
WorldArena榜单第一名Pelican-Unify 1.0:迈向具身智能统一范式的新里程碑
北京人形机器人创新中心发布全球首个统一具身智能模型Pelican-Unify 1.0,实现了理解、推理、想象与行动的闭环融合。该模型突破传统模块化架构局限,通过共享语义空间、语言锚定思维链和联合去噪生成三大创新设计,将多模态认知统一整合。测试显示,该模型在视觉理解、运动控制和世界预测三项专业能力上均表现优异,其中多模态基准测试得分64.7分,显著超越同类模型。这一突破为具身智能发展提供了新范式,使
北京人形机器人创新中心团队发布首个统一理解、推理、想象与行动的具身基础模型
2026年5月 | 技术解读

图1 Pelican-Unify 1.0 统一具身智能模型概览:理解、推理、想象与行动的闭环融合
一、具身智能的范式演进:从模块化到统一化
具身智能(Embodied Intelligence)作为人工智能领域的前沿方向,正经历着从任务专用自动化向通用基础模型的深刻转变。传统机器人系统大多采用脚本化的自动化流水线架构:感知模块检测预定义状态,规划器选择预定义程序,控制器执行预定义动作。这种架构虽然在特定场景下表现稳定,但面对开放世界的复杂任务时,泛化能力受到严重制约。
近年来,具身智能领域涌现出多条并行发展的技术路线。视觉语言模型(VLM)如Gemini Robotics ER和Pelican-VL等,为具身场景带来了强大的语义理解与时空推理能力,但这些模型本质上属于"观察者"——它们能够解读场景、回答询问,却无法直接输出可执行的动作指令,也无法通过物理后果来验证自身推理的正确性。视觉语言动作模型(VLA)如RT-2、π0、π0.5、OpenVLA和Helix等,成功搭建了从语言感知到运动控制的桥梁,但这类模型通常缺乏显式的未来想象能力,其动作输出往往依赖于模仿学习映射,在未见任务组合、长程规划和接触密集型交互场景中泛化能力有限。
世界模型与视频生成领域同样取得了长足进步。CosmosPredict、LeWorldModel等模型能够对未来视觉状态进行想象,但这种想象往往隐式地编码在像素层面,难以通过任务逻辑、人类知识或语言推理进行精确引导。World Action Models进一步将想象与动作关联,但在缺乏统一推理机制的情况下,模型在 rollout 过程中难以解释、难以修正,长程误差累积问题依然突出。
面对这一现状,北京创新中心人形机器人(X-Humanoid)WFM系统团队提出了一个根本性的问题:物理智能究竟应该通过独立专家的规模化堆叠来构建,还是应该作为单一自适应循环的有机组成部分来习得?基于对这一问题的深入思考,团队于2026年5月正式发布了Pelican-Unify 1.0——首个按照"统一化"原则训练的具身基础模型。
**核心观点:**Pelican-Unify 1.0 的核心理念在于,理解、推理、想象与行动不应被视为彼此割裂的能力模块,而应作为单一自适应智能循环中相互依存的维度。具身智能体在物理世界中的进步,并非源于独立拥有视觉模型、语言模型、世界模型和动作策略,而是源于其将世界理解、任务推理、未来想象与动作执行整合于一个可对齐、可抽象、可规划、可精修的潜在世界空间中的能力。
二、统一范式的三重内涵
Pelican-Unify 1.0 所倡导的"统一",并非简单地将多个专家网络的输出进行拼接,也不是将独立优化的模块串联成更长的流水线。团队明确指出,真正的统一模型应当具备三个关键属性:统一理解、统一推理与统一生成。
2.1 统一理解:共享语义空间
统一理解要求将场景、指令、动作历史与视觉上下文嵌入到一个共享的语义空间中,形成对"智能体看到了什么"“需要完成什么”"已经做了什么"以及"世界处于何种状态"的整体性认知。在Pelican-Unify 1.0中,这一功能由单一的视觉语言模型(VLM)承担。该模型以Qwen3-VL为初始化基础,通过专门的嵌入器将视频帧、动作历史、语言指令和机器人本体状态统一映射到VLM的token空间。

数值回归与空间关系认知

物理空间推理与高度测量

点预测与轨迹规划

边界框定位与深度距离估计
具体而言,视频帧由三维视频VAE编码器进行编码,动作历史通过轻量级MLP嵌入,语言指令经由文本分词器处理,机器人本体状态则通过线性投影映射。所有模态的token被拼接后送入统一的Transformer进行处理,生成统一的隐层表示。这一设计的精妙之处在于,感知被指令所引导,语言被物理场景所锚定,动作历史被其任务进展效果所解释——各模态在共享的表示空间中实现了有机融合。
2.2 统一推理:语言锚定的思维链
统一推理的核心思想在于,将推理过程转变为一种以语言为锚点、可监督的过程,使其覆盖任务意图、动作选择与未来后果,而非脱离动作与想象的独白式语言输出。Pelican-Unify 1.0 的VLM在统一理解的基础上,以自回归方式生成思维链(Chain-of-Thought)轨迹。
该思维链轨迹巧妙地交织了两种互补的语言形式:视频思维链(Video CoT)描述并解释场景预期如何演化——哪些物体会移动、接触如何形成、工作空间如何重组;动作思维链(Action CoT)则解释并分解应当实现该未来的运动程序——调用何种子技能、末端执行器应瞄准哪些路径点。通过将两种思维链纳入同一序列,模型在单一因果传递过程中同步思考"应当发生什么"与"应当做什么"。
思维链轨迹的终点隐藏状态被进一步投影为一个稠密的循环状态变量z。这个z是下游未来生成模块访问模型理解与推理成果的唯一接口。由于z同时受到语言建模损失和下游视频、动作生成损失的共同塑造,它必须同时编码语义信息、预测性信息和可执行信息。
2.3 统一生成:联合去噪的未来想象与动作输出
统一生成是Pelican-Unify 1.0最具创新性的设计之一。该模块基于Wan2.2初始化的扩散Transformer(DiT),在相同的去噪过程中,通过两个模态特定的输出头,联合生成未来视频与下一阶段的低层动作块。视频流与动作流共享同一个去噪骨干网络,仅在输入和输出边界处使用模态特定的参数。
在视频侧,模型以观察到的历史帧为前缀条件,对未来帧进行条件扩散;在动作侧,模型以标准的流匹配方式进行训练。两个流的损失——视频损失、动作损失与语言推理损失——全部反向传播通过共享的循环状态z和共享的嵌入器,使得理解、推理、想象与行动在一个闭环中协同优化,而非四个独立模块的简单缝合。
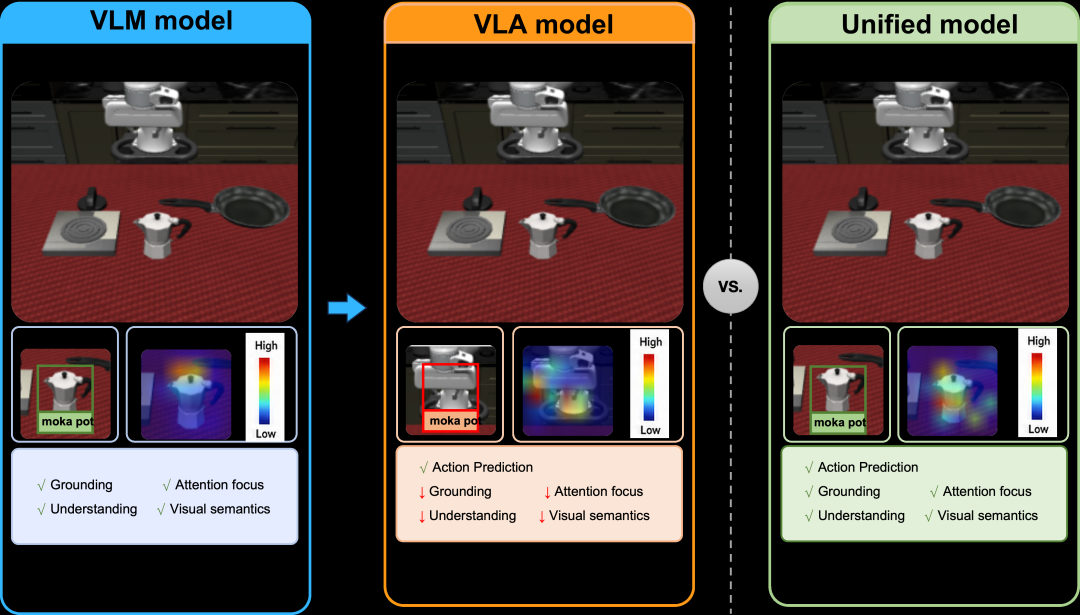
图2 从基础VLM出发,标准VLA策略训练会削弱定位与注意力能力,而Pelican-Unify 1.0在保留感知能力的同时实现动作预测
三、基准测试:单一检查点的三重专业能力
为验证统一化是否以牺牲专业能力为代价,研究团队将Pelican-Unify 1.0在三个刻意分离的评估体系中进行测试:作为视觉语言模型参与八项多模态基准评测,作为视觉运动策略参与RoboTwin双臂仿真评测,以及作为动作条件世界模型参与WorldArena评测。
3.1 理解能力:八项基准全面领先
在八项多模态基准测试中,Pelican-Unify 1.0取得了64.7的平均分,在同等规模模型中表现最优。这一成绩相较于其基础模型Qwen3-VL-4B-Instruct的58.2分有显著提升,且大幅超越了MolmoAct(27.5分)等先前的VLA架构。
|
|
|
|
|
|
|
|
|
|
|
|---|---|---|---|---|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
详细分析表明,这些增益并未以牺牲通用多模态能力为代价。在传统通用推理基准上,Pelican-Unify与Qwen3-VL基本持平;而在具身导向的Where2Place和PhyX基准上,模型分别取得了45.2分和61.7分,较基础模型提升了28.2分和20.6分。这表明统一模型学习到了丰富的物理 grounded 表示,为下游动作与视频预测提供了更强的特征支撑。
3.2 动作能力:RoboTwin上的强劲表现
在RoboTwin 50项双臂操作任务基准上,Pelican-Unify 1.0达到了93.5%的平均成功率。在标准条件下和随机化条件下分别取得了93.6%和93.3%的成功率,在参与对比的方法中位列第二,仅次于MotuBrain的95.9%,但显著优于AIM(93.1%)、LingBot-VA(92.3%)和starVLA(88.3%)等专用方法。
|
|
|
|
|
|
|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
逐任务分析显示,50项任务中有31项达到至少95%的成功率,39项达到90%,15项实现完美解决(100%)。高成功率任务涵盖点击、摇晃、堆叠、交接和关节物体操作等多种类型,表明模型在精确接触与多物体协调场景下均保持了可靠的性能。失误主要集中在最具挑战性的长程或几何敏感任务上,如悬挂马克杯和垃圾桶插入等需要严格对齐或持续接触的场景。
3.3 想象能力:WorldArena评测登顶
在WorldArena世界模型基准上,Pelican-Unify 1.0的想象组件取得了66.03的EWM总分,位列第一。尤其在3D准确率(98.13)和运动质量(62.69)两项关键指标上均排名第一,这两项指标对空间一致性和物理合理性要求极高。
|
|
|
|
|
|
|
|
|
|
|---|---|---|---|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
为避免自动评测指标可能奖励视觉干净但与任务无关的 rollout,研究团队进一步开展了盲测人工评估。训练有素的标注员从可控性(保持首帧条件)、任务成功率(达成操作目标)、时间一致性(形状稳定无闪烁)和物理合理性(接触与重力连贯)四个维度进行评分。Pelican-Unify 1.0取得了1.76的最高均分,在任务成功率(1.81)和可控性(2.00,满分)两项上表现尤为突出。

图3 Pelican-Unify 1.0支持动作条件视频预测,实现输入动作指令与生成视频帧的细粒度对齐
四、真实机器人验证:从仿真到物理世界的跨越
为验证模型在真实物理环境中的综合能力,研究团队在UR5e机械臂和天工人形机器人平台上开展了两组核心实验:组合泛化测试与零样本泛化测试。
4.1 组合泛化:未见任务序列的连续执行
组合泛化测试的设计颇具巧思。研究团队选取了两项原子任务:A(插入RJ45网线)和B(涂抹防水胶)。在训练阶段,模型仅分别学习这两项任务,训练数据中从未出现将A与B串联执行的完整演示。在测试阶段,机器人接收单一自然语言指令(例如"将RJ45网线插入3号端口并涂抹防水胶"),需要在一个连续 episode 中依次完成A阶段和B阶段。
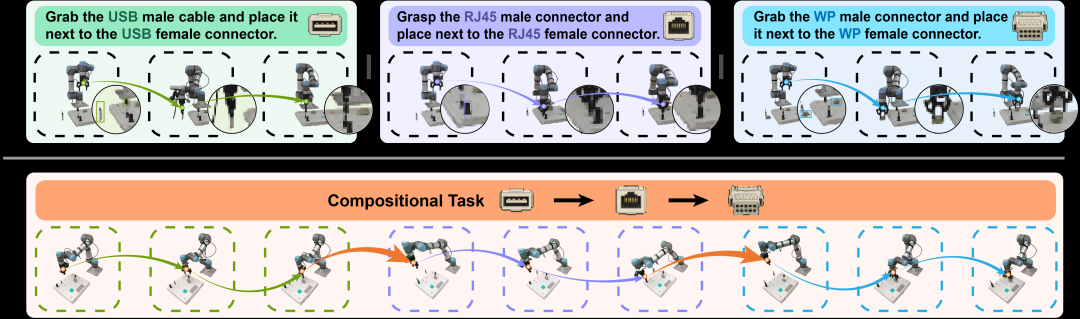
图4 组合泛化评估:训练阶段仅学习原子任务,测试阶段评估未见组合任务,展示长程具身操作中的强组合泛化能力
实验结果表明,模型成功完成了这一挑战。关键转折点出现在A任务完成、B任务启动的衔接时刻——此时刚完成的A状态必须被重新感知为B的新初始条件。VLA基线方法在此过渡点失败的根源,并非无法重新感知环境,而是其动作分布缺乏对"A完成后应当发生什么"的表示。而Pelican-Unify 1.0的想象面在训练期间已将每个原子动词落地为 future-frame 分布,能够渲染 post-A 场景状态并以其为条件重新生成动作;动作面随之跟进。这一成功的特别之处在于,模型从未见过完整的串联演示,却学会了感知-动作循环的本质,而非仅仅记忆了更丰富的动作策略。
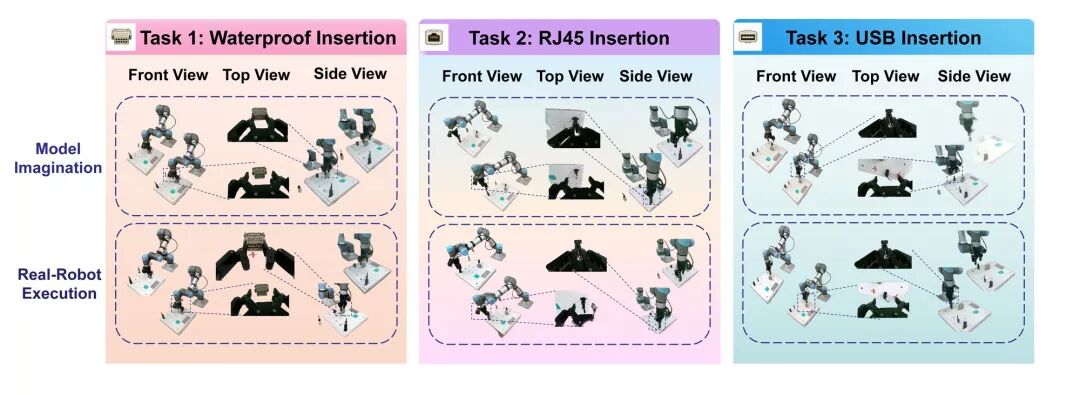
图5 细粒度操作与物理想象能力:在防水、RJ45和USB插入等挑战性连接器插入任务中展现精细操作技能,同时生成与真实世界高度一致的物理想象视频
4.2 零样本泛化:跨任务的迁移能力
在天工人形机器人环境中,研究团队开展了系统的零样本泛化评估。模型在五项已见任务(每项约300个视频-动作 episode)和三项未见任务(每项仅提供50个视频序列)上进行联合训练。评估结果显示,Pelican-Unify 1.0在已见任务上保持了高保真执行能力,同时在未见任务上也展现出强劲的跨任务泛化性能。

图6 已见任务执行时间线:清扫碎屑入簸箕(侧视图与俯视图同步观测)

图7 已见任务执行时间线:向杯中倾倒液体

图8 未见任务执行时间线:擦拭杯子——展示跨任务泛化能力
这些真实世界实验为统一架构的价值提供了最直接的证据。模型生成的想象视频与真实执行视频高度一致,表明其并非简单地"幻觉"出看似合理的场景,而是基于实际环境动力学进行条件预测,在执行过程中实现了 grounded 且物理连贯的推理。
五、技术架构深度解析
5.1 统一理解的模态融合机制
Pelican-Unify 1.0的多模态上下文在控制步t时刻被表示为c_t = (a_{<t}, l,=“” o_{≤t},=“” s_{≤t}),即动作历史、语言指令、环境观测和机器人本体状态的集合。每种模态首先通过各自的嵌入器提升到vlm的token空间:视频帧由三维视频vae=“” e_v编码,动作历史由轻量级mlp=“” e_a嵌入,语言指令通过文本分词器处理,机器人状态通过小型线性投影映射。<=“” p=“” style=“margin: 0px; padding: 0px; box-sizing: border-box;”>
值得注意的是,E_v和E_a这两个嵌入器在统一未来生成器中被复用,这意味着理解与生成共享同一个模态嵌入空间。所有token拼接后由VLM处理,生成统一隐层表示H_t = VLM_φ(c_t)。H_t既是编码器侧状态,也是VLM自回归解码思维链轨迹的起点;而连接下游生成的实际桥梁则是轨迹终点提取的循环状态z。
5.2 统一推理的循环状态设计
思维链轨迹τ_t以自回归方式生成,交替包含视频思维链与动作思维链。轨迹终点的隐藏状态h_{τ_t}经由学习得到的投影P_φ映射为稠密循环状态z。z是下游未来生成访问模型理解与推理成果的唯一接口,其独特价值在于同时受到语言建模损失和下游视频、动作生成损失的联合塑造,因此必须同时编码语义、预测和可执行三类信息。
5.3 统一生成的联合去噪机制
统一未来生成器(UFG)以z为条件,在共享的去噪骨干网络中联合处理视频与动作两个目标。两个目标首先通过共享嵌入器(即VLM侧使用的E_v和E_a)提升到生成器的token空间。在共享扩散时间s下,干净潜变量与高斯噪声混合生成噪声状态;随后,视频与动作token连同条件z一起进入单个DiT,两个轻量级输出头d_v和d_a将隐藏状态读出为各模态的速度预测。
在视频侧,模型扩展了标准流匹配框架,使DiT在噪声化的未来潜变量之外,还能看到由共享E_v编码的观察前缀。前缀区域保持干净,仅未来区域被加噪。这种设计确保了观察帧条件天然存在于生成器的token空间中,无需单独的条件编码器。
最终的联合训练目标为三项损失的加权和:文本损失(思维链的自回归负对数似然)、视频损失(未来区域的流匹配损失)和动作损失(有效动作维度上的平滑L1回归)。所有三项损失均通过共享的循环状态z和共享嵌入器反向传播,使得理解、推理、想象与行动作为单一闭环而非四个独立模块被优化。
六、对具身智能领域的启示
Pelican-Unify 1.0的实验结果对具身智能领域的发展方向提出了重要启示。研究团队指出,集成化的物理行为依赖于模块间的耦合,而不仅仅是各组件的独立强度。零样本迁移、组合技能使用和长程连贯性,正是模块化流水线试图在规划器、世界模型与策略之间的接口处 engineered 的行为。而Pelican-Unify的结果表明,这些行为难以通过孤立地增强任一组件来获得。
没有未来想象的策略,其后果意识薄弱;没有统一推理的世界模型,难以通过任务语义和人类知识进行引导;没有动作与想象的推理,则与物理结果脱节。模块化系统所缺失的,不仅是更多的容量,更是一种迫使各组件在训练过程中相互适应的训练机制。
这一观点改变了具身智能领域应当衡量的进步标准。一旦理解、推理、想象与行动被训练为单一循环,改进不再仅仅是让每个专家变得更大,而是取决于模型在多大程度上跨模态共享表示、推理在多大程度上直接约束生成、未来视频与动作在多大程度上被联合解码,以及数据本身在多大程度上包含对齐的观测、指令、推理、动作与未来结果。研究团队特别强调,最有价值的数据并非简单地增加旧形式的数据量,而是"闭环数据"——在同一示例上标注了上述所有信号的耦合训练数据。
核心贡献总结
Pelican-Unify 1.0的主要贡献可概括为以下四个方面:
-
统一范式:
将物理智能形式化为理解、推理、想象与行动的耦合循环,建模的基本单元不是孤立专家或成对融合,而是闭环本身。
-
三种统一的具体实现:
通过动作导向的任务状态实现统一理解,通过指定未来应当如何发生的稠密循环状态z实现统一推理,通过从同一z联合去噪未来视频与低层动作实现统一生成。
-
端到端可学习目标:
语言、视频与动作监督被联合训练,三项损失均反向传播通过共享的潜在表示,将推理、想象与行动从模块间消息转变为单一模型内的相互塑造梯度。
-
实证证据:
在VLM推理、视觉运动策略学习和世界建模基准上匹配或超越专用模型,同时在真实UR5e工业控制面板操作任务上实现显著更强的零样本、组合和长程性能。
七、结语
从亚里士多德的"灵魂无形象则不思",到威廉·詹姆斯的"我的思维始终为行动而存在",再到《礼记·中庸》的"博学之,审问之,慎思之,明辨之,笃行之"——人类对智能本质的思考始终围绕着认知与行动的统一。Pelican-Unify 1.0正是这一哲学传统在人工智能时代的工程实践。
研究团队谦逊地表示,他们并非宣称实现了通用的具身智能,而是提出了一个更为具体的命题:具身智能的基础模型应当允许理解、推理、想象与行动通过共享表示协同演化,而非将其作为孤立系统分别精修后再进行连接。Pelican-Unify 1.0证明,这种统一不仅是工程上的简化,更是一种能够保留专家模型优势、同时催生依赖于循环本身才能涌现的行为的实用建模方向。
具身智能的下一阶段,或许将更少地由组装更大的专家所塑造,而更多地由学习理解、推理、想象与行动如何成为单一自适应过程所定义。Pelican-Unify 1.0为这一方向迈出了坚实的一步。
世界模型blog:世界模型bolg https://jinxindeep.github.io/blog/blog2026.html

电影级数字人,免显卡端渲染SDK,十行代码即可调用,工业级demo免费开源下载!
更多推荐


 7
7 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)