
Qwen/Qwen3-0.6B部署教程-Vllm
vLLM 是一个高性能的大型语言模型推理和服务库,具有以下特点:它支持多种模型(如 Llama、Mixtral 等)和硬件(如 NVIDIA GPU、AMD GPU 等),能够显著降低推理成本并提高资源利用率。Vllm一般适用于在linux上部署大模型,本文以ubuntu 24.02.2 系统、内存32G、显卡Nvidia、显存12G上部署为例讲解。A、硬件配制要求:CUDA 12.2。B、pyt
一、前言
vLLM 是一个高性能的大型语言模型推理和服务库,具有以下特点:
- 高性能:吞吐量高,推理速度快。
- 内存优化:通过 PagedAttention 技术高效管理内存。
- 易用性:与 Hugging Face 模型无缝集成,支持多种模型。
- 分布式推理:支持多 GPU 分布式推理,提升处理能力。
- 开源:社区驱动,支持广泛,便于开发者使用和改进。
它支持多种模型(如 Llama、Mixtral 等)和硬件(如 NVIDIA GPU、AMD GPU 等),能够显著降低推理成本并提高资源利用率。
Vllm一般适用于在linux上部署大模型,本文以ubuntu 24.02.2 系统、内存32G、显卡Nvidia、显存12G上部署为例讲解。
二、准备工作
A、硬件配制要求:CUDA 12.2。
B、python已安装:版本3.8以上。
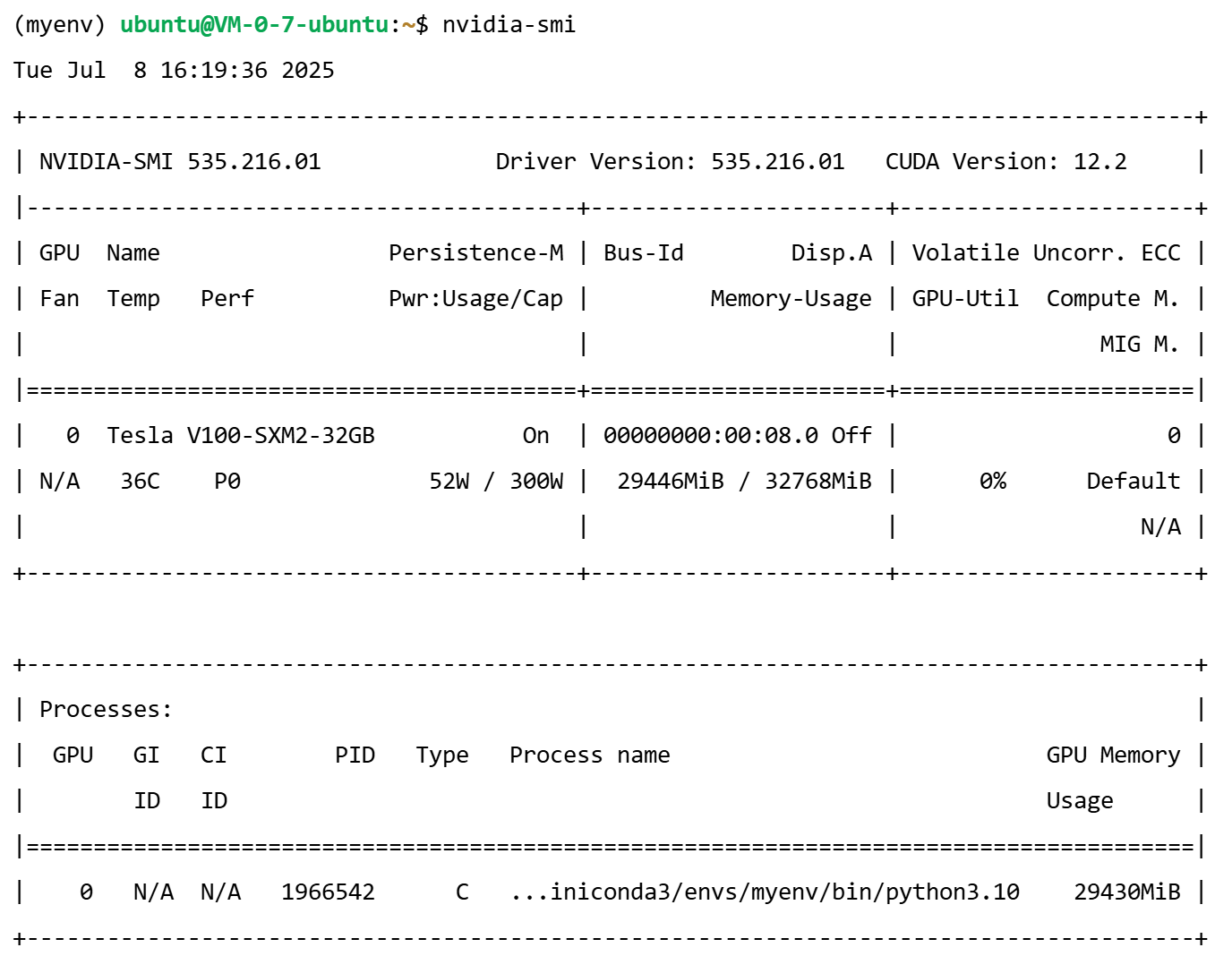
C、系统已安装cuda:通过如下命令查看
D、根据自己的硬件下载对应的Qwen版本:
魔塔网站:ModelScope 魔搭社区,搜索“Qwen-”:
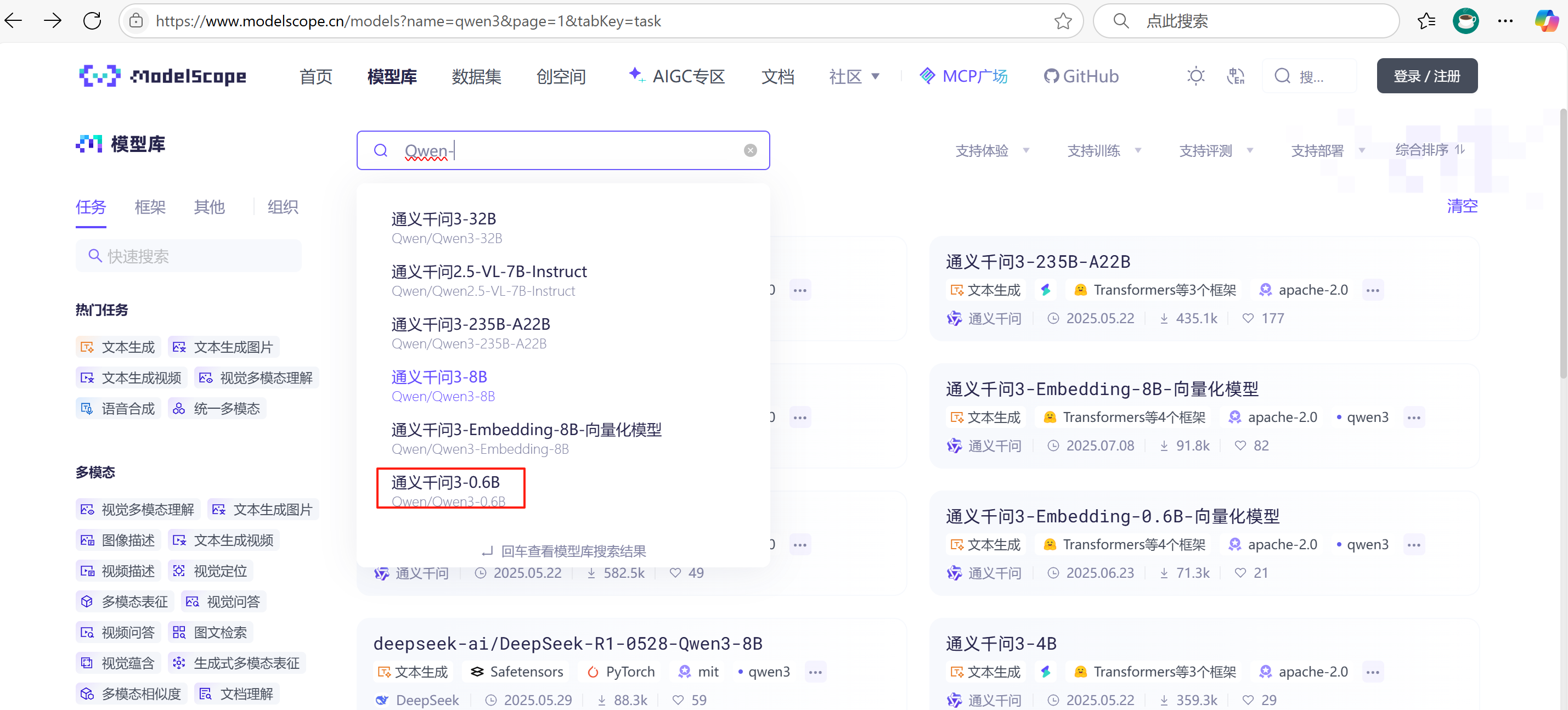
点击自己要安装的模型,进入其详情页,点“模型文件”-》“下载模型”按照里面说明安装modelsope然后用modelscope下载即可。也可以区huggingface网站下载,但需要魔法上网。
我下载的是Qwen3-0.6B。
三、Vllm部署Qwen-6B
1、创建虚拟环境并激活
虚拟环境可以隔离不同项目所需的 Python 库,避免库版本冲突,保持环境的纯净和隔离。
先创建一个新的python虚拟环境,后面在此环境中部署运行,如若用conda命令创建新虚拟环境myenv,并激活它:
conda create -n myenv python=3.10
conda activate myenv2、安装vllm
在激活的虚拟环境中,执行以下命令安装 vLLM:
pip install vllm确认已安装:

3、Vllm启动Qwen3服务
将上面下载的Qwen3解压缩,假设解压后的目录为path/models,则终端中用下面命令示例启动Qwen3推理服务:
VLLM_USE_V1=0 vllm serve ~/.cache/modelscope/hub/models/Qwen/Qwen3-0.6B --port 8000 --max-model-len 6384
命令解释:
实际是启动一个基于 vLLM 的 OpenAI API 服务器。Qwen3是兼容openai api协议的。
1)CUDA_VISIBLE_DEVICES=0
作用:设置环境变量 CUDA_VISIBLE_DEVICES,指定可用的 GPU 设备。
参数解释:0:表示只使用系统中的第一个 GPU 设备(设备编号从 0 开始)。如果有多个 GPU,可以通过设置为 0,1 等来指定多个设备,并且可以指定--tensor-parallel-size参数-启用n卡张量并行。
2)python -m vllm.entrypoints.openai.api_server
作用:运行 vLLM 提供的 OpenAI API 服务器模块。
参数解释:
-m:表示运行一个 Python 模块。
vllm.entrypoints.openai.api_server:指定运行 vLLM 中的 OpenAI API 服务器模块。
3)--model path/models
作用:指定要加载的模型路径。
参数解释:
--model:表示指定模型路径的参数。
path/models:模型文件的路径。
4)--port 8000
作用:指定 API 服务器运行的端口号。客户端可以通过 http://localhost:8000 访问该服务。
参数解释:
--port:表示指定端口号的参数。
8000:API 服务器将监听的端口号。
四、问题及解决
1、找不到模型
如下运行:
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Qwen/Qwen3-0.6B",
"messages": [
{"role": "system", "content": "你是一名科技领域专家"},
{"role": "user", "content": "请解释Transformer架构的核心思想"}
],
"max_tokens": 200,
"top_p": 0.9
}'
问题:
返回错误:{"object":"error","message":"The model `Qwen/Qwen3-0.6B` does not exist.","type":"NotFoundError","param":null,"code":404}
解决:
用“curl http://localhost:8000/v1/models”查看model名称,可以看到和Vllm启动Qwen3-0.6B服务时指定的--model参数不一样,我的是“/home/ubuntu/.cache/modelscope/hub/models/Qwen/Qwen3-0.6B”, curl命令更改成:
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "/home/ubuntu/.cache/modelscope/hub/models/Qwen/Qwen3-0.6B",
"messages": [
{"role": "system", "content": "你是一名科技领域专家"},
{"role": "user", "content": "请解释Transformer架构的核心思想"}
],
"max_tokens": 200,
"top_p": 0.9
}'
可以正常返回。

至此,vllm已经正常部署起Qwen3-0.6B了。

电影级数字人,免显卡端渲染SDK,十行代码即可调用,工业级demo免费开源下载!
更多推荐



 18
18 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)