
CVPR 2026 | 突破跨域少样本检测瓶颈!LMP框架用多模态原型解锁域自适应新范式
光说不练假把式,这篇论文在6个完全不同的目标域做了测试:ArTaxOr(昆虫)、Clipart1k(卡通)、DIOR(遥感)、DeepFish(水下鱼)、NEU-DET(工业缺陷)、UODD(水下目标),覆盖了自然、卡通、遥感、工业、水下等多个视觉领域,1/5/10-shot设置下全测了个遍。对跨域少样本检测感兴趣的朋友,真的可以好好看看这篇论文——把复杂问题拆解得很清晰,每个模块的设计都有明确的
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达在计算机视觉领域,跨域少样本目标检测(CD-FSOD)一直是个棘手的难题。想象一下:要让检测器只靠几个标注样本,就能在完全陌生的视觉领域精准识别目标——比如从自然图像跨到遥感图、卡通画,甚至水下图像,难度可想而知。
传统基于视觉语言模型(VLM)的检测器,总绕不开两个痛点:要么只靠文本提示抓语义,丢了领域特有的视觉细节;要么样本太少,容易被相似背景干扰,满屏误报。最近看到一篇超有意思的CVPR方向论文,提出的LMP框架直接戳中这些痛点,用多模态原型的思路,把跨域少样本检测的性能拉到了新高度!
论文信息
题目: Learning Multi-Modal Prototypes for Cross-Domain Few-Shot Object Detection
学习多模态原型用于跨域少样本目标检测
作者:Wanqi Wang, Jingcai Guo, Yuxiang Cai, Zhi Chen
先聊聊核心痛点:为啥纯文本引导不好使?
咱们先掰扯清楚问题根源。比如“飞机”这个词,文本语义永远不变,但自然图像里的飞机、遥感图里的飞机、卡通里的飞机,视觉特征天差地别。
纯文本引导的检测器,就像只记了“飞机是什么”,却不知道“不同场景里飞机长啥样”。少样本场景下,这点更致命:一方面,文本语义和目标域外观对不上,定位精准度大打折扣;另一方面,少量正样本根本扛不住相似背景的干扰,误报率居高不下。
这篇论文的核心思路特别接地气:既然文本管“是什么”,那咱就加个视觉分支管“长啥样”,再把两者捏合起来!
LMP框架:双分支+视觉原型,一手抓语义一手抓外观
整个LMP框架的核心是双分支设计,咱们拆开看,一点都不复杂:
1. 双分支架构:文本+视觉,各管一摊又协同
文本分支保留了GroundingDINO的原有优势,靠文本提示维持开放词汇的语义理解能力——简单说,不管啥新类别,给个文本描述就能认,不局限于固定类别库。
视觉分支是重头戏,核心是“视觉原型构建模块”。这模块干了两件超关键的事:
-
类别级原型:从少量支持集样本里,提取每个类别的核心视觉特征,相当于把“目标域里这个类长啥样”浓缩成一个紧凑的特征模板;
-
困难负样本原型:这步太聪明了!对查询图里的真实框做随机抖动,生成那些和目标长得像、容易混淆的背景/干扰区域特征。比如把鱼的框稍微挪一点,覆盖到旁边的水草,专门建模这些容易误判的区域。
把正样本原型和负样本原型整合起来,模型就能清晰区分“真目标”和“长得像的干扰物”,不用额外加对比损失,靠常规训练就搞定。
2. 视觉原型怎么用?贯穿检测全流程
不是光建了原型就完事,这篇论文把视觉原型用到了检测的关键环节:
-
特征增强:让图像特征和视觉原型做交叉注意力,给特征打上“领域专属标签”;
-
查询选择:按图像特征和原型的相似度选候选区域,减少无关区域干扰;
-
视觉解码:解码器每一步都参考视觉原型,不管是分类还是框选,都盯着目标域的视觉特征来。
最后训练时先单独调视觉分支,再把文本+视觉分支联合训练,推理时融合两个分支的结果——既保语义,又抓外观,两全其美!
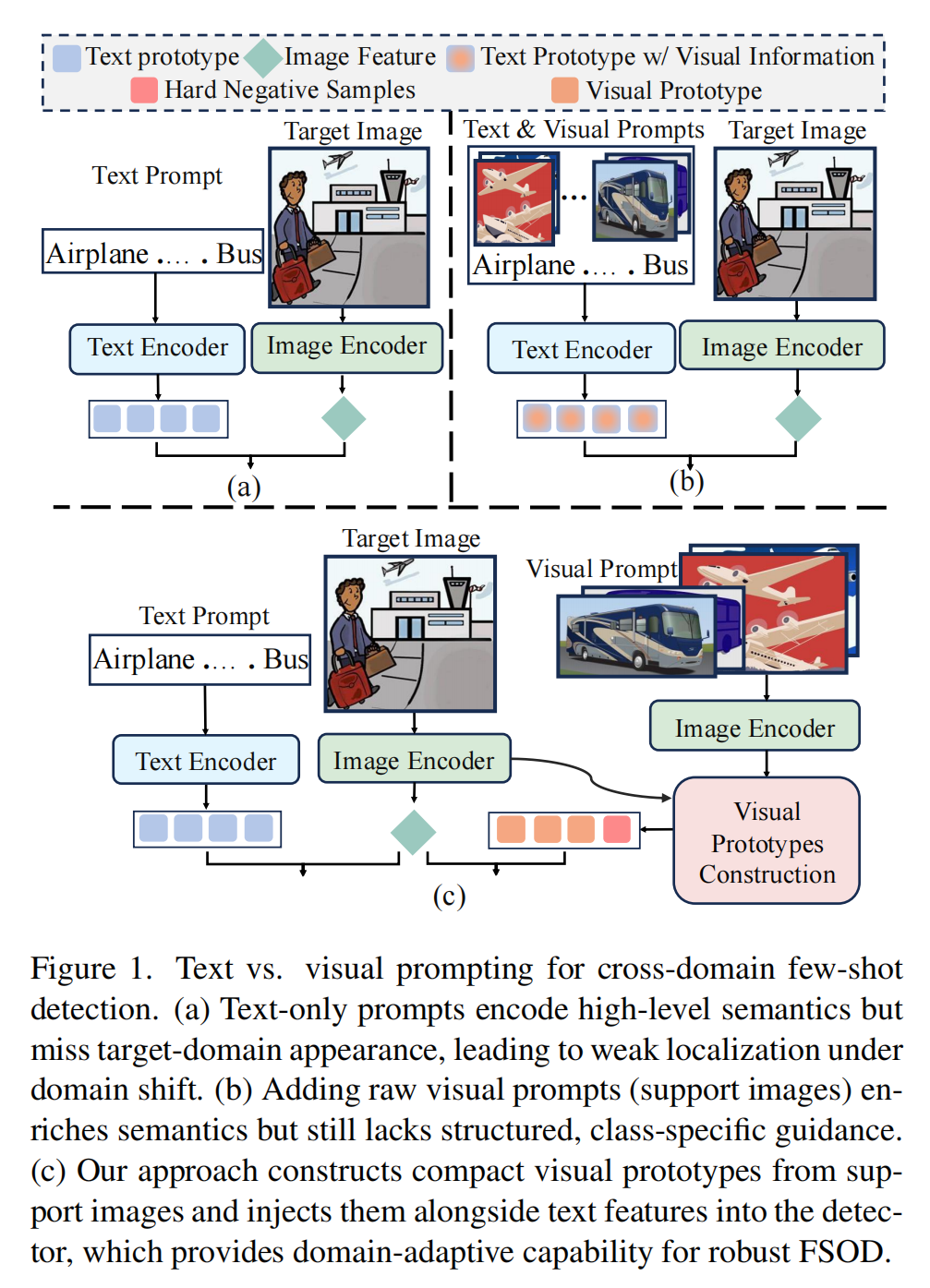 (图1:LMP框架整体结构图,能清晰看到文本分支和视觉分支的并行设计,以及视觉原型在检测流程中的核心作用)
(图1:LMP框架整体结构图,能清晰看到文本分支和视觉分支的并行设计,以及视觉原型在检测流程中的核心作用)
实验结果:6个数据集全开花,1-shot提升超明显
光说不练假把式,这篇论文在6个完全不同的目标域做了测试:ArTaxOr(昆虫)、Clipart1k(卡通)、DIOR(遥感)、DeepFish(水下鱼)、NEU-DET(工业缺陷)、UODD(水下目标),覆盖了自然、卡通、遥感、工业、水下等多个视觉领域,1/5/10-shot设置下全测了个遍。
核心结果超亮眼:
-
平均下来,相比纯文本基线GroundingDINO,1-shot提升8.0 mAP,5-shot提升3.6 mAP,10-shot提升2.1 mAP;
-
越是样本少的场景,提升越明显——1-shot时增益最大,正好解决了少样本的核心痛点;
-
粗标签数据集(比如ArTaxOr的昆虫分类)提升尤其大,因为这类数据集文本语义给的信息少,视觉原型补上了关键的外观细节。
消融实验:拆解开看,每个模块都有用
作者还做了超细致的消融实验,把核心模块拆开来验证:
-
只加类别级原型,比纯文本基线强;
-
再加困难负样本原型,性能直接拉满;
-
超参数分析里,每个真实框配3个困难负样本原型效果最好,视觉和文本分支损失权重1:1时,性能最优。
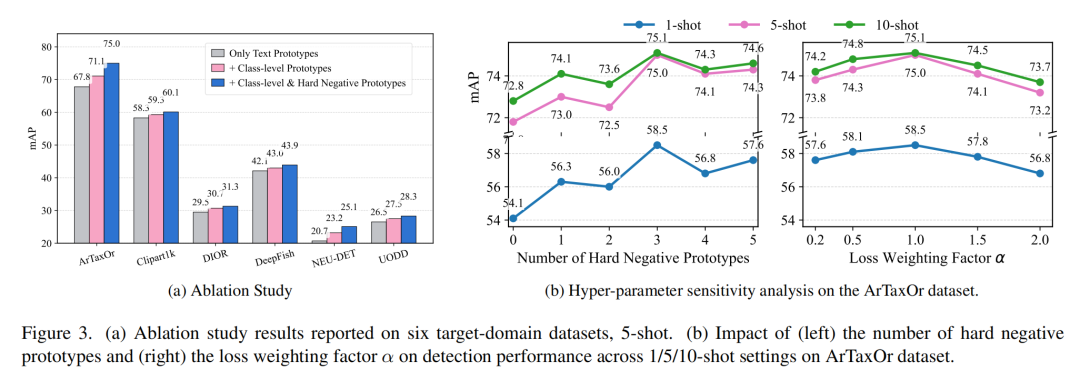 (图3:超参数敏感性分析,左图是困难负样本数量对性能的影响,右图是损失权重α的影响,能直观看到最优参数选择)
(图3:超参数敏感性分析,左图是困难负样本数量对性能的影响,右图是损失权重α的影响,能直观看到最优参数选择)
可视化:一眼看懂原型的作用
光看数字不够,可视化结果更能说明问题:
原型空间可视化
用t-SNE把特征投影到2D空间后能看到:查询特征会往对应类别的原型区域靠,而困难负样本正好落在那些容易混淆的区域——这就解释了为啥负样本原型能减少误报。
 (图4:原型空间t-SNE可视化,不同颜色代表不同类别,三角是查询特征,圆圈是困难负样本,能清晰看到特征的分布规律)
(图4:原型空间t-SNE可视化,不同颜色代表不同类别,三角是查询特征,圆圈是困难负样本,能清晰看到特征的分布规律)
定性结果:对比超直观
看实际检测效果,差距一下就出来了:
-
Clipart1k里,纯文本基线会把公交旁的终端结构误判成目标,LMP直接过滤掉干扰,只框准公交;
-
NEU-DET工业缺陷检测里,基线会混淆相似缺陷类别,LMP能精准区分;
-
DeepFish水下图像里,基线漏检很多小鱼,LMP召回率直接拉满;
-
ArTaxOr昆虫检测里,LMP的框更紧凑,再也不会漏检小触角、细腿这些细节。
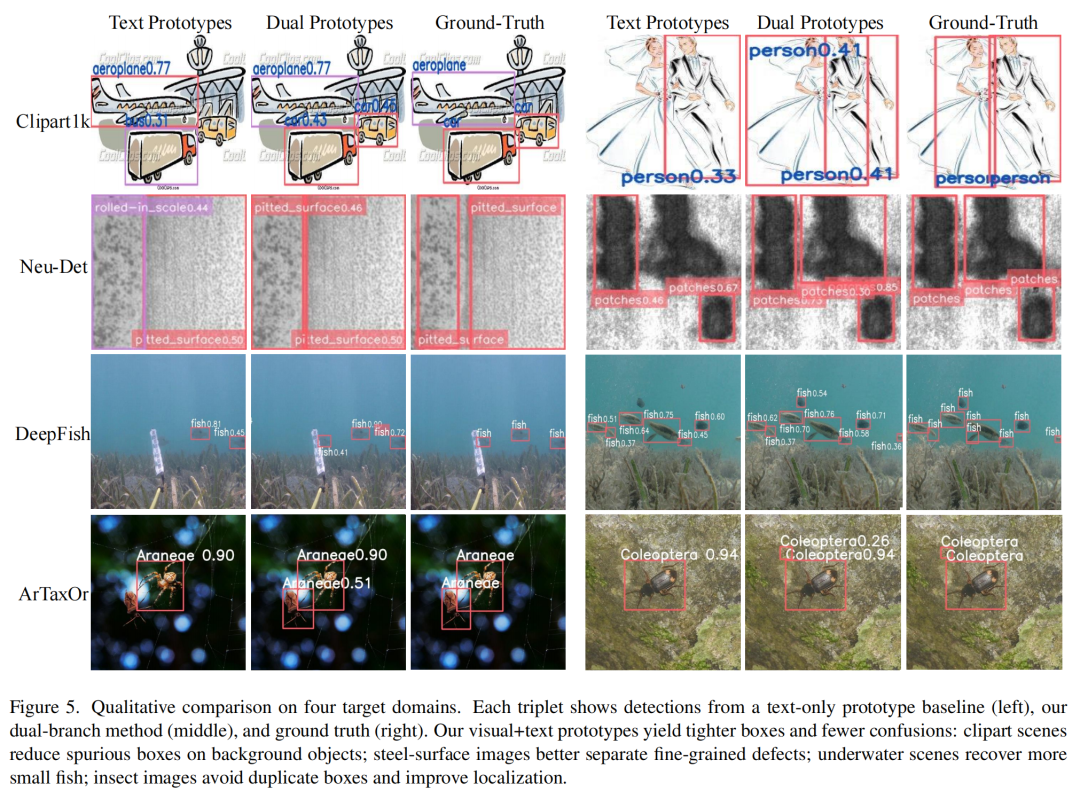 (图5:LMP与纯文本基线的定性对比,每一组都能看出LMP在抑制误报、精准定位上的优势)
(图5:LMP与纯文本基线的定性对比,每一组都能看出LMP在抑制误报、精准定位上的优势)
总结:简单又高效的创新,还留了不少拓展空间
这篇论文的创新点其实特别扎实,没有搞花里胡哨的操作:
-
双分支框架把文本语义和视觉外观结合,既保开放词汇能力,又做域自适应;
-
困难负样本原型的设计,精准解决了相似背景干扰的问题;
-
整个流程不用额外加对比损失,靠常规训练就实现了难例挖掘。
当然作者也坦诚说了局限性:比如对非典型支持样本比较敏感,双分支也带来了一点计算开销。不过未来可以做自适应原型、轻量级分支融合,甚至扩展到视频、半监督场景,潜力超大。
对跨域少样本检测感兴趣的朋友,真的可以好好看看这篇论文——把复杂问题拆解得很清晰,每个模块的设计都有明确的目标,落地性也强,这种思路不管是做研究还是工程落地,都很有参考价值!
下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:人工智能0基础学习攻略手册
在「小白学视觉」公众号后台回复:攻略手册,即可获取《从 0 入门人工智能学习攻略手册》文档,包含视频课件、习题、电子书、代码、数据等人工智能学习相关资源,可以下载离线学习。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~



电影级数字人,免显卡端渲染SDK,十行代码即可调用,工业级demo免费开源下载!
更多推荐

 0
0 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)