
从 0 到 1:用魔珐星云打造真实可用的智能健身私教【技术原理文章】
传统健身工具存在交互痛点,缺乏沉浸式陪伴体验。魔珐星云通过端侧实时渲染技术,打造低延迟、高并发的数字人私教方案,实现500ms响应、动态共情和个性化指导。相比传统云端方案,该技术突破3-5秒延迟瓶颈,支持实时打断和全终端适配,可应用于家庭APP、智能硬件等多场景。开发案例显示,系统可实现1秒内响应,提供有温度的交互体验,但需注意HTTPS环境要求和数据持久化处理。该方案有效解决了健身场景的陪伴感和
> 我在学习具身智能的实战文章,本文为技术文章,非广告
一、健身交互痛点:传统数字人 / 健身工具缺失沉浸式陪伴式互动
日常健身长期存在行业共性痛点:不管是纯视频课程,还是传统云端实时交互数字人,都难以实现生活化陪伴式交互。用户锻炼多为打开应用、跟随固定内容练习,过程枯燥、缺少实时反馈,很容易分心放弃;运动结束后仅能看到基础数据,无法获得针对性指导与情绪鼓励,长期坚持难度极大。
核心问题在于:传统健身工具、传统云端数字人,仅能完成标准化被动交互,无法实时捕捉用户训练状态、动态共情、即时正向引导,用户如同独自训练,缺失真人私教的陪伴感与参与感。而魔珐星云依托端侧实时渲染技术,可打造具备实时互动、精准反馈、情绪陪伴的数字人私教,补齐健身场景的核心交互短板。
二、现有模式短板:两类健身交互的体验局限
梳理市面主流健身交互模式,可清晰看到行业瓶颈,即便同为数字人方案,体验差距也十分明显:
方案一:视频跟练类
- 实现方式:预录固定视频 + 基础数据计数,无实时交互
- 使用短板:动作对错无实时提醒,内容固定单一,无个性化适配
- 体验感受:被动跟随练习,枯燥无互动,完全缺少陪伴感
方案二:传统云端实时交互数字人(动作识别类)
- 实现方式:摄像头捕捉 + 骨骼检测 + 云端集中渲染,支持实时对话
- 使用短板:云端响应延迟 3‑5 秒,表情动作依赖模板、无法实时打断;仅机械判定动作对错,无法给出优化建议、动态鼓励;部署成本高、终端适配有限,难以轻量化落地
- 体验感受:冰冷机械的被动评判,只有纠错没有共情,交互刻板僵硬
真正适配大众日常健身的,是轻量化、可落地、有温度、实时双向互动的数字人私教:可同步训练数据、即时鼓励、根据状态动态调整训练节奏,既摆脱固定视频的僵化,又规避传统云端数字人延迟高、成本高、落地难的问题,实现低成本普惠式私教体验。
三、方案选型:魔珐星云端侧交互带来全场景差异化优势
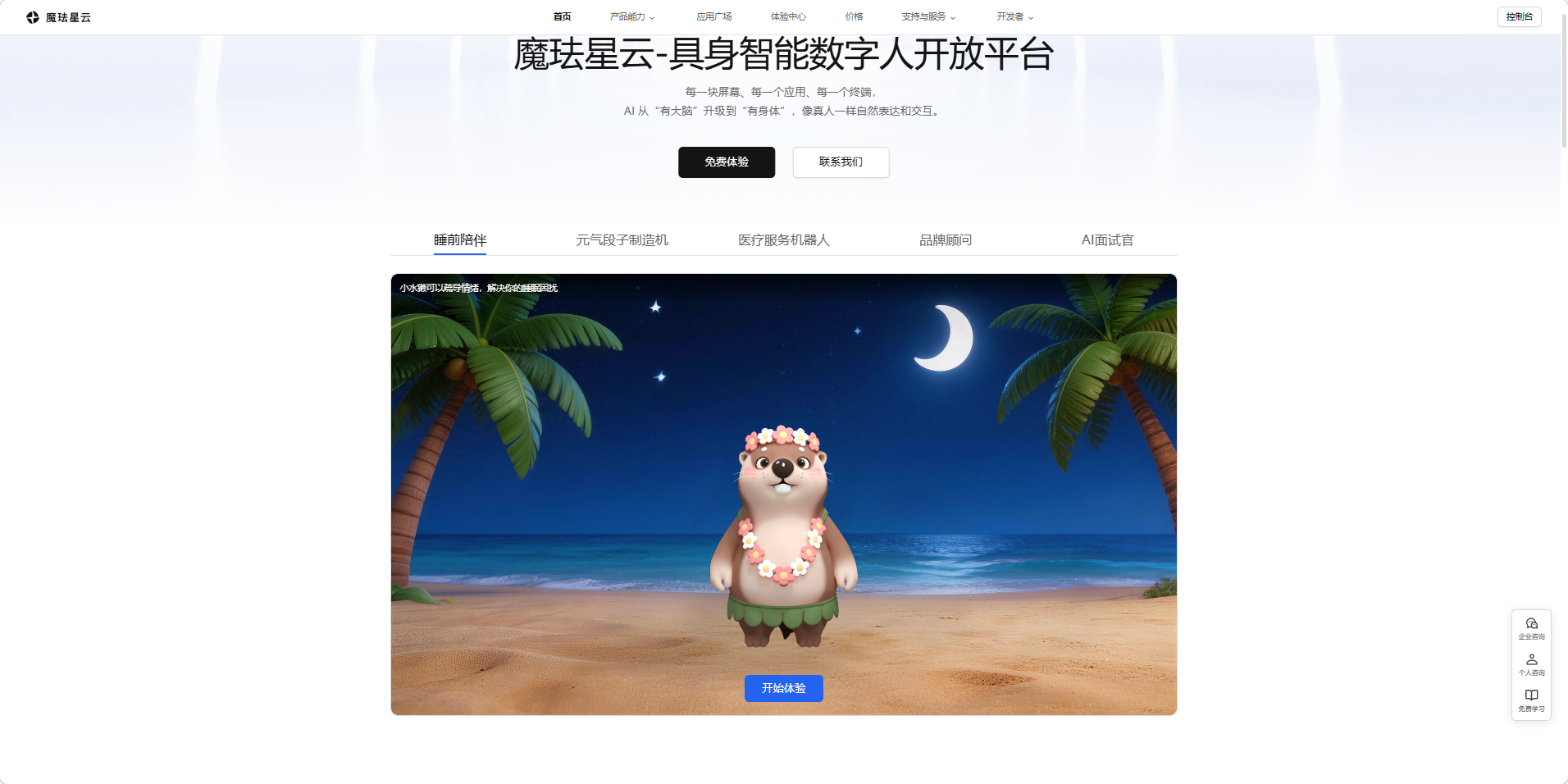
传统云端数字人虽具备实时对话交互能力,但受云端架构制约,存在延迟高、表情模板化、无法实时打断、成本高昂、并发弱、老旧终端无法适配等问题,仅适合高端演示场景,难以下沉到家用健身、社区运动、智能硬件等多元场景规模化落地。
魔珐星云依托自研AI 端渲与端侧解算核心技术,打造具身智能数字人开放平台,实现与传统方案的底层代差:云端仅下发几十 KB 轻量级驱动指令,终端本地完成实时渲染,端到端响应低至 500ms,支持实时打断、语音‑表情‑动作完整联动、情绪动态共情;同时具备低成本、高并发、全终端兼容、SDK 轻量化快速接入优势,可快速落地家用 APP、智能硬件、社区健身终端、线下场馆等多场景,实现从演示产品到普惠式商用健身私教的升级。
传统实时渲染数字人与星云数字人技术方案对比
表格
表格 还在加载中,请等待加载完成后再尝试复制
星云核心技术思路为AI 端渲与端侧解算:依托自研文生 3D 多模态大模型,数字人基础动画碎片预先下载至本地;对话过程中,云端仅传输几十 KB 的口型、表情、动作轻量级驱动指令,由本地 SDK 实时合成完整 3D 交互画面。彻底绕开传统云端方案整帧视频传输的高延迟、高成本、低并发痛点,将端到端对话响应从 3‑5 秒压缩至 500ms 左右,真正落地多场景普惠式智能健身私教。
点击官网抢先体验:https://xingyun3d.com/
四、从零搭建:智能健身私教完整方案
下面我用星云SDK(JS版本)实际搭建一个可运行的智能健身顾问。
准备工作
星云官网注册账号(https://xingyun3d.com/)
创建应用驱动并保存 App ID 和 App Secret,这是后续接入SDK的唯一凭证
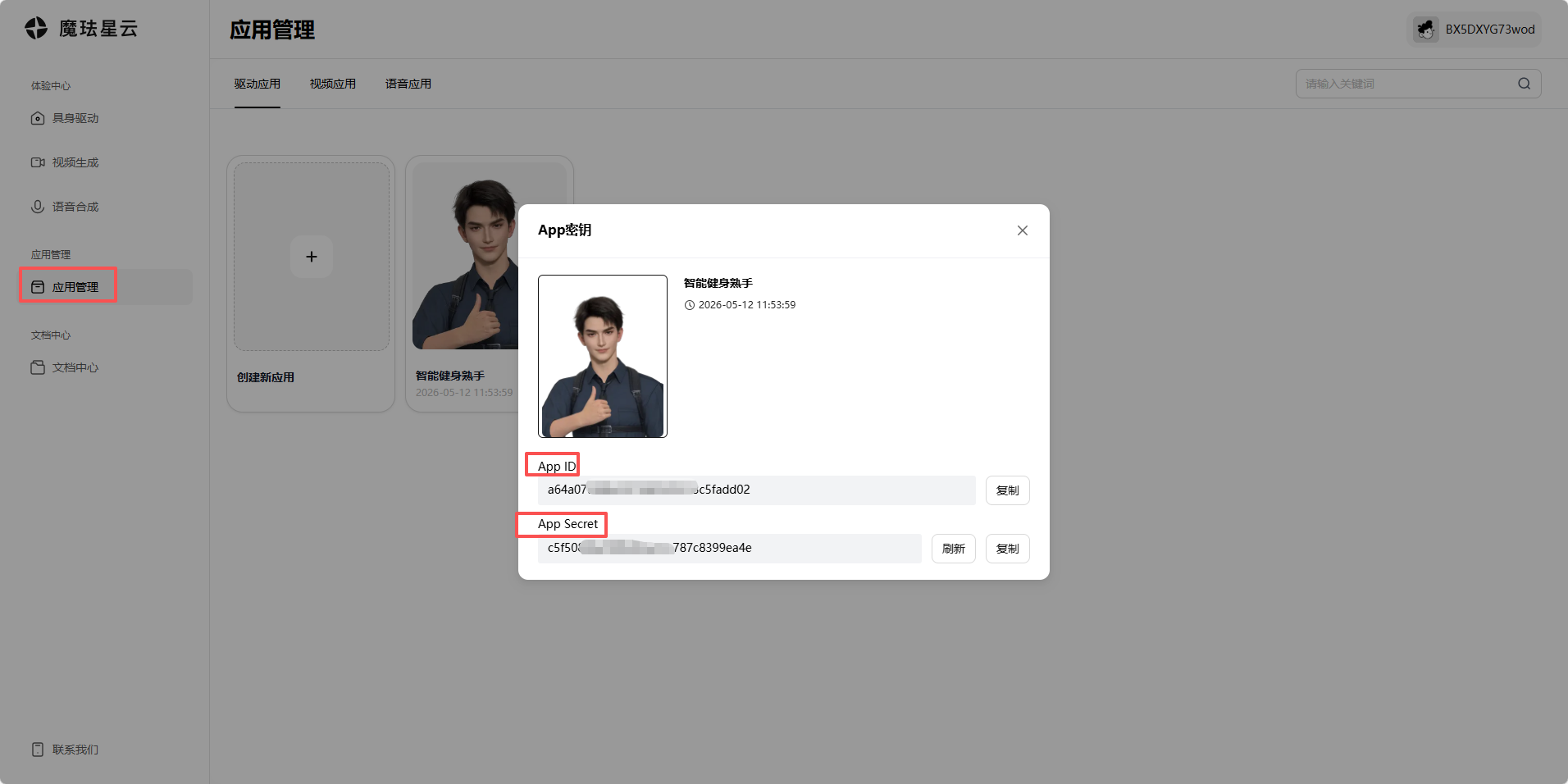
文本大模型APIKey获取
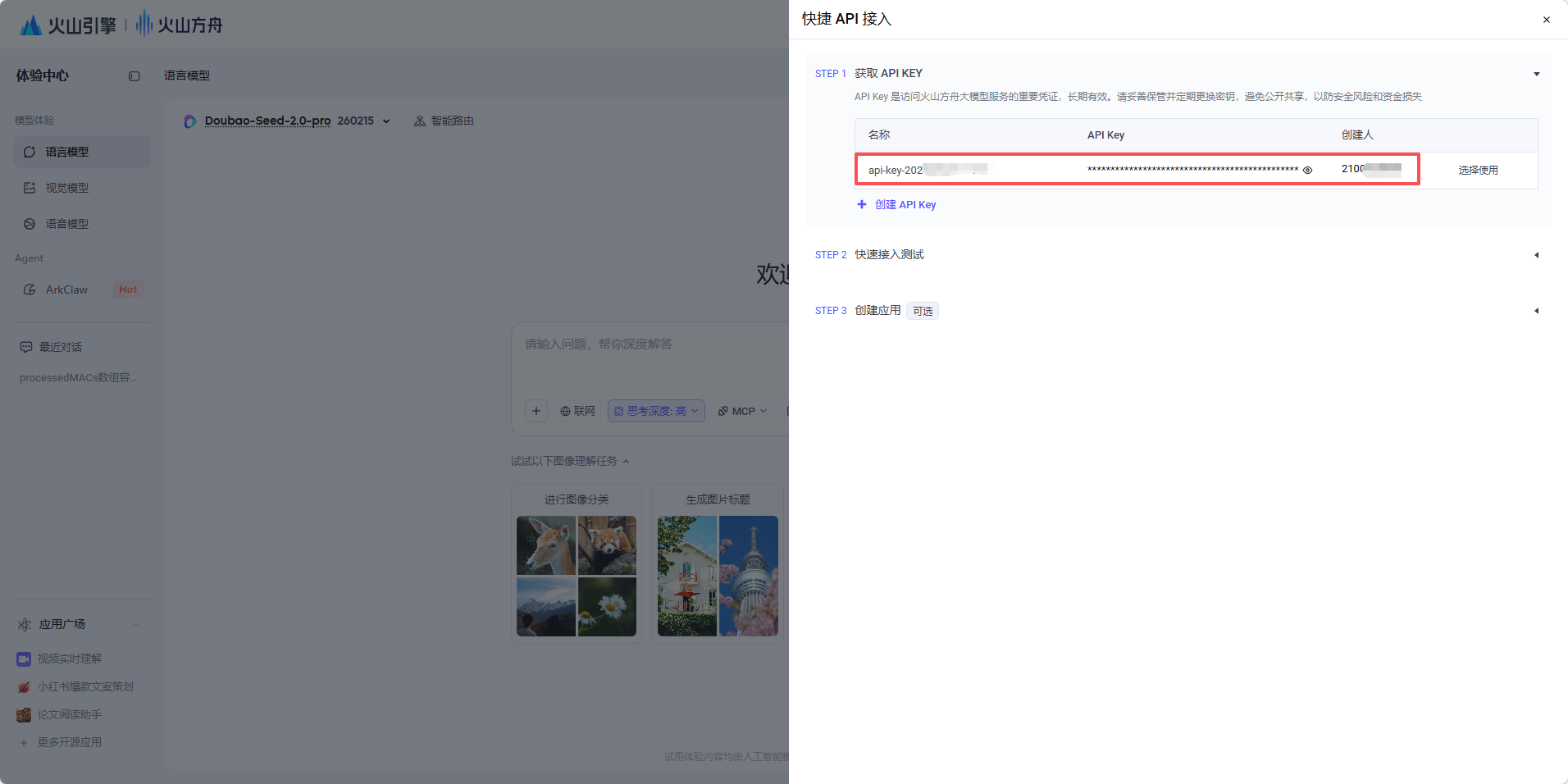
ASR服务商,我选的是讯飞
4.1 项目结构
暂时无法在飞书文档外展示此内容
4.2 核心服务:AvatarService 封装
数字人的所有交互都围绕 XmovAvatar 实例展开。我将它封装成一个单例服务:
暂时无法在飞书文档外展示此内容
4.3 健身逻辑服务
暂时无法在飞书文档外展示此内容
4.4 前端界面
暂时无法在飞书文档外展示此内容
4.5 数字人组件
暂时无法在飞书文档外展示此内容
4.6 运行
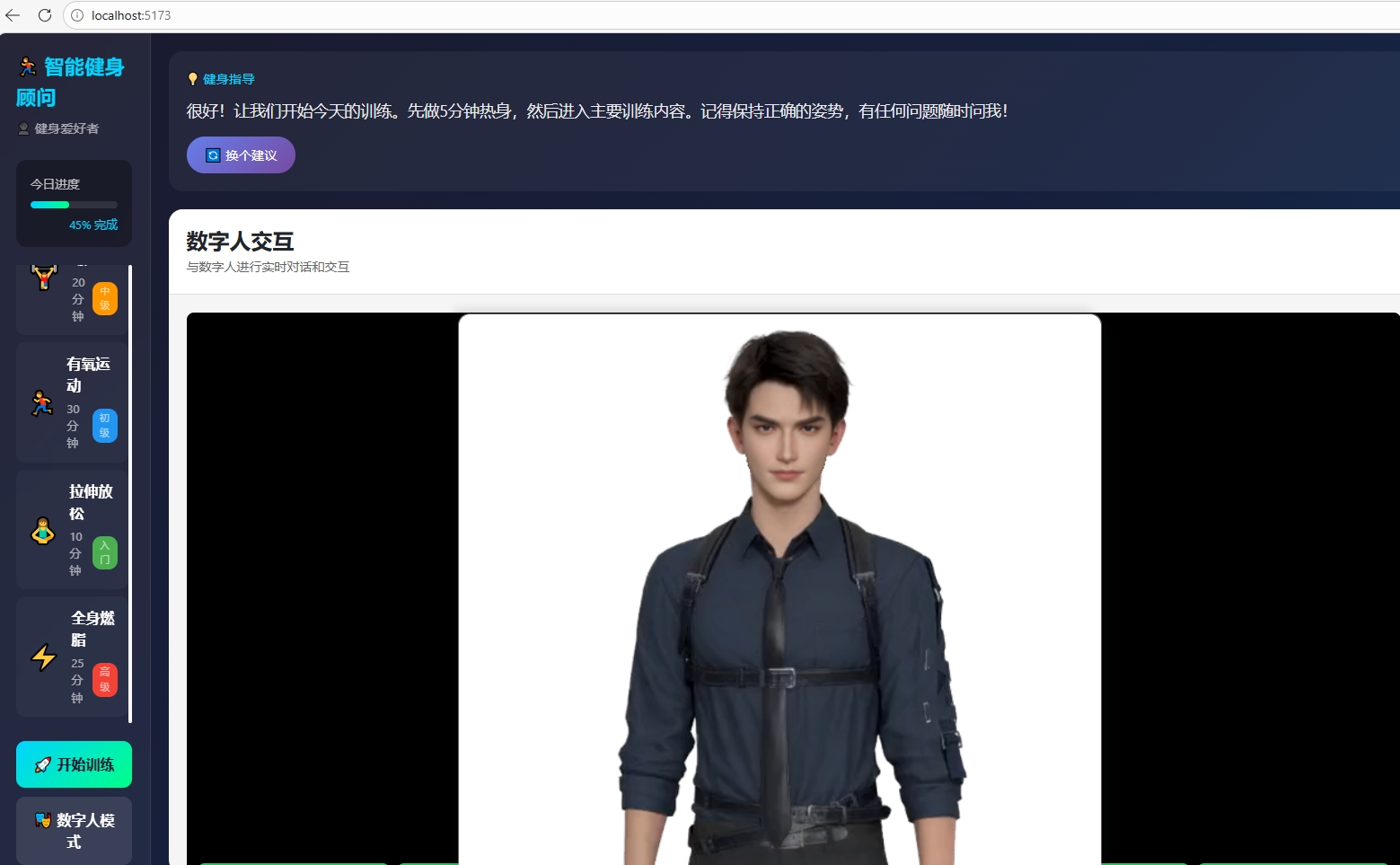
打开浏览器访问,点击「初始化数字人」按钮。等待3D资源加载完成后(首次大约10-20秒),你就能看到一个活灵活现的数字人出现在页面上了。
在输入框输入文本,点击「让TA说」——数字人会用选定的音色开口说话,口型、表情、手势全部实时生成。
五、关键技术解析
5.1 流式对话:边生成边说话
这是数字人健身私教最核心的能力。大模型的输出是流式的(比如豆包、通义千问),用户不需要等它全部生成完再说出来。
暂时无法在飞书文档外展示此内容
关键规则:
- 第一段:
is_start = true - 最后一段:
is_end = true - 两段 speak 之间必须用
interactiveIdle()或listen()做状态切换(这里的"两段 speak"指的是两件不相关的事,不是流式输出的多个 chunk。)
正确理解:is_start / is_end 是针对「一次对话轮次」的
一次完整的数字人说话,内部可以分成多个 speak() 调用(比如流式输出时每个 chunk 调一次),但这一整个轮次只需要一组 is_start=true 和 is_end=true。
暂时无法在飞书文档外展示此内容
核心原则:同一轮回答的多个 chunk 是一个原子操作,中间不能被状态切换打断;只有两轮回答之间才需要状态隔离。
5.2 健身状态机设计
数字人在健身场景中的状态流转:
暂时无法在飞书文档外展示此内容
这个状态机保证了数字人的行为是"有目的"的,不是随机执行动画。
5.3 SSML 动作标记:让数字人做健身动作
星云的 SSML 支持在说话时触发预设动作(KA,Key Action),可以让数字人在演示健身动作时更生动:
暂时无法在飞书文档外展示此内容
通过 action_semantic 可以查询当前数字人角色支持的所有动作列表。首次加载时动作素材会从CDN下载(每个约100KB),后续直接走本地缓存。
六、踩坑记录整理
坑1:容器宽高必须明确指定
现象: init 成功,控制台无报错,但页面一片空白。
原因: SDK 内部用容器的 offsetWidth 和 offsetHeight 创建画布。用 flex 或 `height: auto` 初始化时都是 0。
解决:
暂时无法在飞书文档外展示此内容
坑2:只能 localhost 或 HTTPS 下运行
现象: 用局域网IP访问(如 `192.168.1.100:5173`),SDK 报错。
原因: SDK 用了麦克风、WebGL 等受限制的浏览器API,这些只在安全上下文(localhost/HTTPS)下可用。
解决: 开发用 localhost,部署必须上 HTTPS。可以用 ngrok 做本地映射测试。
坑3:健身数据没有持久化
现象: 刷新页面后,今天的训练数据全没了。
原因: 数据都在内存里(ref),没做本地存储。
解决: 加一个 localStorage 持久化:
暂时无法在飞书文档外展示此内容
七、总结:这套方案的真实体验
用了两周搭完这个系统,说说我的感受:
真正打动我的地方:
- 1秒响应:实测从用户选择训练项目到数字人开始说话,稳定在 900-1100ms。对比视频跟练 App 的"无人感",这个体验是质变。
- 有温度的交互:数字人会在你完成训练后说"太棒了",会在你想偷懒时说"再坚持一下"。这种即时反馈是纯文字或视频给不了的。
- 端侧渲染,成本可控:不需要为每个用户配备 GPU 服务器,素材缓存后复用,大规模部署的可行性很高。
需要注意的地方:
- 首次加载 10-20 秒,需要加 loading 引导
- 动作演示和语音的时序对齐需要手动调
- 数据持久化要自己做,SDK 不提供
- HTTPS 是硬性要求,调试环境要注意
适合的场景 vs 不适合的场景:
|
✅ 强烈推荐 |
⚠️ 需要评估 |
|
健身房/企业健康终端 |
纯App(用户可能更习惯纯文字) |
|
家庭智能健身(接电视/平板) |
低性能设备(端侧渲染有要求) |
|
线下展会/品牌体验 |
网络不稳定环境 |
|
AI私教一对一场景 |
需要精确动作纠正的场景(需要额外骨骼检测) |
如果你想做一个"真正能陪你练"的数字人教练,而不是一个"仅能执行预制动画的单向展示工具",星云 SDK + 健身业务逻辑的这套组合是目前我看到最可行的方案。它把最难的部分(数字人渲染、表情联动、实时响应)替你解决了,你只需要专注健身业务的体验设计。

电影级数字人,免显卡端渲染SDK,十行代码即可调用,工业级demo免费开源下载!
更多推荐
 4
4 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)