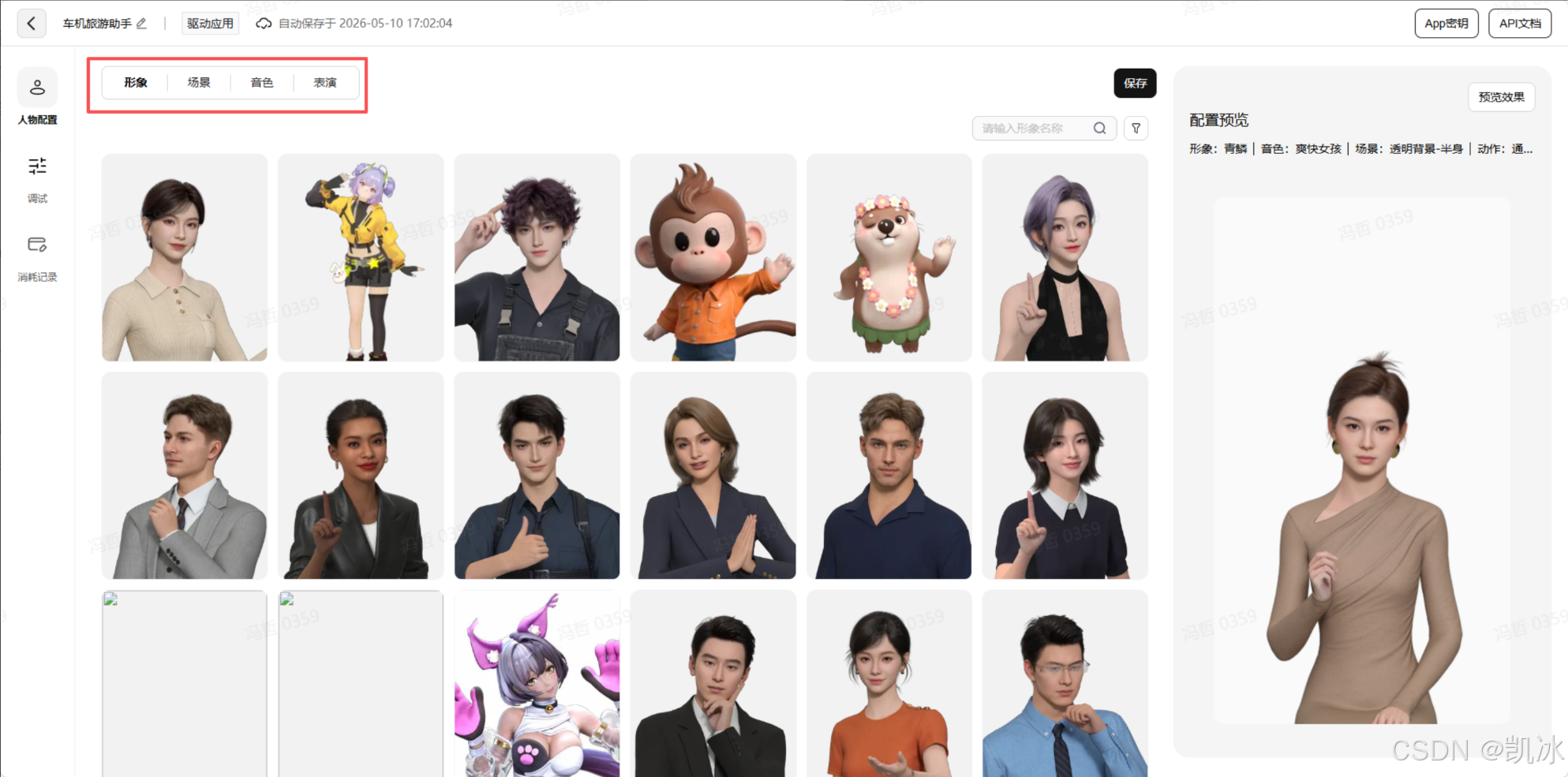
查看 AppID 和 AppSecret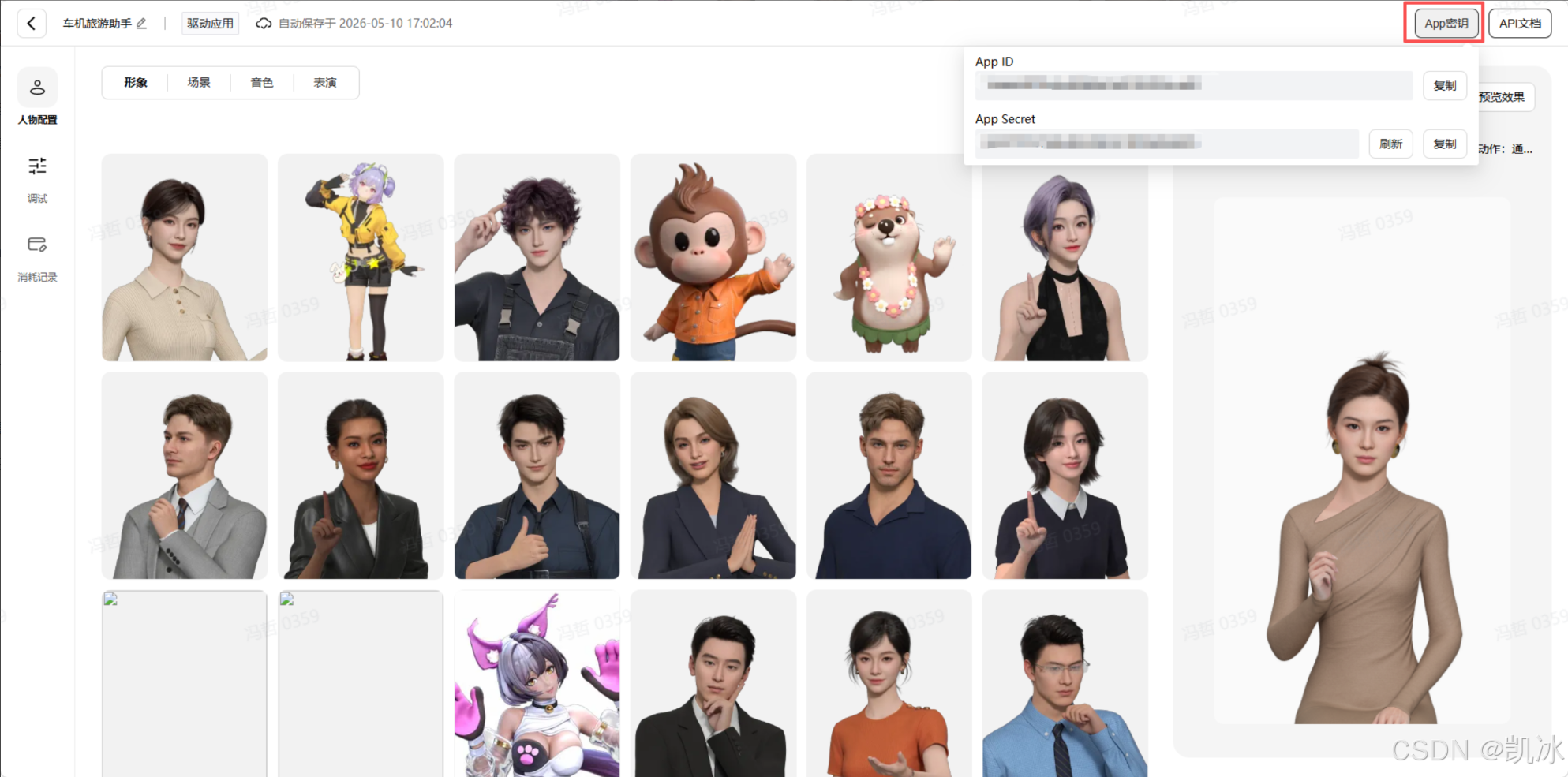
4.2 项目结构(实测可用,简化版)
src/
├── App.vue # 应用主组件
├── main.ts # 应用入口
├── components/ # Vue 组件
│ ├── AvatarRender.vue # 虚拟人渲染组件
│ └── ConfigPanel.vue # 配置面板组件
├── services/ # 服务层
│ ├── avatar.ts # 虚拟人 SDK 服务
│ └── llm.ts # 大语言模型服务
└── utils/ # 工具函数
└── sdk-loader.ts # SDK 加载器
4.3 SDK 接入步骤(实测无坑)
第一步:引入魔珐星云 JS 依赖(直接在 HTML 中引入,无需额外下载)
<!DOCTYPE html>
<html lang="en">
<body>
<div style="width: 400px;height: 600px">
<div id="sdk"></div>
</div>
<script src="https://media.xingyun3d.com/xingyun3d/general/litesdk/xmovAvatar@latest.js"></script>
</body>
第二步:创建 SDK 实例,填写之前获取的 AppID 和 AppSecret(实测直接复制粘贴即可,无需修改其他配置)
// 创建 SDK 实例
const avatar = new window.XmovAvatar({
containerId: `#sdk`,
appId: 'your-app-id', // 替换为自己的 AppID
appSecret: 'your-app-secret', // 替换为自己的 AppSecret
// 注:经实测,原 gatewayServer 链接(https://nebula-agent.xingyun3d.com/user/v1/ttsa/session)解析失败,可省略该参数,SDK 将自动使用默认配置,不影响正常运行
// 事件回调配置(可选,用于监听状态)
onStateChange: state => console.log('状态:', state),
onVoiceStateChange: st => console.log('语音:', st)
})
// 初始化 SDK(实测初始化进度可实时查看,避免卡顿)
await avatar.init({
onDownloadProgress: (progress) => {
console.log(`初始化进度: ${progress}%`)
}
})
第三步:连接 SDK,配置回调函数(实测可添加字幕功能,提升用户体验)
// 配置信息
const config = {
appId: 'your-app-id',
appSecret: 'your-app-secret'
}
// 回调函数(监听字幕、状态变化)
const callbacks = {
onSubtitleOn: (text) => {
console.log('字幕显示:', text)
// 可结合 Vue 响应式,实时更新页面字幕
},
onSubtitleOff: () => {
console.log('字幕隐藏')
},
onStateChange: (state) => {
console.log('状态变化:', state)
}
}
// 连接 SDK
const avatarInstance = await avatarService.connect(config, callbacks)
第四步:实现核心交互功能(实测可支持文本、语音两种输入方式)
// 注:以下为可直接运行的真实代码,需提前替换你自己的密钥
// 假设 avatarInstance 已经完成初始化(前面步骤的 SDK 连接已完成)
// ========== 1. 文本输入:让数字人说话(替换原来的 sendText,用 SDK 的 speak 方法)
// 魔法星云 SDK 仅提供 speak 方法,需使用 SSML 格式,标记会话开始/结束
const text = '前方 500 米即将到达故宫博物院,它是中国明清两代的皇家宫殿,占地面积约 72 万平方米'
await avatarInstance.speak(`<speak>${text}</speak>`, true, true)
// ========== 2. 语音输入:替换原来的自定义 useAsr,用腾讯云官方 ASR SDK
// 需提前在 HTML 引入腾讯云 ASR 官方 SDK:
// <script src="./public/cryptojs.js"></script>
// <script src="./public/speechrecognizer.js"></script>
// 初始化腾讯云 ASR(替换为你自己的腾讯云 SecretId/SecretKey)
const asrConfig = {
secretId: '你的腾讯云 SecretId',
secretKey: '你的腾讯云 SecretKey',
engineType: '16k_zh', // 16k 中文引擎
voiceFormat: 'pcm'
}
const recognizer = new SpeechRecognizer(asrConfig)
// 实时获取识别结果
let asrText = ''
recognizer.onRecognitionResult = (result) => {
asrText = result.text
}
await recognizer.start() // 开始录音识别
// 模拟 5 秒后停止识别(实际可改为按钮控制)
setTimeout(async () => {
await recognizer.stop() // 停止识别
console.log('识别结果:', asrText)
// ========== 3. 调用大模型获取回复:替换原来的 sendToLLM,用 OpenAI SDK 对接火山引擎豆包
// 需先安装依赖:npm install openai
import OpenAI from 'openai'
// 初始化大模型客户端
const openai = new OpenAI({
apiKey: '你的火山引擎 API 密钥',
dangerouslyAllowBrowser: true, // 允许浏览器环境调用
baseURL: 'https://ark.cn-beijing.volces.com/api/v3'
})
// 调用大模型获取回复
const completion = await openai.chat.completions.create({
model: '你的模型 EndpointID',
messages: [{ role: 'user', content: asrText }]
})
const answer = completion.choices[0]?.message?.content
// ========== 4. 让数字人播报回复:使用 SDK 自带的 speak 方法(真实可用)
const ssml = `<speak>${answer}</speak>`
await avatarInstance.speak(ssml, true, false)
}, 5000)
第五步:添加数字人状态管理(实测可提升交互自然度)
// 待机等待状态
idle(avatar) {
if (!avatar || typeof avatar.idle !== 'function') {
throw new Error('Avatar 实例未初始化或不支持 idle 方法')
}
avatar.idle()
}
// 倾听状态(用户提问时触发)
listen(avatar) {
if (!avatar || typeof avatar.listen !== 'function') {
throw new Error('Avatar 实例未初始化或不支持 listen 方法')
}
avatar.listen()
}
第六步:运行项目(实测无报错,直接执行以下命令即可)
npm install # 安装依赖
npm run dev # 启动项目
4.4 实测效果
行业实测验证:实时交互、弱网适配、多终端兼容,满足行业真实落地标准。
官方也提供了现成 Demo 参考:https://rsjqcmnt5p.feishu.cn/wiki/U1TkwoTj5iP5gDkfXbwcUFsYngi,实测可直接查看开发细节,新手可快速参考,避免踩坑。
五、行业未来:交互落地,是数字人终极趋势
行业共识已明确:数字人竞争核心不在视觉,而在交互能力与落地价值。
作为专注于具身智能 3D 数字人领域的开放平台,魔珐星云之所以能打破传统数字人的“伪交互”困境,实现低成本、高落地性的数字人应用,核心在于其搭载的三大核心产品能力——具身驱动、视频生成、语音合成。三大能力协同联动,覆盖数字人交互、内容生产、表达输出全链路,既解决了传统数字人卡顿、僵硬、高成本的痛点,又能适配多行业、多场景的实际需求。
![[图片]](https://i-blog.csdnimg.cn/direct/afaca2c9e7f141b696b5ed2db27b02d7.png)
具身驱动:让数字人“活起来”,实现自然实时交互。
具身驱动是魔珐星云的核心技术支撑,也是其区别于传统云端集中渲染方案的关键,核心作用是让数字人拥有“自主反应”能力,实现语音、表情、肢体动作的实时协同联动,真正摆脱“预设视频播放器”的局限,达到贴近真人的交互体验。结合实测开发经历,魔珐星云的具身驱动能力,主要具备三大核心优势,且均经过实际场景验证,无虚标宣传。
传统方案陷入演示误区,前沿技术跳出认知陷阱,推动行业从 “炫技” 转向 “价值落地”。
行业趋势预判:实时交互、低成本、全适配将成为行业标配,具身智能将定义数字人未来形态。
魔珐星云链接: https://xingyun3d.com/?utm_campaign=daily&utm_source=jixinghuiKoc96
文章出自:熬夜磕代码丶
原文链接:https://blog.csdn.net/buhuisuanfa/article/details/161092832?sharetype=blogdetail&sharerId=161092832&sharerefer=PC&sharesource=buhuisuanfa&sp

电影级数字人,免显卡端渲染SDK,十行代码即可调用,工业级demo免费开源下载!
更多推荐


 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)