
一起读《大模型驱动的具身智能:架构、设计与实现》- 分层动作级规划
摘要:视频分享了分层动作级规划在具身智能中的应用,重点介绍了动作原语(motion primitive)作为基本动作模块的作用及其组合形成技能的过程。内容涵盖GPTR、CaP等基于大模型的规划方法,分析了现有技术在多模态感知、实时性和泛化性方面的局限性。同时介绍了CoPa等分层架构如何结合大模型推理与轨迹优化,通过粗到细的部件定位机制实现精准操作。视频还讨论了任务导向抓取和运动规划的具体实现方法,

视频分享
【一起读《大模型驱动的具身智能:架构、设计与实现》- 分层动作级规划】 「链接」
分层动作级规划中,环境感知和动作规划往往是分开的,有利于将已有的先验知识作为额外的约束或推理条件,让模型可以做出更合理的决策。同时无需对大模型进行专门的训练,具有较高的性价比。
动作原语
motion primitive,指预定义的、可重复使用的基本动作或行为模块。
- 可以在很多机械臂的SDK看到类似的API接口或者定义,类似夹爪开、夹爪关、moveJ等都可以是动作原语,是一种基元级的离散化实现,提供了一组有限且实用的动作。(可预测、不针对特定场景、一定程度不可拆分)
- 动作原语是多个低级动作的组合,单个低级动作如关节位置控制是无法完成有意义的任务
多个动作原语按照一定的序列组合,可以固定成"技能"。
- 有点像目前的Agent功能,如Claude code中如果经常会进行的操作连招,我们往往会写一个SKILL.md
- 技能虽然比原语更高级,但确定的序列导致泛化性降低
基于技能的单步动作级规划
GPTR,使用基础的LLM(无需微调)对任务进行理解,在给定的技能动作空间中进行动作级规划。
[2306.17582] ChatGPT for Robotics: Design Principles and Model Abilitiescontact arXivsubscribe to arXiv mailings
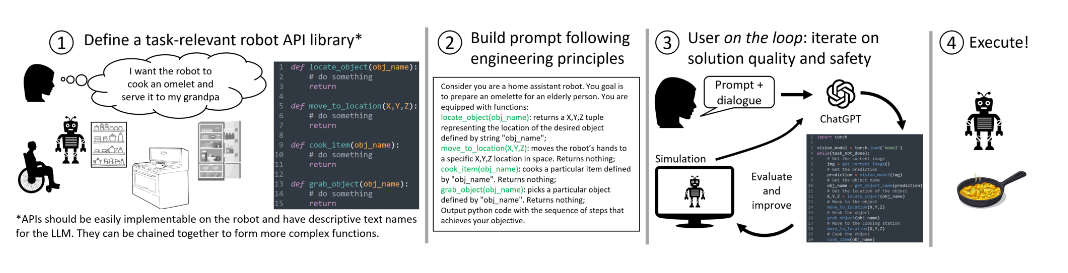
- 环节2中的提示词不仅描述了任务的目标,还明确的指出可以使用的高级API库函数,最后通过 LLM 将任务转化为实际具体的控制代码
- 缺少多模态感知和信息实时性差,会导致规划滞后;由于仅仅根据目标描述,缺少对全局环境和潜在可能,试错多会导致效率低;通过技能库进行限定的组合泛化程度低,同时也限制了系统和机器人的灵活性
基于动作原语的直接动作级规划
CaP(Code as Polices)代码即策略。
[2209.07753] Code as Policies: Language Model Programs for Embodied Controlcontact arXivsubscribe to arXiv mailings
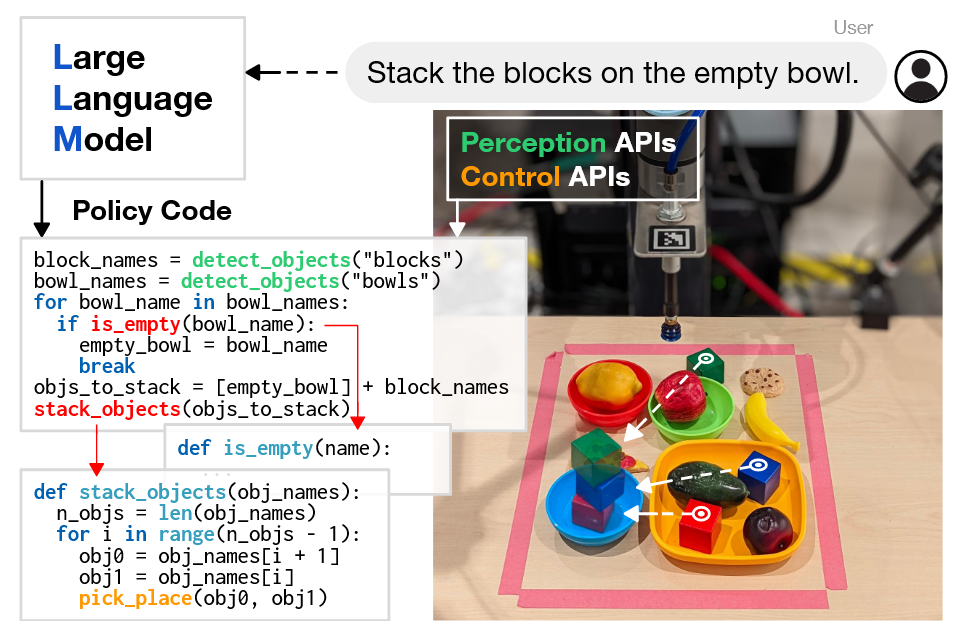
- 直接根据动作原语加上if else或者任务分解逻辑输出控制代码。
- 任务拆解依赖于人工先验只是以及预先设计的Prompt和示例(这也是弊端)
基于空间位置约束的动作级分层规划
将大模型的常识推理与机器人领域的轨迹优化。CoPa,分层架构。
[2403.08248] CoPa: General Robotic Manipulation through Spatial Constraints of Parts with Foundation Models
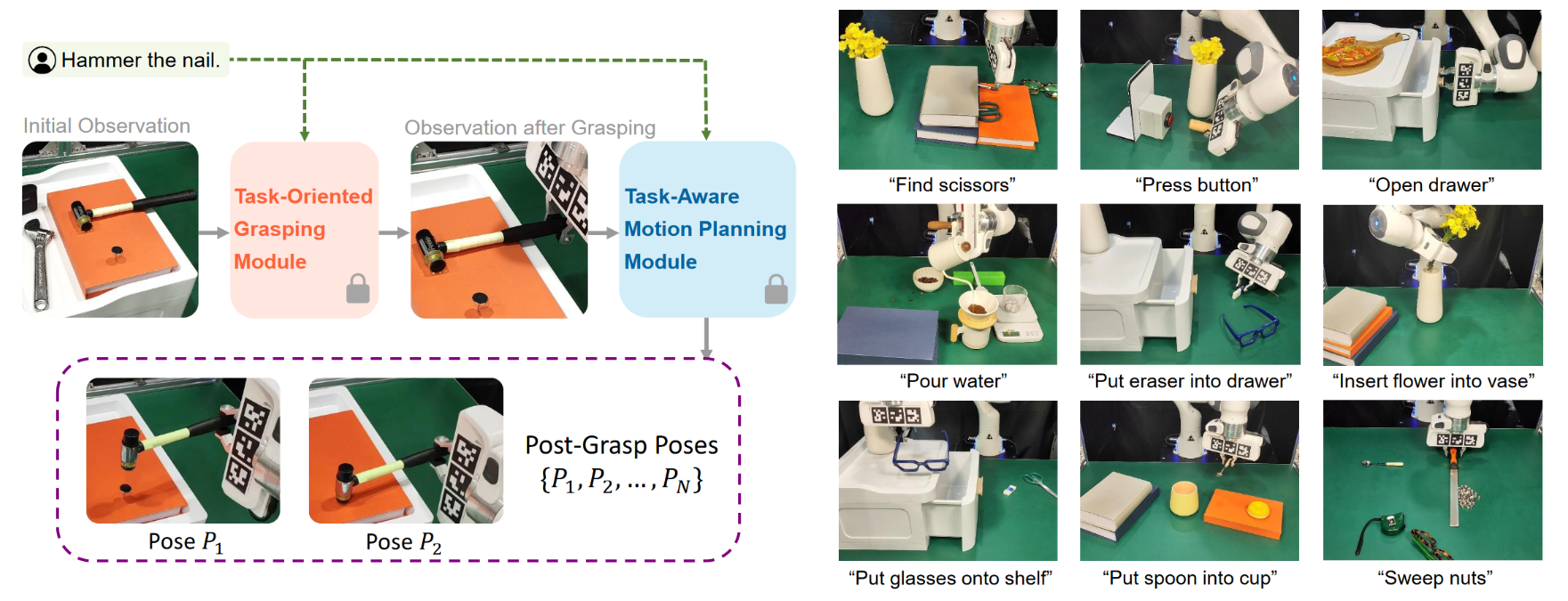
- 任务导向抓取、任务感知运动规划两大模块,从粗到细的部件定位机制(Coarse‑to‑Fine Grounding),结合 SoM(Set‑of‑Mark)实现物体部件精准识别
- 任务导向抓取阶段:先用分割模型粗定位目标物体,再用 GPT‑4V 细粒度识别任务相关抓取部位,结合 GraspNet 匹配抓取接触点,输出符合任务要求的抓取位姿
- 任务感知运动规划阶段:再次调用 VLM,识别物体部件的空间几何约束,推导抓取后物体 / 末端执行器的目标位姿;可直接对接现有机器人规划算法,完成长时序复杂操作

电影级数字人,免显卡端渲染SDK,十行代码即可调用,工业级demo免费开源下载!
更多推荐



 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)