
NeurIPS 2025 | 华科大NAUTILUS:基于物理先验,让多模态大模型看穿深海迷雾!
摘要:论文提出NAUTILUS模型,用于解决水下图像颜色失真、细节模糊等问题。通过构建145万问答对的大规模水下多任务数据集NautData,并设计基于物理先验的视觉特征增强(VFE)模块,该模型能在特征层面逆向修复水下图像退化信息。实验表明,NAUTILUS在目标检测、分类等8项任务上性能显著提升,尤其在恶劣水下环境中表现出强鲁棒性。该研究为水下智能探索提供了新基准,其可解释的物理建模方法和即插
一、导读
水下世界的探索对于地球资源勘探和国家安全等领域至关重要,但水下图像通常存在颜色失真、细节模糊等问题,这给机器自动理解场景带来了巨大挑战。现有的研究方法大多针对单一任务,且缺乏大规模、多任务的训练数据,难以实现全面的水下场景理解。
为了解决这些难题,论文提出了一个名为NAUTILUS的模型框架,其核心是一个基于物理先验的视觉特征增强模块。通过构建一个包含145万问答对的大规模水下多任务数据集,并设计能明确修复退化信息的模型,NAUTILUS在多项水下理解任务上,如目标检测、分类和图像描述等,都取得了显著的性能提升。
二、论文基本信息

-
论文标题:NAUTILUS: A Large Multimodal Model for Underwater Scene Understanding
-
论文链接:https://arxiv.org/pdf/2510.27481
➔➔➔➔点击查看原文,获取更多大模型相关资料![]() https://mp.weixin.qq.com/s/PBU4hKR8Rmf2kMVX-vgTeQ
https://mp.weixin.qq.com/s/PBU4hKR8Rmf2kMVX-vgTeQ
三、主要贡献与创新
-
构建了首个大规模水下多任务指令数据集NautData,包含145万问答对。
-
提出了首个支持八种水下任务的大型多模态模型(large multimodal models, LMMs)NAUTILUS。
-
设计了一个即插即用的视觉特征增强(VFE)模块,能明确地修复退化信息。
-
实验证明,VFE模块能有效提升多个主流LMM基线模型在水下任务中的性能。
四、研究方法与原理
该论文提出的模型核心思路是:模仿水下成像的物理过程,在特征层面“逆向操作”,去除水下图像的退化影响,从而让模型看得更清楚、理解得更准确。
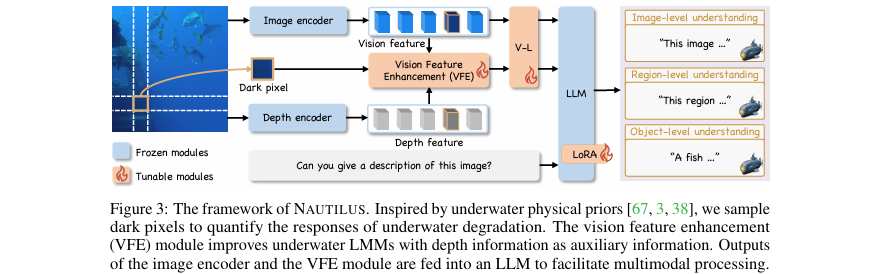
上图展示了NAUTILUS的整体框架。它主要由一个图像编码器、一个深度编码器、一个视觉特征增强(Vision Feature Enhancement, VFE)模块、一个视觉-语言投影层和一个大语言模型(LLM)组成。整个流程是,当输入一张水下图片时,模型不仅会提取常规的视觉特征,还会利用VFE模块生成一个“修复后”的增强版视觉特征。这两个特征会一同送入大语言模型中,结合用户的指令,最终生成对水下场景的理解。
理论基础:水下成像物理模型
论文的方法论根植于一个经典的水下成像物理模型。该模型指出,我们相机拍摄到的水下图像 是由两个部分组成的:一部分是物体本身反射的光 ,另一部分是水中悬浮颗粒散射的环境光 (也就是我们常感觉到的“雾蒙蒙”的效果)。其关系可以表示为:
其中,物体反射光 会随着与相机距离 的增加而衰减,可以用公式 来描述。这里的 是物体在没有光线衰减时的“真实”色彩,而 是衰减系数,它与颜色通道 和距离 都有关。
为了让模型看清物体的“真实”样貌,就需要从拍摄到的图像 中尽可能地恢复出 。通过变换上述公式,我们可以得到恢复目标 的表达式:
这个公式告诉我们,要恢复真实信息,需要做两件事:第一,减去背景散射光 ;第二,补偿因距离导致的光线吸收。NAUTILUS的VFE模块正是围绕这两个步骤设计的。
核心模块:视觉特征增强(VFE)模块
VFE模块是本文最大的创新点,它将上述物理恢复过程在特征空间中实现,而不是直接处理像素。
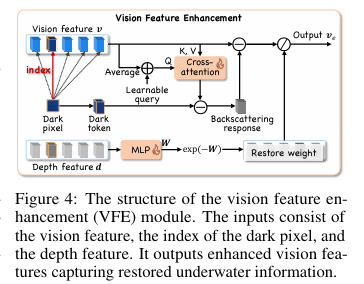
如上图所示,VFE模块接收三个输入:原始的视觉特征 、一个被称为“暗像素”的索引 、以及从图像中提取的深度特征 。
-
去除背景散射(Remove Backscattering):论文借鉴了一个名为暗像素先验的理论,该理论认为在水下图像中,那些本应是黑色的区域(暗像素)因为背景散射光的影响而呈现出蓝绿色。因此,这些暗像素的颜色值就代表了背景散射光的强度。在实践中,模型首先找到图像中最暗的那个图像块(patch),并将其对应的视觉特征 视为“暗令牌”。然而,直接减去这个特征并不准确,因为它也包含了全局的语义信息。为此,模型通过一个交叉注意力机制来估算并剔除这个“暗令牌”中包含的全局语义 ,从而得到一个更纯粹的背景散射响应 。最后,将这个散射响应 从整个视觉特征 中减去,就完成了第一步。
-
恢复光线吸收(Restore Light Absorption):根据物理模型,光线吸收的程度与距离 密切相关。因此,模型引入了一个独立的深度编码器来提取图像的深度特征(depth feature)。这个深度特征被送入一个多层感知机(MLP)中,用于预测一个吸收权重 。这个权重 就模拟了物理公式中的衰减系数。最后,通过以下公式计算得到增强后的视觉特征 :
这里的 表示逐元素相除。这个公式与物理恢复公式 在形式上保持了高度一致,相当于将物理规律巧妙地融入了神经网络结构中,指导模型学习如何“恢复”出更清晰的视觉信息。
五、实验设计与结果分析
论文的实验部分旨在验证所提出的NautData数据集的有效性以及VFE模块对水下场景理解能力的提升作用。
-
数据集:训练和评估主要使用了自建的NautData数据集,它包含15.8万张图片和145万个问答对,覆盖了八种任务。此外,还在公开数据集MarineInst20M和IOCfish5k上进行了泛化能力和计数能力的测试。
-
评测指标:针对不同任务使用了不同指标,如分类任务使用准确率(accuracy),检测任务使用平均精度(mAP),描述生成任务使用METEOR,计数任务使用平均绝对误差(MAE)等。
Comparison to SOTA Methods(与SOTA方法的比较)
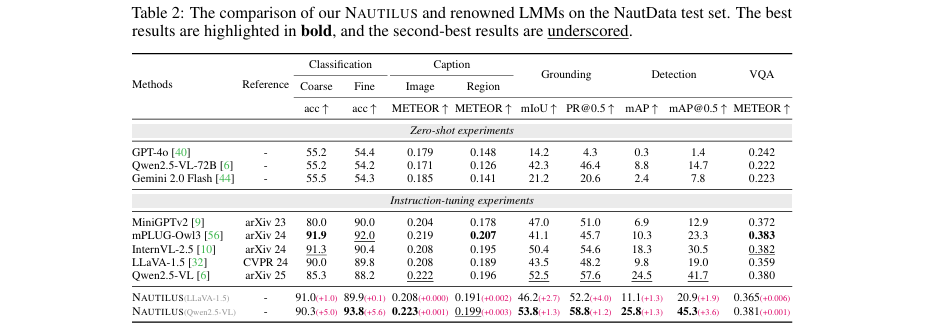
在NautData测试集上,论文将NAUTILUS与多种知名LMM(包括未经过微调的GPT-4o、Qwen2.5-VL-72B,以及在NautData上微调过的LLaVA-1.5、Qwen2.5-VL等)进行了比较。从表2可以看出,无论是基于LLaVA-1.5还是Qwen2.5-VL,集成了VFE模块的NAUTILUS在绝大多数任务上都取得了性能提升。例如,在Qwen2.5-VL基线上,NAUTILUS在细粒度分类、图像描述、定位和检测任务上均达到了最佳性能,其检测指标mAP@0.5从41.7提升到了45.3。这证明了VFE模块对于提升模型在复杂水下环境中的感知能力是行之有效的。
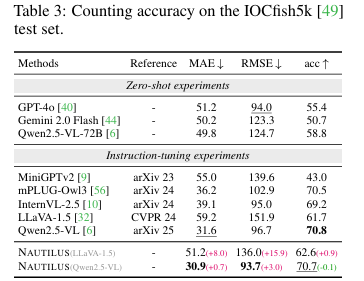
在IOCfish5k数据集上进行的物体计数任务评估中,如表3所示,NAUTILUS(Qwen2.5-VL)的MAE(平均绝对误差)达到了30.9,优于所有其他对比模型,这表明模型在群体感知方面也具有很强的能力。
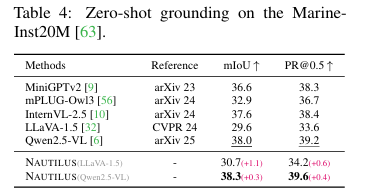
为了验证模型的泛化能力,论文在MarineInst20M数据集上进行了零样本定位(zero-shot grounding)测试。结果如表4所示,NAUTILUS在两个基线上都带来了性能增益,例如在Qwen2.5-VL基线上,PR@0.5指标从39.2提升到了39.6,证明了该方法具有跨数据集的泛化潜力。
Analysis and Ablation(分析与消融实验)

论文通过图5展示了NAUTILUS在八种不同任务上的定性结果。例如,模型能够准确地检测出图像中的潜水员和鱼类,对指定区域进行描述(“一大群黄色的带有蓝色条纹的鱼在珊瑚礁附近游泳”),并回答关于图像内容的问题(“海龟下面的鱼是什么颜色的?” “黄色”),充分展示了其强大的多任务、多粒度理解能力。
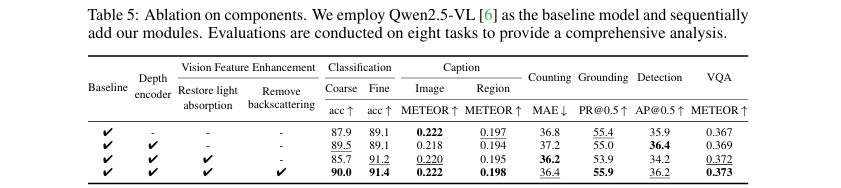
为了验证VFE模块中每个组件的有效性,论文进行了消融实验。如表5所示,基线模型(第一行)在仅加入深度编码器后,部分任务性能甚至下降了,说明简单的特征拼接效果不佳。但当利用深度信息来恢复光线吸收后(第三行),模型在五个任务上性能得到提升。在此基础上再加入去除背景散射模块(第四行),性能进一步在五个任务上得到提升。这有力地证明了VFE模块中每个组件都是有效且必要的。
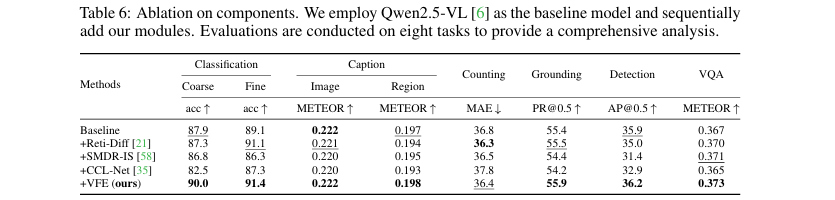
论文还探讨了在特征空间进行增强与在图像空间进行增强(即先用图像增强算法处理图片再输入模型)的区别。如表6所示,使用三种先进的水下图像增强算法(Reti-Diff, SMDR-IS, CCL-Net)预处理图像后,模型在多个任务上的性能反而下降了。这可能是因为图像增强过程丢失了部分原始信息。相比之下,本文提出的在特征层面进行增强的VFE模块(最后一行)保留了原始图像信息,并取得了更好的效果,证明了特征增强的优越性。
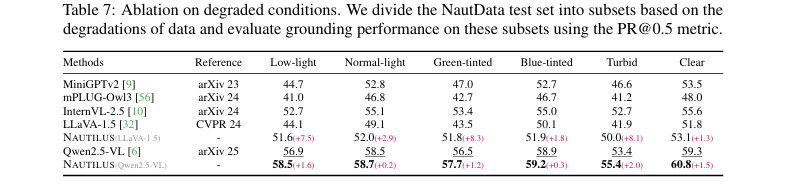
最后,为了评估模型的鲁棒性,论文在不同退化条件下(如低光、绿色调、浑浊等)对模型进行了测试。如表7所示,NAUTILUS在各种恶劣条件下都表现出显著的性能提升。例如,在LLaVA-1.5基线上,NAUTILUS在低光、绿色调和浑浊场景下的PR@0.5指标分别提升了7.5、8.3和8.1,展示了其在多样化水下环境中的强大实用性。
六、论文结论与评价
总结
本文的核心结论是,通过模拟水下成像的物理过程,在特征层面明确地对退化的视觉信息进行恢复,可以显著提升大型多模态模型在水下场景中的理解能力。作者为此设计了一个即插即用的VFE模块,并构建了一个大规模水下多任务数据集NautData。实验证明,该方法在多个基线模型和多项任务上均取得了稳定提升,尤其是在恶劣的水下环境中表现出很强的鲁棒性。
评价
这项研究为解决水下视觉任务提供了一个非常新颖且有效的思路。它最大的优点在于可解释性强且效果显著。不同于那些让模型自己“盲目”学习如何处理退化图像的“黑箱”方法,该模型基于明确的物理原理进行设计,使得模型的改进方向清晰、有据可依。此外,VFE模块作为即插即用的组件,可以轻松集成到现有或未来的LMM架构中,具有很强的通用性和实用价值。
然而,该方法也存在一些可以探讨的方面。首先,论文中提到,当前的数据集仍难以覆盖水下环境和物种的巨大多样性,因此模型在处理未见过的全新场景或物种时的表现(即开放词汇或少样本学习能力)还有待进一步研究。其次,VFE模块依赖于一个独立的深度编码器,这无疑增加了模型的计算开销。未来的工作可以探索如何更高效地获取或利用深度信息,或者将深度估计与特征增强过程更紧密地结合起来,以实现效率和性能的更好平衡。总的来说,这篇论文为水下智能探索领域提供了一个非常有价值的基准和方法论。
➔➔➔➔点击查看原文,获取更多大模型相关资料![]() https://mp.weixin.qq.com/s/PBU4hKR8Rmf2kMVX-vgTeQ
https://mp.weixin.qq.com/s/PBU4hKR8Rmf2kMVX-vgTeQ

电影级数字人,免显卡端渲染SDK,十行代码即可调用,工业级demo免费开源下载!
更多推荐
 20
20 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)