
WorldArena 2.0:迈向多模态、交互式与跨平台的世界模型评测新范式
WorldArena 2.0评测基准突破具身智能世界模型的三重边界 清华联合多所顶尖高校提出的WorldArena 2.0评测框架,针对当前世界模型评估的三大局限展开系统性创新: 模态扩展:构建视触觉融合评测体系,通过触觉VAE模块和双流预测架构,将纯视觉评估扩展到接触丰富的操作任务(如HDMI插入、瓶子抓取) 功能升级:从静态离线评估转向交互式强化学习环境,验证世界模型支持策略持续优化的能力 平
从视觉到视触觉、从离线评估到在线强化学习、从仿真到真实世界的三维扩展
来源:arXiv:2605.17912机构:清华大学、上海交大、浙大、斯坦福等领域:具身智能 · 世界模型 · 评测基准
一、背景:世界模型评测亟需突破三重边界
在具身智能快速发展的当下,世界模型(World Model)正逐渐成为连接感知与决策的核心纽带。通过预测动作条件下的未来状态,世界模型使智能体能够在与环境的交互中进行推理与规划,为机器人操作、自动驾驶和智能交互等应用提供了重要的认知基础。从Dreamer系列在强化学习中的样本效率提升,到基于扩散模型和自回归架构的大规模视频生成模型,再到融合物理约束的交互式建模方法,世界模型正从低维动力学表示向视觉基础、动作感知的预测框架持续演进。
然而,与世界模型能力快速提升形成对比的是,现有评测基准主要存在三方面局限。第一,模态单一:绝大多数基准仅依赖视觉输入,忽略了触觉反馈在接触丰富操作中的关键作用。第二,功能局限:下游评估多局限于开环规划或静态策略评估,鲜有研究将世界模型作为交互式强化学习环境来考察其支持策略持续迭代优化的能力。第三,平台封闭:评测结果几乎完全来自仿真环境,缺乏在真实机器人平台上的验证。
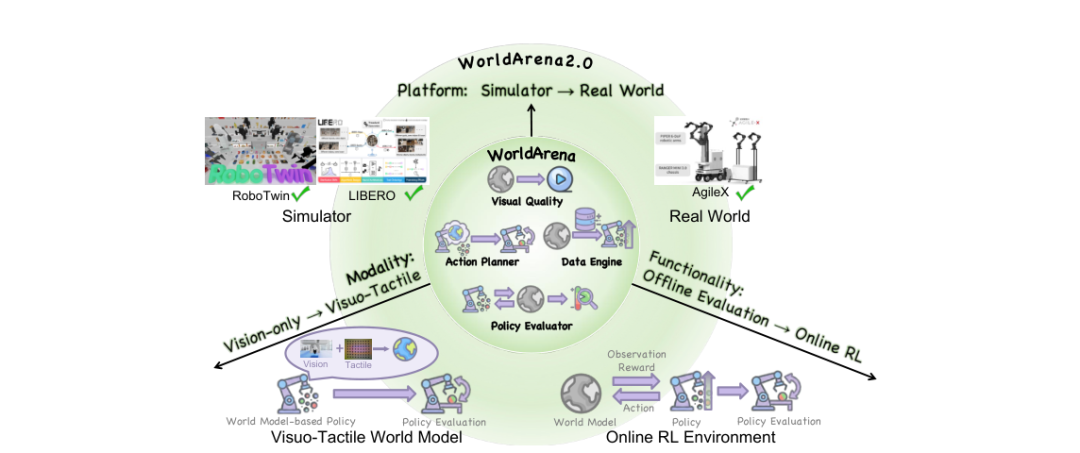
图1:WorldArena 2.0沿模态、功能、平台三个维度扩展示意图(来源:论文Figure 1)
针对上述三重局限,清华大学联合上海交通大学、浙江大学、斯坦福大学、香港大学、普林斯顿大学、中国科学院、中国科学技术大学、北京大学和新加坡国立大学等机构的研究团队,推出了WorldArena 2.0评测基准,从模态、功能和平台三个维度系统扩展了具身世界模型的评测边界。
二、模态扩展:从纯视觉到视触觉融合
视触觉融合是世界模型迈向真实物理交互的关键一步。在接触丰富的操作任务中,视觉信息往往只能提供部分可观测的状态,而触觉信号能够直接反映接触力、滑移状态和材料交互等关键物理信息,是完成精细操作不可或缺的感知通道。
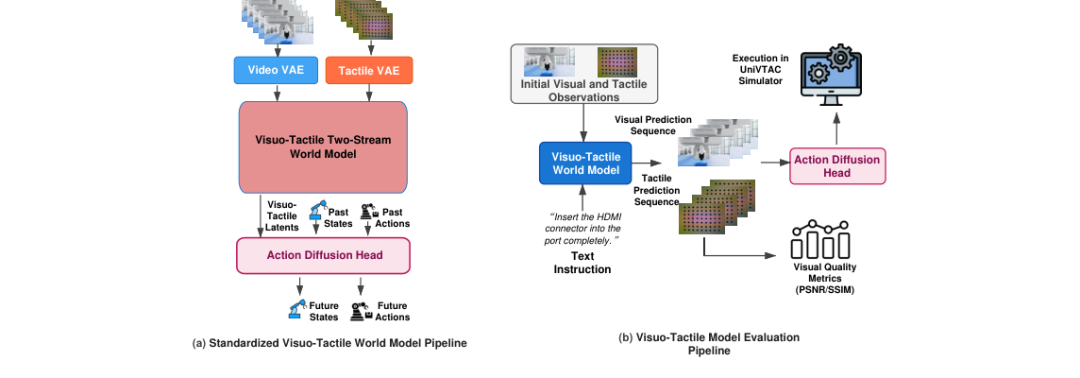
图2:标准化视触觉世界模型架构设计(左)与基于UniVTAC仿真器的评测流程(右)(来源:论文Figure 2)
WorldArena 2.0基于UniVTAC仿真器构建了标准化的视触觉评测流程,包含三个核心模块:
2.1 触觉VAE模块
负责将触觉形变图序列编码并与原视频世界模型的潜在空间对齐,实现触觉信息与视觉信息的统一表征。这种设计使得现有视觉世界模型可以即插即用地扩展触觉感知能力,无需对底层架构进行重构。
2.2 视触觉双流世界模型
同步执行视频预测和触觉感知预测的去噪过程,保持模态特异性动力学的同时实现跨模态协调,确保两种感官通道的信息能够有效互补。
2.3 动作扩散头
接收历史状态、动作以及预测的视触觉潜在表示,直接推断未来动作,完成从感知预测到功能操作的闭环。
在UniVTAC仿真器上,研究团队对Vidar、Wan2.2、Genie Envisioner等代表性视觉世界模型进行了扩展评测,考察其在"插入HDMI"和"举起瓶子"两个接触丰富任务上的表现:
|
|
|
|
|
|
|
|---|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
表1:视触觉世界模型在UniVTAC仿真器上的触觉预测质量与任务成功率对比(来源:论文Table 1)
**关键发现:**Wan2.2在触觉预测质量(PSNR 21.26,SSIM 0.746)和"插入HDMI"任务成功率(100%)上均表现优异,验证了通用世界模型丰富的跨模态知识先验能够有效对齐触觉模态。然而,在需要持续力控制的长程任务"举起瓶子"中,现有世界模型仍面临挑战,长程触觉反馈的建模是未来重要研究方向。
三、功能扩展:世界模型作为强化学习环境
将世界模型用作强化学习的交互环境,是检验其功能实用性的更高标准。传统评测关注世界模型能否生成视觉上合理的未来帧,而作为RL环境的评测则关注其能否支持智能体通过反复交互学习出有效的行为策略。这一转变意味着对世界模型的要求从"预测正确"升级为"训练有效"。
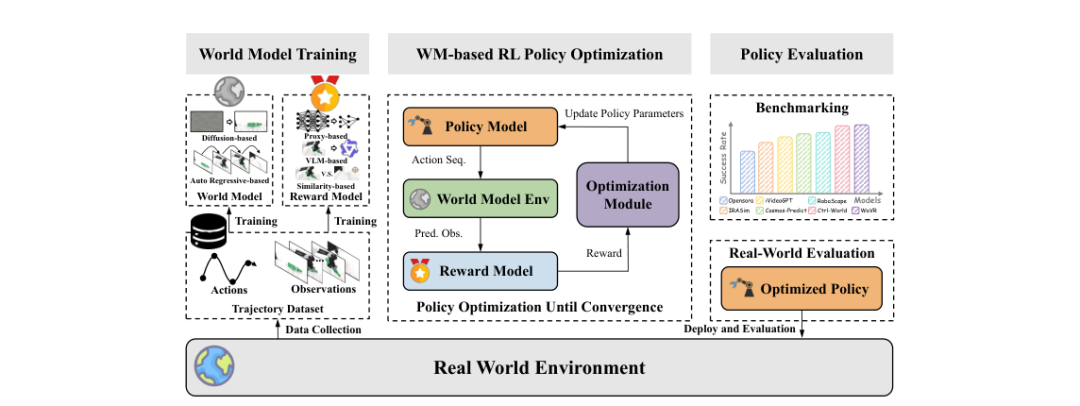
图3:WorldArena 2.0将世界模型作为RL环境的框架,包含训练、策略优化和评估三阶段(来源:论文Figure 3)
WorldArena 2.0提出的标准化框架将真实交互形式化为部分可观测马尔可夫决策过程,包含四个核心组件:
-
世界模型环境
:以当前观测和策略动作作为输入,输出预测的下一时刻观测
-
奖励模型
:基于当前观测和动作预测即时奖励
-
策略模型
:输出以当前观测为条件的动作分布
-
优化模块
:通过最大化期望折扣回报来更新策略参数
研究团队在RoboTwin 2.0的"点击铃铛"和"调整瓶子"任务上进行了系统评测,对比了OpenSora、IRASim、iVideoGPT、Cosmos-Predict-2.5、RoboScape、Ctrl-World和WoVR等七种世界模型:
|
|
|
|
|
|||
|---|---|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
表2:不同世界模型作为RL环境训练的策略在RoboTwin 2.0上的任务成功率(%)(来源:论文Table 2)
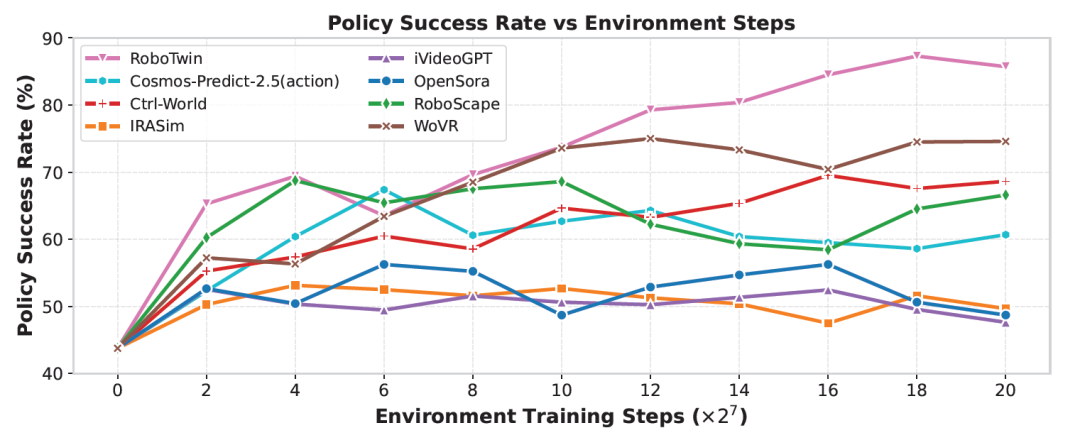
图4:基于代理奖励模型的"点击铃铛"任务中,不同世界模型环境的策略训练曲线(来源:论文Figure 5)
**关键发现:**WoVR在短程任务"点击铃铛"上达到75.00%的成功率,Ctrl-World在长程任务"调整瓶子"上达到70.70%,均显著优于监督微调基线。三种奖励模型对比显示,基于代理网络的奖励模型表现最为稳健,而VLM-based奖励因未针对任务微调,相似度奖励则高度依赖观测预测质量。
四、平台扩展:跨具身形态的仿真与真实世界评测
跨平台评测是WorldArena 2.0最具特色的设计之一。通过在三个异构平台上运行统一协议,研究团队得以系统评估世界模型的跨域泛化能力。
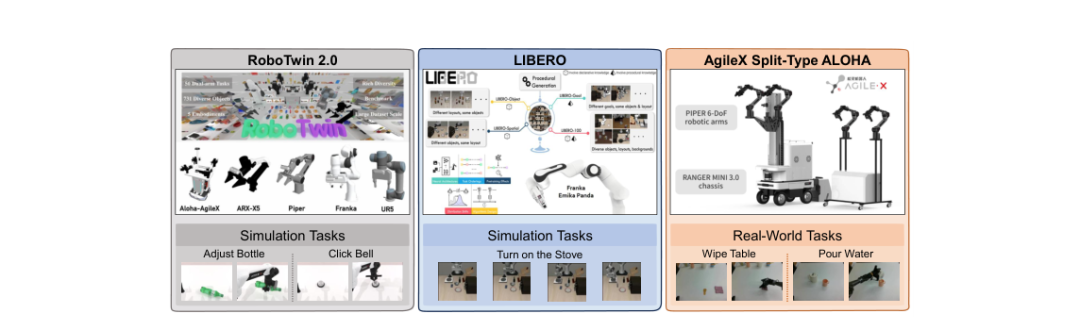
图5:WorldArena 2.0的三个评测平台:RoboTwin 2.0、LIBERO和AgileX ALOHA真实机器人(来源:论文Figure 4)
4.1 RoboTwin 2.0:域随机化双臂仿真
提供731个物体、147个类别的双臂操作环境,具有广泛的域随机化机制,涵盖场景杂乱、光照变化、纹理差异、桌面高度调整和语言指令变化等多个维度,重点考察模型的视觉与空间分布外泛化能力。
4.2 LIBERO:结构化知识迁移诊断
基于Robosuite构建了130个语言条件的单臂操作任务,通过程序化生成隔离空间、物体、目标和混合知识迁移,提供了细粒度的诊断能力,帮助精确识别世界模型在何种知识维度上存在学习困难。
4.3 AgileX ALOHA:真实世界物理验证
配备RANGER MINI 3.0底盘和PiPER 6自由度轻量机械臂,在真实环境中执行"倒水"和"擦桌子"任务,直接检验仿真到现实的迁移能力。真实世界评估天然包含光照变化、背景差异、传感器噪声和未建模物理效应,提供了最为严格的性能检验。
在跨平台任务成功率评测中,研究团队评估了世界模型作为数据引擎和动作规划器的表现:
|
|
|
|
|
|||
|---|---|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
表3:世界模型作为数据引擎和动作规划器在三个平台上的任务成功率(%)(来源:论文Table 3,部分数据)
**关键发现:**作为数据引擎,没有任何世界模型能够匹配真实演示数据的质量。真实世界评估中,仅有少数模型取得非零成功率,且远低于实际部署需求。多数模型在"擦桌子"和"倒水"任务上的成功率接近或等于零,凸显了仿真到现实的显著鸿沟。
五、跨平台相关性分析:揭示仿真与现实的关联模式
研究团队深入分析了跨平台排名相关性,为理解世界模型的迁移特性提供了量化依据。
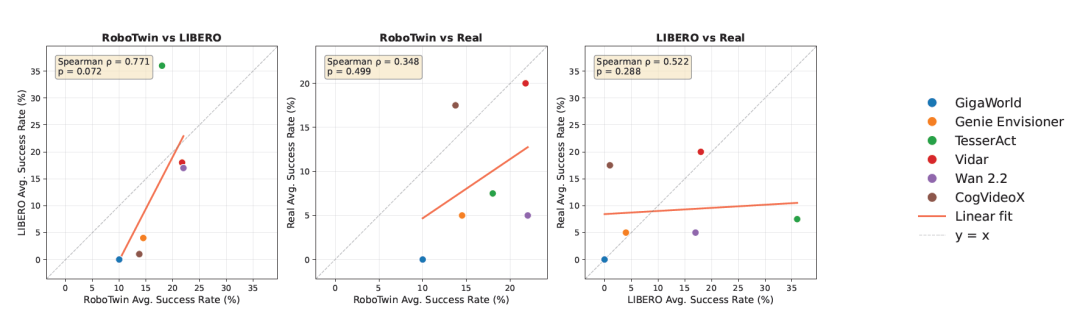
图6:RoboTwin、LIBERO与真实世界之间的任务成功率相关性分析(来源:论文Figure 6)
在感知质量方面,视觉质量、运动质量、物理遵循性和三维准确性在跨平台间展现出较强的相关性。例如,RoboTwin与LIBERO之间的物理遵循性排名相关系数高达0.839,表明低层保真度和几何推理能力具有较好的迁移性。相比之下,内容一致性和可控性的跨平台相关性较弱,说明语义对齐和指令级控制对域变化更为敏感。
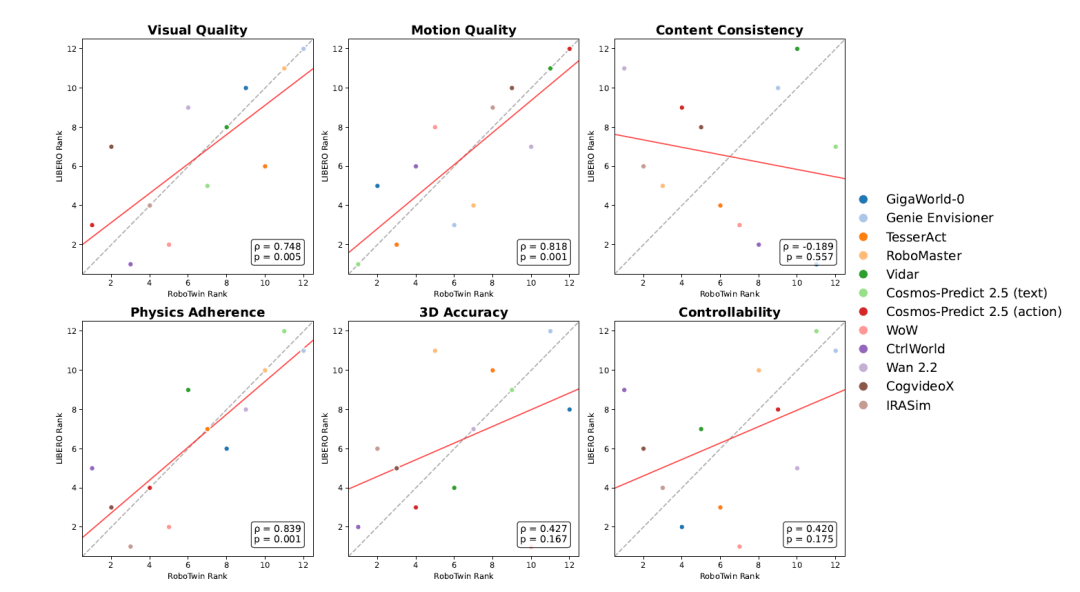
图7:RoboTwin与LIBERO之间的视频质量跨平台相关性(六个维度)(来源:论文Figure 7)
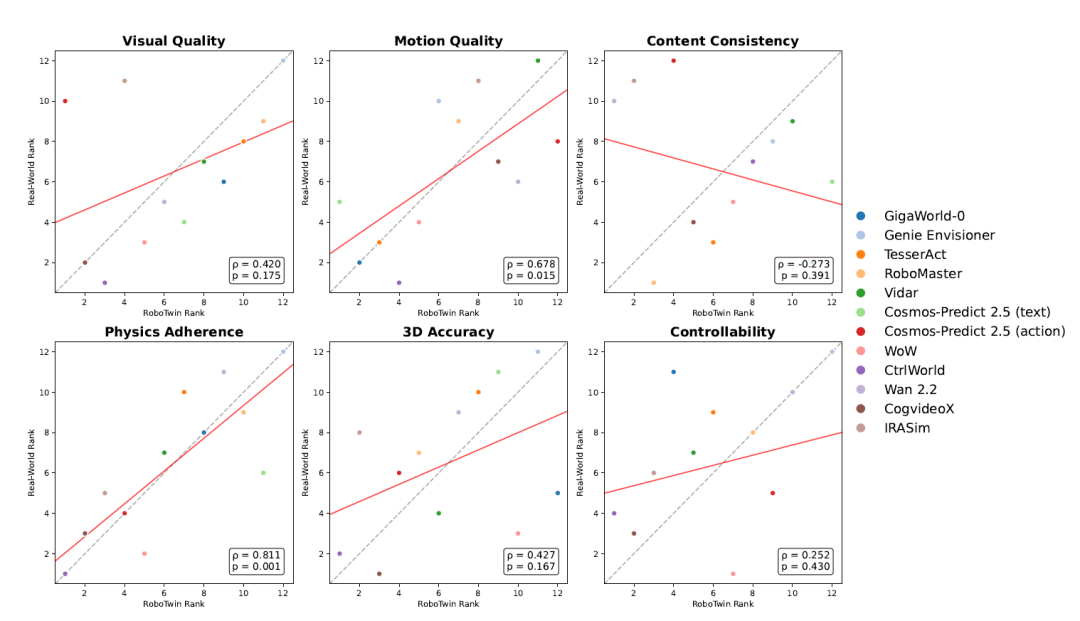
图8:RoboTwin与真实世界之间的视频质量跨平台相关性(来源:论文Figure 8)
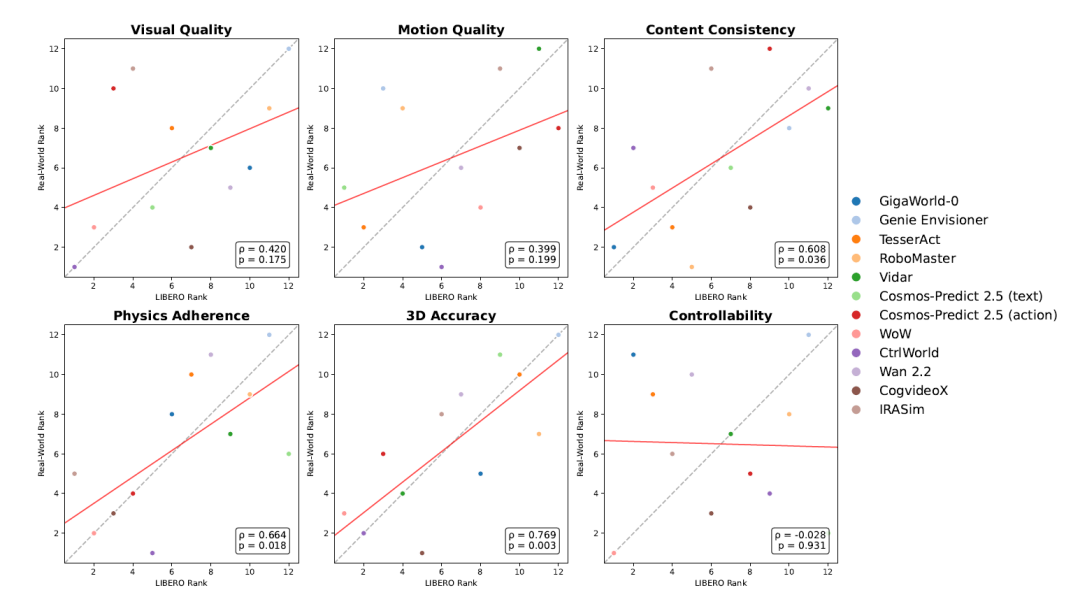
图9:LIBERO与真实世界之间的视频质量跨平台相关性(来源:论文Figure 9)
在功能评估方面,任务成功率在两个仿真器之间呈现正相关(Spearman相关系数0.771),但当与真实世界性能相比时,相关性大幅下降(RoboTwin与真实世界为0.348,LIBERO与真实世界为0.522)。这一模式清晰地揭示了仿真到现实的鸿沟:无论是感知层面的质量还是功能层面的成功率,仿真环境中的表现都不能可靠地代理真实世界部署效果。物理世界评估仍然是不可或缺的最终检验标准,任何仅在仿真中验证的模型都可能存在未被发现的真实世界失效模式。
**启示:**物理遵循性和三维准确性是跨平台迁移性最好的指标维度,而语义层面的指标迁移性相对较弱。这提示研究者在设计世界模型时,应优先强化物理一致性和几何准确性,这些能力最有可能带来跨平台的实际收益。
六、总结与展望
WorldArena 2.0通过模态、功能和平台三个维度的系统扩展,为具身世界模型评测建立了一个更加全面和贴近现实的评估框架。该基准首次将视触觉感知、在线强化学习和跨平台真实世界验证纳入统一评测体系,对12种前沿世界模型进行了系统性评估,为领域提供了宝贵的实证洞察。
实验结果揭示了若干重要趋势:
-
通用世界模型在触觉模态扩展上展现出令人鼓舞的潜力,Wan2.2等模型通过即插即用的触觉扩展即可在接触丰富任务上取得优异表现,表明跨模态知识迁移是可行的技术路径
-
世界模型作为RL环境已展现出支持策略优化的实用价值,顶尖模型的训练效果已接近仿真器训练水平,预示着世界模型辅助强化学习是一个值得深入探索的方向
-
跨平台评测一致地暴露了仿真到现实的性能差距,这种差距在功能评估中尤为显著,提醒研究者必须将真实世界验证作为模型开发的必要环节
展望未来,WorldArena 2.0计划进一步扩展感官模态覆盖范围,纳入更多物理传感器信号如力矩、声音和本体感知信息;增加任务复杂度和多样性,涵盖更广泛的物体类别和操作类型;并探索更具挑战性的真实世界场景,包括非结构化环境和动态干扰条件。随着世界模型从视觉预测器向交互式物理环境持续演进,全面而严格的评测基准将成为推动这一领域健康发展的关键基础设施。WorldArena 2.0所建立的多维评测框架,不仅为当前研究提供了可靠的评估工具,更为未来世界模型迈向真实世界应用奠定了坚实的评测基础。
参考文献
- Shang Y, Tang Y, Ma Y, et al. WorldArena 2.0: Extending Embodied World Model Benchmarking on Modality, Functionality and Platform. arXiv:2605.17912, 2026.
具身智能&世界模型blog: https://jinxindeep.github.io/blog/blog2026.html

电影级数字人,免显卡端渲染SDK,十行代码即可调用,工业级demo免费开源下载!
更多推荐



 2
2 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)