
Sim2Real Gap 让机器人性能掉 60%:为什么如视的真实空间数据开始变得关键?
摘要:Sim2Real差距是机器人从仿真环境迁移到真实场景时性能下降20%-60%的关键问题。具身智能需要融合几何、视觉和语义的三维空间数据来支撑感知、决策和执行全流程。如视Realsee3D数据集包含1万室内场景、29万组RGB-D数据及多维标注,通过真实场景与合成数据结合的方式,为机器人训练提供包含深度、位姿、结构等关键信息的空间底座。该数据集对解决长尾环境下的避障、路径规划等问题具有重要价值
很多做机器人或具身智能的同学应该都遇到过类似问题:模型在仿真环境里跑得不错,一上真实场景就开始掉性能,甚至直接失效。
行业里通常把这个问题叫 Sim2Real gap。简单说,就是智能体在虚拟环境中学到的策略,迁移到真实世界后效果会打折。在具身智能任务里,Sim2Real gap 往往会带来 20%–60% 的真实性能损失。

如果任务涉及大量接触动作、长尾环境,或者强依赖物理细节,比如抓取、避障、穿行、巡检,性能损失可能会扩大到 50% 以上。更严重的情况是:仿真里能跑通的策略,放到真实环境里完全不可用。
原因也不复杂。机器人不是在二维图片里工作,而是在真实房间、真实工厂、真实走廊里移动、感知和执行。
一张图片可以告诉模型“这里有一张桌子”,但它很难回答下面这些问题:
- 桌子离墙有多远?
- 机器人能不能从桌子旁边通过?
- 桌面高度是多少?
- 物体在三维空间中的坐标在哪里?
- 房间布局变化后,原来的路径规划是否还成立?
这就是具身智能和传统视觉识别的差别。传统视觉任务主要回答“这是什么”。具身智能还需要回答:
- 它在哪里?
- 尺寸是多少?
- 能不能通过?
- 下一步怎么走?
- 执行后会不会碰撞?
笔者认为,这也是最近一年机器人、空间智能、三维重建被频繁讨论的原因之一。模型要进入真实世界,仅靠互联网图片远远不够。真正稀缺的是带有尺度、结构和语义信息的三维空间数据。
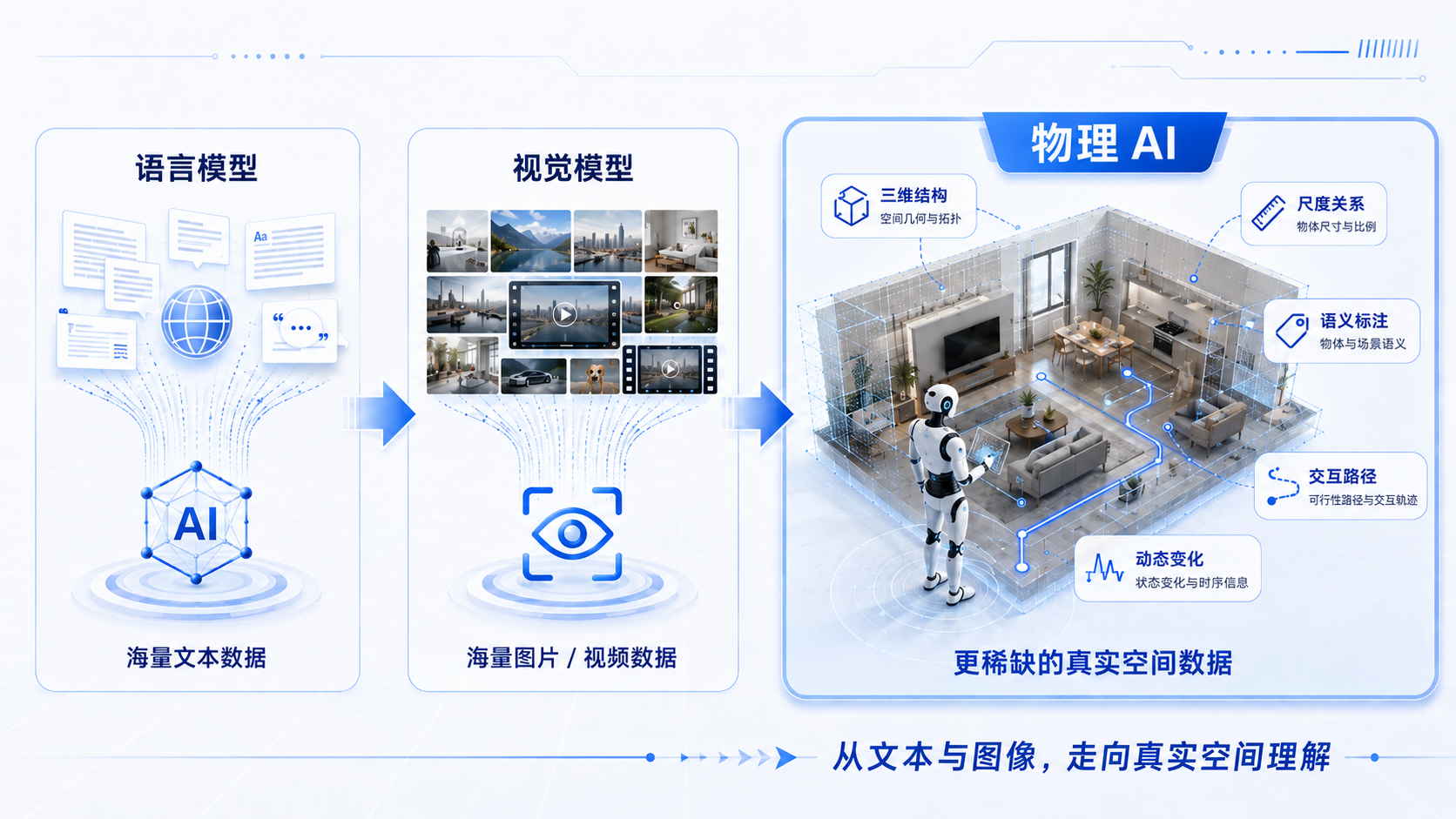
具身智能训练需要什么样的数据?
具身智能需要的不是“更清晰的图片”,而是能够参与计算、验证和决策的真实空间数据。从训练流程看,一个机器人系统通常需要经历以下环节:
`text
真实空间采集
↓
三维重建 / 深度估计 / 位姿估计
↓
语义理解 / 物体检测 / 空间拓扑分析
↓
仿真训练 / 策略验证 / 路径规划
↓
真实环境部署
↓
反馈数据回流
`这两年,行业对具身智能训练场的关注明显增加。相关市场规模有机会达到数百亿。比较确定的是,这个市场会随着机器人训练、自动巡检、室内导航、智能制造、商业空间运营等需求一起增长。
底层逻辑很直接:真实空间数据越多,模型训练和验证成本越低,落地阶段出现异常的概率也更容易被压下来。
为什么如视的真实空间数据这么关键?
具身智能系统一般包括五个核心环节:
- 感知
- 理解
- 决策
- 行动
- 反馈
只要智能体进入真实环境,空间误差就会直接影响结果。对机器人来说,几厘米的偏差可能意味着撞到桌角,也可能导致一次抓取失败。
仿真环境当然有优势:
- 成本低
- 安全
- 可重复
- 方便大规模试错
但问题在于,仿真空间和真实空间经常存在明显差异。模型在虚拟环境里学到的策略,到了现实环境中不一定有效。这也是 Real2Sim 和 Sim2Real 一直被反复讨论的原因。
更稳妥的路径是:
`text
真实环境 → 数字化建模 → 仿真训练与验证 → 回到真实环境执行
`要让这条路径跑通,三维数据至少需要包含三类信息。少掉任何一类信息,机器人对空间的理解都会不完整。比如室内巡检机器人,不能只知道“前面有门”。它还需要知道:
- 门的具体位置
- 门的宽度
- 门附近是否有障碍物
- 当前机身宽度能否通过
- 是否需要重新规划路径
这类数据的商业价值正在变得更清楚。机器人、自动巡检、室内导航、智能制造、商业空间运营,本质上都需要一个更准确的空间底座。
谁能以更低成本、更高精度、更大规模获取真实空间数据,谁就更容易在具身智能基础设施层建立优势。
如视Realsee3D:不是图片库,而是目前最大的三维空间数据集
说到真实空间数据,如视 Realsee 是一个值得关注的样本。

如视在 2025 年 12 月公开了 Realsee3D。官方页面显示,这个数据集包含:
- 10000 个室内三维场景
- 95962 个细分房间单元
- 299073 组视点 / RGB-D 图像对
这个规模不算小。更关键的是,它不是简单堆图片,而是围绕室内空间重建和具身智能训练来组织数据。
数据字段说明
Realsee3D 公开的数据类型包括:

很多人容易低估这些字段的作用。机器人识别出“椅子”“门”“桌子”,只是第一步。真正难的是后续空间判断:
- 椅子是否挡路?
- 门洞是否足够通过?
- 桌子旁边有没有转身空间?
- 物体在机器人坐标系中的位置是否准确?
- 当前路径是否存在碰撞风险?
这些问题都离不开真实三维空间数据。从应用角度看,数据字段越完整,可支持的任务就越多。
如果只有视觉图像,价值更多停留在展示和识别层面。一旦同时具备深度、位姿、结构和语义信息,就可以进入机器人训练、路径规划、空间分析、资产管理等更复杂的场景。
只靠合成数据不够,真实世界太复杂
公开信息显示,Realsee3D 采用的是“真实数据 + 程序化生成”的组合策略。其中包括:
- 1000 个真实场景
- 9000 个合成场景
笔者认为,这种组合比较符合实际工程需求。合成场景的优势很明显:
- 扩展速度快
- 成本相对可控
- 可以覆盖更多户型、布局和风格
- 标注生成更方便
真实场景的价值在于,它保留了现实环境中那些不规则、难建模、甚至有点“脏”的细节。
比如:
- 复杂光照
- 生活痕迹
- 家具遮挡
- 临时堆放物品
- 不规则边角空间
- 玻璃、镜面等反射材质
- 狭长通道
- 被移动过的设备和家具
机器人真正进入的环境,很少是干净整齐的样板间。门口可能放着快递,走廊里可能多了一把椅子,设备位置可能被人挪过。玻璃、镜面、狭长通道,也都会增加空间感知和三维重建难度。
如果只用合成数据训练,模型很容易在真实环境里遇到“没见过”的情况。所以,数据规模重要,真实性也同样重要。
训练数据越接近真实环境,模型越有机会学到可落地的能力。对开发者和技术团队来说,评估一个空间智能数据集时,不能只看样本数量,还要看真实场景占比、字段完整性、标注质量和空间尺度是否可靠。
如视在这方面有一定数据积累。公开资料显示,如视拥有 5800 万+空间数据,覆盖 46 亿平方米。这类长期沉淀的真实空间数据,不只是内容库,也可以作为训练和验证空间模型的底层资源。
FAQ
什么是 RGB-D 数据?
RGB-D 数据同时包含彩色图像和深度信息。其中:
- RGB:记录颜色、纹理、外观等视觉信息
- D:记录深度信息,也就是像素点到相机的距离
RGB-D 数据常用于三维重建、机器人导航、避障、场景理解等任务。
具身智能训练为什么需要相机位姿?
相机位姿用于描述拍摄位置和方向,通常可以表示为一个 4x4 的变换矩阵。多个视角的数据只有完成位姿对齐,才能组合成一致的三维空间。后续的定位、导航、路径规划、语义融合都依赖这个基础。
Realsee3D 是否可以直接用于商业项目?
如视官网表述为面向学术研究及非商业用途开放。如果要用于商业项目,建议先确认授权条款。
总结
Sim2Real gap 的核心问题,是仿真环境和真实环境之间存在差异。在具身智能场景中,这种差异会直接影响机器人感知、导航、避障和操作效果,性能损失可能达到 20%–60%,复杂任务中甚至超过 50%。
真实空间数据的价值正在上升,原因在于它同时承载了几何、视觉和语义信息。对于机器人训练来说,这些数据不是展示素材,而是模型理解世界、验证策略和执行动作的基础。
如视Realsee3D 提供了 10000 个室内三维场景、95962 个细分房间单元、299073 组视点 / RGB-D 图像对,并包含彩色全景图、深度图、位姿、CAD 图纸、户型平面图、语义分割标签和 3D 物体检测标签等字段。对具身智能、三维重建和空间理解方向的开发者来说,这类数据集值得持续关注。
关键词
具身智能数据集、机器人训练数据、RGB-D、相机位姿、语义分割、3D 物体检测、Real2Sim、Sim2Real、Realsee3D、Argus1.0

电影级数字人,免显卡端渲染SDK,十行代码即可调用,工业级demo免费开源下载!
更多推荐

 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)