
WLA:当机器人同时学会“看世界“和“说人话“,具身智能迎来统一范式
上海交通大学YiYang团队提出具身智能基础模型WLA(World-Language-Action),首次将世界建模、语言推理和动作生成统一到单一自回归Transformer中。该模型通过双专家机制(世界专家+动作专家)实现物理理解到动作决策的端到端融合,创新性地采用元查询机制支持速度与精度的动态权衡。仅20亿参数的WLA-0原型在RoboTwin2.0Clean基准上取得92.94%成功率,延迟

导读
想象一下,你让一个机器人完成"把桌上的杯子放进洗碗机"这个任务。它不仅需要理解你的语言指令(语言推理),还得预判杯子滑落时的物理轨迹(世界建模),最终精准地完成抓取和放置动作(动作生成)。然而在现有的技术方案中,这三种能力被割裂在不同的模型范式里,就像一个人必须用三个独立的大脑来思考同一件事。
2026 年 6 月,来自上海交通大学的 Yi Yang 等人提出了一种全新的具身基础模型 ------ WLA(World-Language-Action,世界-语言-动作模型)。这个名字本身就揭示了它的野心:将世界建模、语言推理和动作合成三条曾经各走各路的技术路线,焊死在同一个自回归 Transformer 里。其原型 WLA-0 仅用 20 亿激活参数,就在 RoboTwin2.0 Clean 基准上拿下 92.94% 的成功率,推理延迟低至 40 毫秒,且展示了从无动作标注的跨具身视频中学习新技能的惊人潜力。
这不是又一篇刷榜论文,而是一次范式级别的架构重构 ------ 它试图回答具身智能领域最根本的问题:我们能否用一个统一的框架,让机器人既理解物理世界的运行规则,又掌握人类语言的推理逻辑?
背景与动机
具身智能基础模型(Embodied Foundation Models)近年来沿着两条主线快速发展,但二者之间存在一道难以逾越的鸿沟。
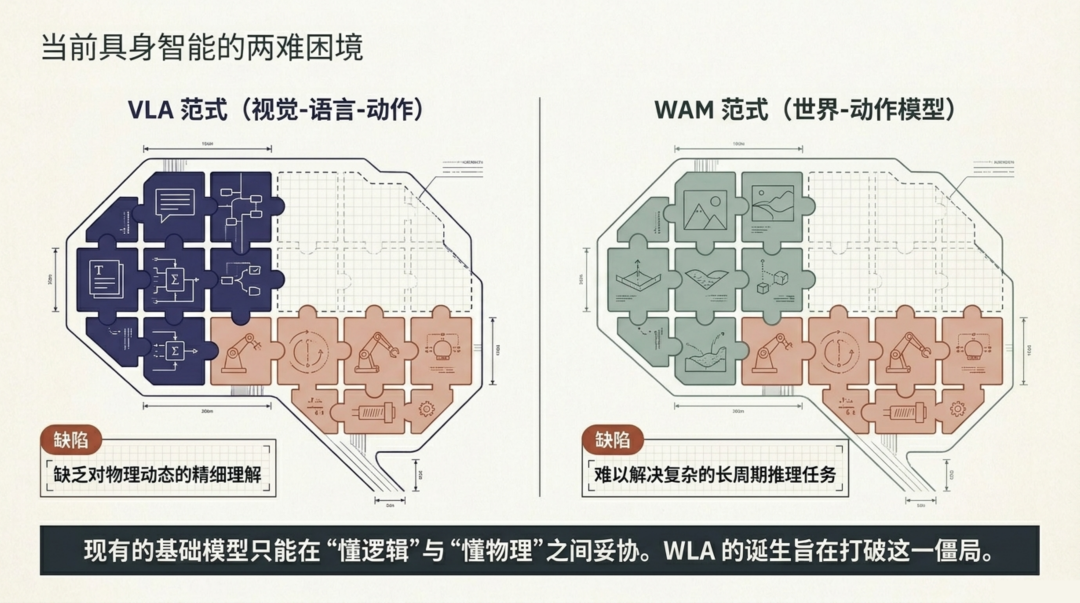
第一条路线是 VLA(视觉-语言-动作)模型。 它们继承了大语言模型强大的推理能力,擅长理解复杂的文本指令并将其分解为一连串子任务。但 VLA 模型对物理世界的"直觉"很弱 ------ 它们不太懂重力、摩擦力和碰撞,面对需要精细物理交互的场景往往力不从心。
第二条路线是 WAM(世界-动作模型)。 通过在海量第一人称视频上进行世界建模预训练,WAM 学会了预测物理环境的演变。但它们通常采用双向扩散 Transformer(Bidirectional Diffusion Transformer),计算开销大、推理延迟高,更要命的是缺乏语言推理能力,无法处理需要多步逻辑规划的长程任务。

上面这张对比表清晰地展示了问题所在:VLA 有语言推理但缺世界模型,WAM 有世界模型但缺语言推理,二者在动作关联和推理延迟上也各有短板。WLA 的目标就是打破这种"懂逻辑"与"懂物理"之间的二选一困局,成为第一个在所有维度上都达到"实心圆"(行业领先)的统一范式。
核心方法
多模态联合预测:输入一切,输出一切
WLA 的设计哲学可以用一句话概括:让模型在同一个前向传播中,同时完成"想什么"(语义规划)、"看到什么"(视觉预测)和"做什么"(动作生成)。
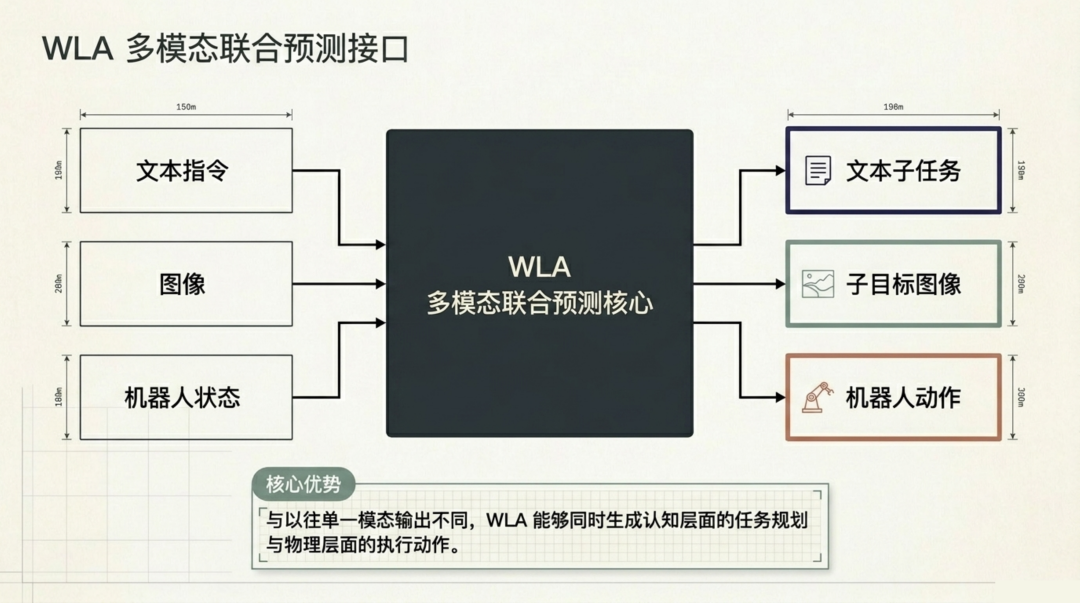
具体而言,WLA 接收三种输入 ------ 文本指令、当前图像和机器人本体状态,然后联合输出三种预测:
-
文本子任务:将复杂指令分解为语义层面的步骤规划(比如"先打开洗碗机门 -> 再把杯子放进去")
-
子目标图像:预测执行下一步后环境应该变成什么样,相当于机器人的"想象力"
-
机器人动作:生成实际的关节控制信号
这种三路并行的输出设计是 WLA 与前代模型的根本区别。传统 VLA 只输出动作序列,缺乏对物理环境变化的预见;传统 WAM 只预测视觉未来,不直接生成可执行动作。WLA 将认知层面的任务规划与物理层面的执行动作在同一个模型内实现了闭环。
自回归 Transformer:告别扩散,拥抱速度
WLA 在架构选择上做了一个大胆的决定:抛弃 WAM 常用的双向扩散 Transformer,转而采用自回归(Autoregressive, AR)Transformer 作为主干网络。
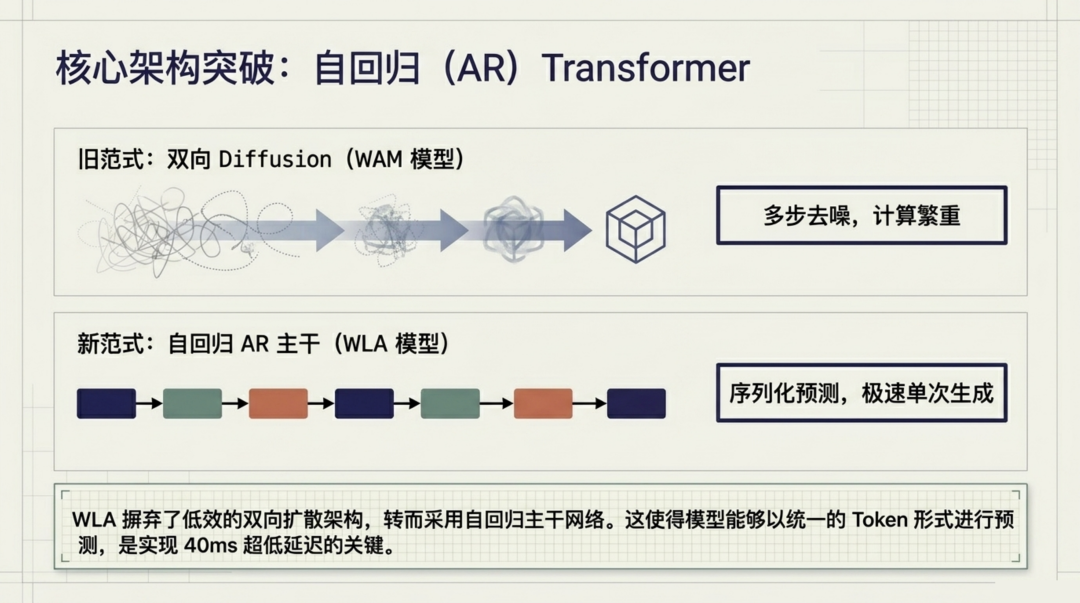
这个决定的意义远不止于速度提升。双向扩散模型需要多步去噪才能生成一个预测,而 AR Transformer 将所有模态 ------ 文本、图像 token、状态 token、动作 token ------ 统一编码为一条序列,通过单次前向传播完成预测。这使得 WLA-0 在 NVIDIA RTX 5090 上实现了 40 毫秒的单次推理延迟,完全满足机器人实时控制的需求。
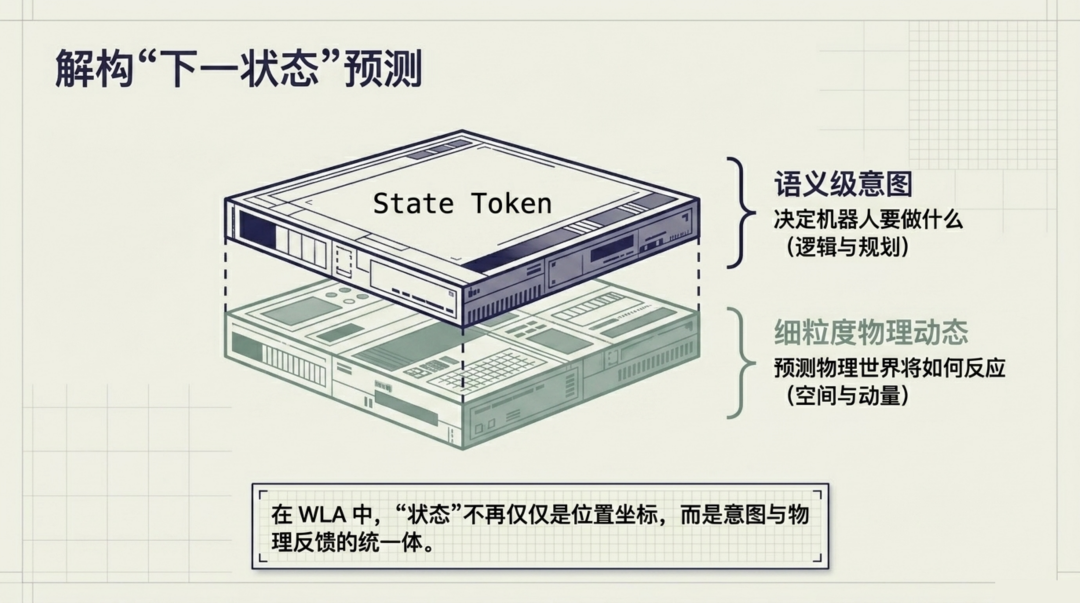
更深层的意义在于,AR 架构为多模态融合提供了天然的序列化框架。在 WLA 中,"下一状态"的概念被重新定义:它不再是简单的位置坐标,而是由语义级意图(文本子任务)和细粒度物理动态(子目标图像中编码的空间与动量信息)共同组成的复合状态。
双专家协同:世界专家为动作专家铺路
WLA 引入了两个专门化的专家模块,形成了一套精妙的协作机制。
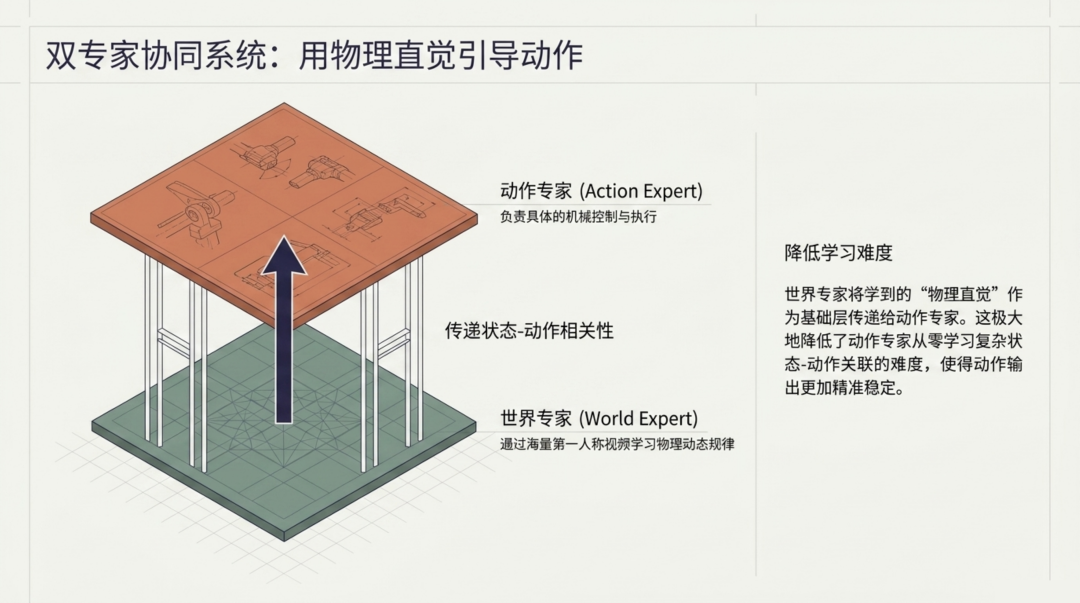
世界专家(World Expert) 从海量第一人称视频中学习物理规律,其训练目标是准确预测环境的未来状态。它不直接参与动作决策,而是扮演"物理直觉供应商"的角色 ------ 将学到的动力学特征作为基础层信息传递给上层的动作专家。
动作专家(Action Expert) 负责从当前状态到具体动作的映射。关键在于,它不需要从零开始学习复杂的"状态-动作"关联,因为世界专家已经把物理规律"嚼碎了喂给它"。这大幅降低了动作专家的学习难度,使其输出更加精准稳定。
这种设计的精妙之处在于:世界建模不再是一个独立的辅助任务,而是动作生成的上游依赖。物理理解直接服务于动作决策,二者形成了一条清晰的信息流水线。
元查询机制:在速度与精度之间自由切换
WLA 最具工程巧思的设计是元查询(Meta-Queries)机制。
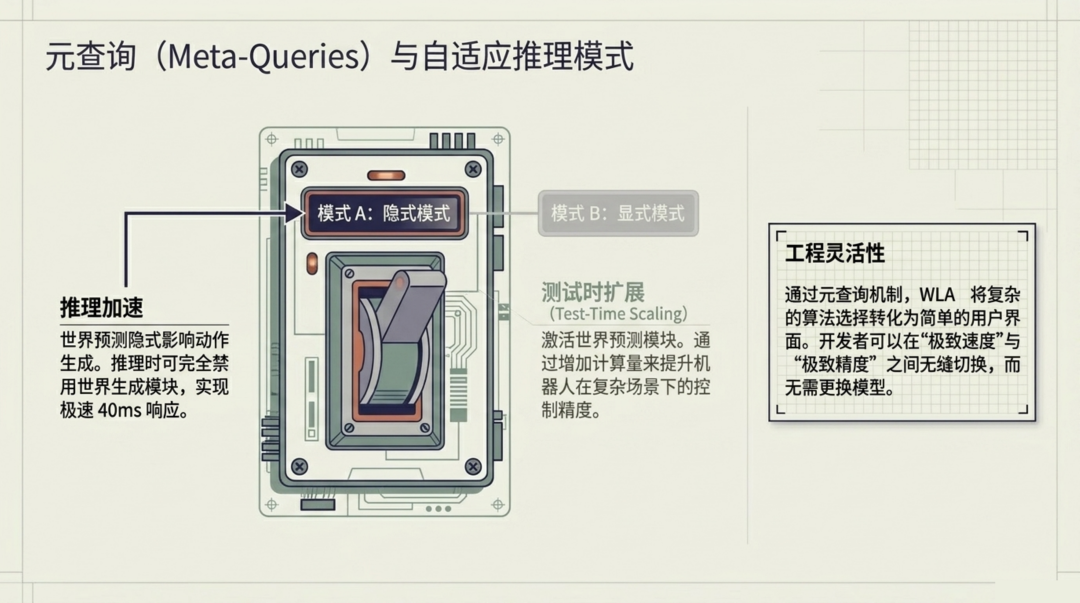
元查询使得世界预测能够以隐式方式影响动作生成。这意味着在推理阶段,开发者可以在两种模式间自由切换:
-
隐式模式(高速):完全禁用世界预测模块,仅通过元查询传递的隐式特征来指导动作生成,实现极速 40ms 推理
-
显式模式(高精度):激活世界预测模块,进行测试时扩展(Test-Time Scaling),通过增加计算量来换取更高的控制精度
这种灵活性意味着同一个模型可以适配不同的部署场景:在简单的重复性任务中追求吞吐量,在复杂的精细操作中追求成功率,而无需维护两套不同的模型。
实验与结果
WLA-0 原型以 20 亿激活参数的紧凑体量,在多个主流基准上取得了令人印象深刻的成绩。

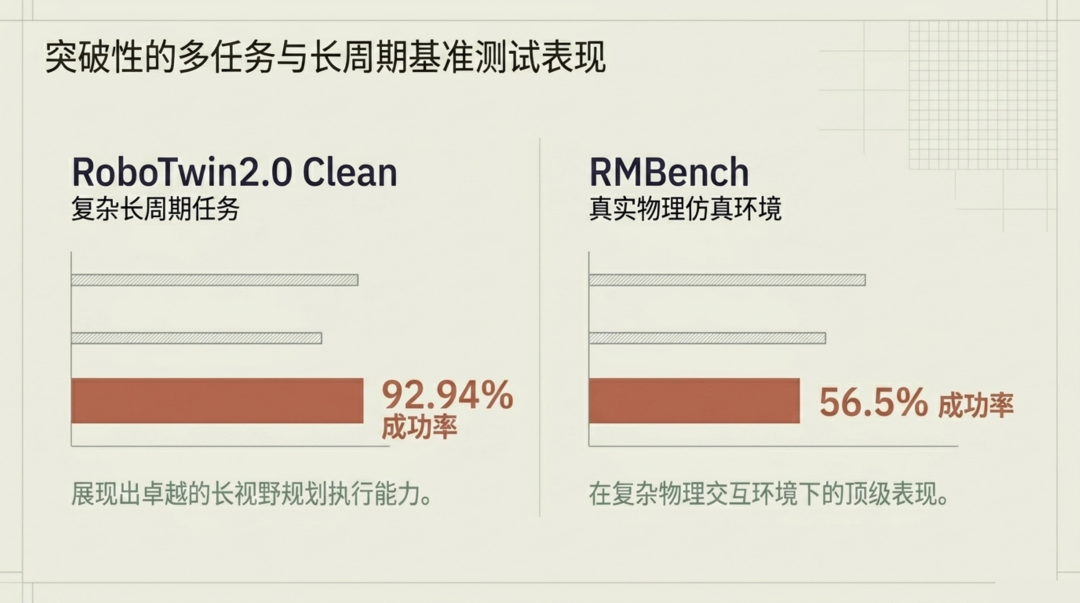
两组核心数据值得关注:
RoboTwin2.0 Clean 上的 92.94% 成功率。 这个基准测试聚焦复杂的长周期多步任务,92.94% 的成绩意味着 WLA-0 在需要多步规划和执行的场景中展现出卓越的稳定性。这个指标的含金量在于"长程" ------ 很多模型在单步任务上表现不错,但步数一多错误就会像滚雪球一样累积,WLA 通过语言推理驱动的子任务分解有效抑制了这种级联失败。
RMBench 上的 56.5% 成功率。 RMBench 是一个强调真实物理交互的仿真基准,涉及更复杂的接触力学和刚体动力学。56.5% 看似不算惊艳,但这个基准本身极具挑战性 ------ 许多现有模型在此基准上的成功率远低于此。WLA-0 在这里的表现恰恰验证了世界专家模块的价值:对物理规律的理解在精细操作任务中提供了关键的性能增益。
另一个不容忽视的指标是推理效率。2B 参数、单张 RTX 5090、40ms 延迟 ------ 这组数字标志着具身大模型向边缘部署迈出了决定性的一步。相比于动辄需要多卡集群的扩散模型方案,WLA 的实际部署成本大幅降低。
讨论与思考
真正的创新:不是拼接,而是融合
WLA 最容易被误解的地方,是把它看作"VLA + WAM 的简单拼接"。事实远非如此。关键创新在于世界专家到动作专家的特征流以及元查询的隐式影响机制 ------ 它们使得世界建模不是一个可有可无的附加模块,而是动作决策的内在组成部分。这种深度融合带来的是质变,而非量变。
跨具身学习:数据瓶颈的破局者
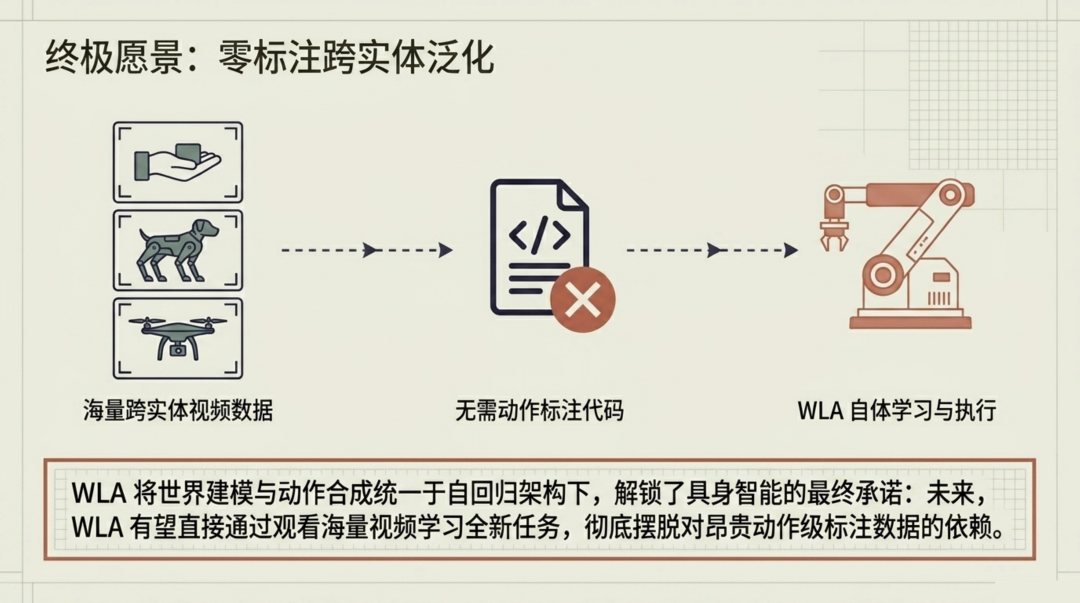
或许 WLA 论文中最具远见的部分,是关于跨具身学习(Cross-Embodiment Learning)的探索。WLA-0 展示了从没有动作标注的其他机器人视频中学习新任务的初步能力。这意味着什么?
当前具身智能最大的瓶颈不是算法,而是数据。高质量的"遥操作-动作标注"数据成本极高,而且不同机器人形态之间的数据难以复用。如果 WLA 的跨具身学习能力在后续版本中得到强化,它可能从根本上改变具身智能的数据获取范式 ------ 从依赖昂贵的遥操作数据,转向利用互联网上海量的机器人操作视频。这是一条从"精品小数据"到"野生大数据"的路径切换。
局限性与开放问题
WLA 当前的方案也有值得关注的局限。首先,论文主要在仿真和受控的真实环境中验证,尚未展示在完全开放的非结构化场景(如家庭厨房的杂乱桌面)中的泛化能力。其次,20 亿参数在边缘部署上已经很友好,但在资源更受限的嵌入式平台上是否可行仍是未知数。最后,元查询机制在速度与精度之间的权衡虽然灵活,但如何让机器人自动判断"当前场景该用哪种模式",目前似乎还需要人工设定。
从更宏观的视角看,WLA 代表了一种趋势:具身智能正在从"模块化拼装"走向"端到端统一"。正如 NLP 领域从特征工程走向预训练大模型、CV 领域从分类检测分割各建模型走向通用视觉模型,机器人领域也在经历类似的范式转换。WLA 可能不是最终的答案,但它指明了一个清晰的方向:未来的机器人基础模型,应该是一个同时理解物理、语言和动作的统一智能体。
总结
-
WLA 是首个将世界建模、语言推理和动作生成统一到单一 AR Transformer 框架中的具身基础模型,打破了 VLA 与 WAM 之间的范式壁垒。
-
双专家机制(世界专家 + 动作专家)实现了物理理解到动作决策的端到端信息流,而非简单的多任务学习。
-
元查询机制提供了推理时的速度-精度弹性,同一模型可适配从实时控制到复杂精细操作的不同场景。
-
WLA-0 以 2B 参数、40ms 推理延迟在 RoboTwin2.0 Clean 上达到 92.94% 成功率,验证了统一架构的可行性和高效性。
-
跨具身零标注学习的初步展示,指向了一条摆脱昂贵遥操作数据依赖的新路径。

电影级数字人,免显卡端渲染SDK,十行代码即可调用,工业级demo免费开源下载!
更多推荐

 2
2 0
0- 0



 已为社区贡献44条内容
已为社区贡献44条内容

所有评论(0)