
CVPR 2024敲门砖丨多模态大模型 + 跨域适配直接拿下顶会
多模态是一种融合文本、图像、音频、视频等异构数据形式进行智能处理的技术范式,通过整合不同感官模态的信息,模仿人类多维度认知世界的方式,旨在构建更完整、准确且贴近真实场景的智能系统。目前,多模态技术已深度渗透至生成式 AI、工业质检、医疗影像诊断、智慧教育等领域,展现出融合创新驱动通用人工智能发展的巨大潜力。
关注gongzhonghao【CVPR顶会精选】
多模态是一种融合文本、图像、音频、视频等异构数据形式进行智能处理的技术范式,通过整合不同感官模态的信息,模仿人类多维度认知世界的方式,旨在构建更完整、准确且贴近真实场景的智能系统。
目前,多模态技术已深度渗透至生成式 AI、工业质检、医疗影像诊断、智慧教育等领域,展现出融合创新驱动通用人工智能发展的巨大潜力。今天小图给大家精选3篇CVPR有多模态方向的论文,请注意查收!
论文一:MoST: Multi-modality Scene Tokenization for Motion Prediction
方法:
文章首先通过预训练的2D图像模型和3D点云模型对场景进行分解,将场景中的地面、代理和开放集对象转化为具有语义和几何信息的“标记”。接着,利用这些标记将多模态信息高效地表示为几百个标记,并将其输入到基于Transformer的运动预测模型中。最后,在Waymo Open Motion Dataset上进行实验,证明了该方法相比现有技术在性能上的显著提升。
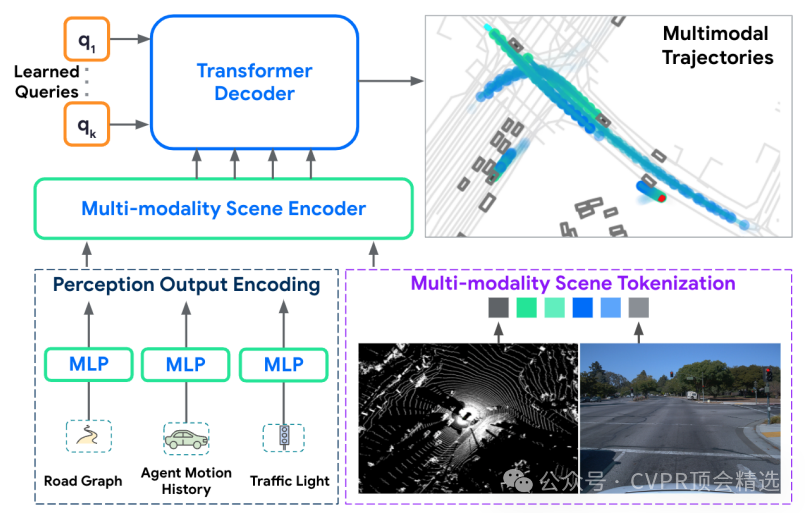
创新点:
-
提出了将视觉世界分解为紧凑的场景元素集合,并利用预训练的图像基础模型和LiDAR神经网络以开放词汇的方式对场景元素进行编码。
-
增强了Waymo Open Motion Dataset,使其成为一个支持端到端学习研究的大规模多模态数据集。
-
在多种复杂场景下验证了模型的鲁棒性和准确性,提高了模型的性能。
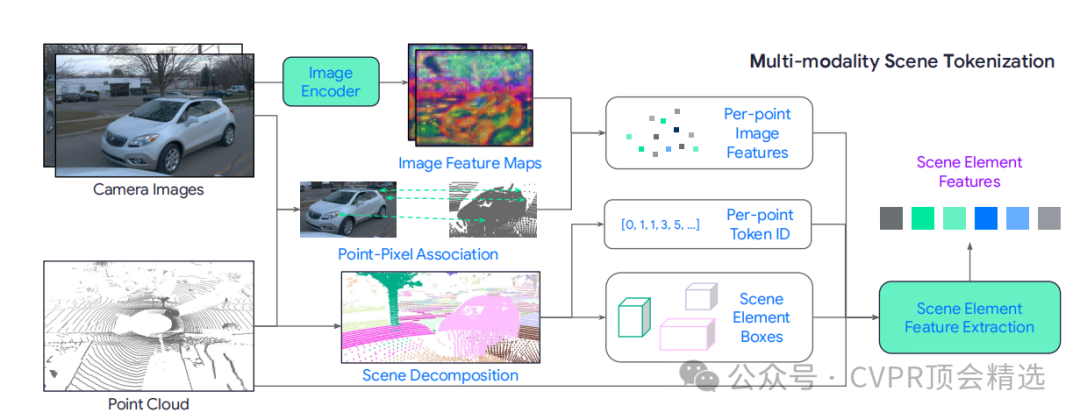
论文链接:
https://arxiv.org/abs/2404.19531
图灵学术论文辅导
论文二:OVMR: Open-Vocabulary Recognition with Multi-Modal References
方法:
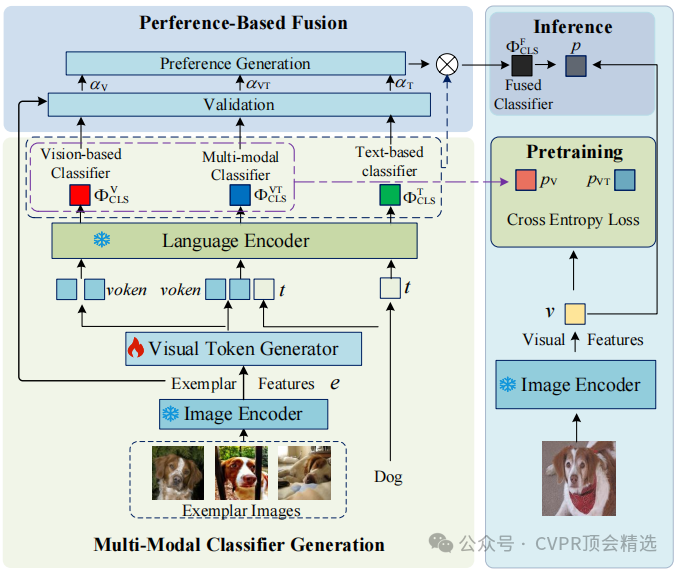
文章首先利用预训练的语言编码器和轻量级的视觉标记生成器,将文本描述和示例图像融合生成多模态分类器。接着,通过在示例图像上验证不同分类器的性能,动态生成融合权重,进一步优化分类器的性能。最后,该方法被灵活地应用于开放词汇分类和检测任务,在多个数据集上验证了其优越性能。
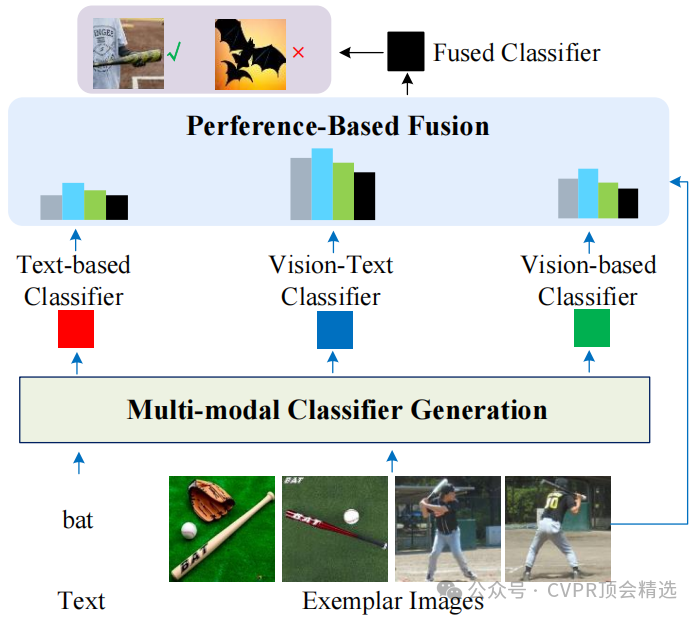
创新点:
-
提出了一个多模态分类器生成模块,通过动态融合文本描述和图像示例,生成更具鲁棒性的分类器。
-
引入了一种基于偏好的融合模块,有效缓解了低质量文本或图像示例带来的负面影响。
-
该方法是一个即插即用的模块,在多种场景和设置下均展现出优异的性能。
论文链接:
https://arxiv.org/abs/2406.04675
图灵学术论文辅导
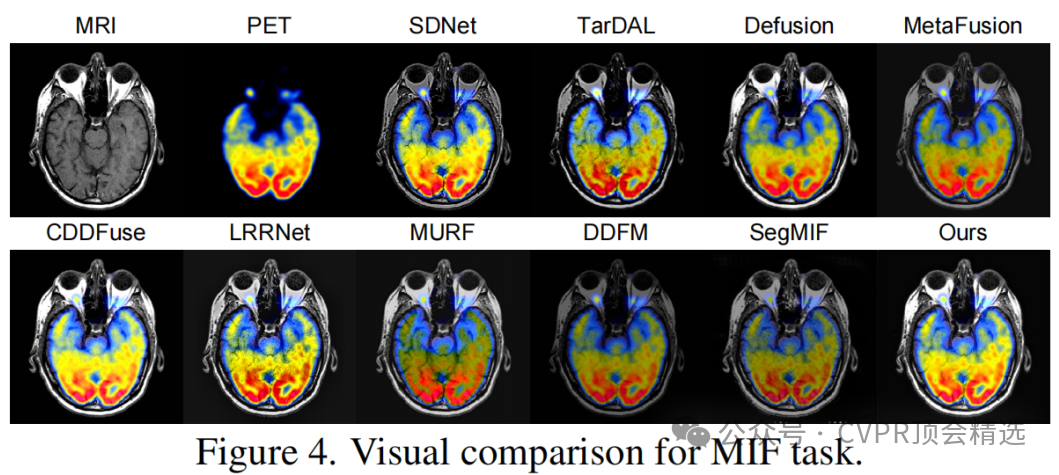
论文三:Equivariant Multi-Modality Image Fusion
方法:
文章首先构建了一个基于U-Net结构的融合模块U-Fuser,用于从多模态输入中提取和融合信息。接着,通过伪感知模块将融合图像映射回源图像,模拟感知成像过程,并利用等变性先验约束学习过程。最后,通过设计的损失函数优化整个框架,确保融合图像在满足感知一致性和等变性的同时,能够有效地整合源图像的特征。
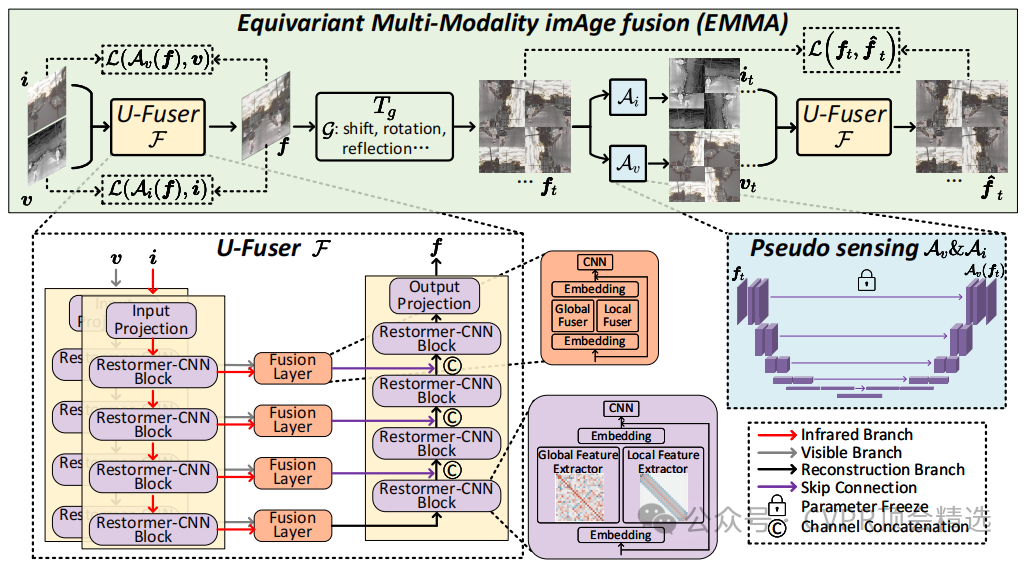
创新点:
-
提出了一种新颖的自监督学习范式EMMA,无需真实融合图像即可进行训练。
-
设计了一个包含融合模块、伪感知模块和等变融合模块的完整框架,能够有效保留源图像信息。
-
引入了Restormer-CNN块的U-Fuser模块,能够高效地融合多尺度的全局和局部特征,生成高质量的融合图像。
论文链接:
https://arxiv.org/abs/2305.11443
本文选自gongzhonghao【CVPR顶会精选】

电影级数字人,免显卡端渲染SDK,十行代码即可调用,工业级demo免费开源下载!
更多推荐

 44
44 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)