
CIKM 2025 中国科技大学&华盛顿大学提出:通过文本增强提升多模态时序预测!
本文的研究结论非常明确:在多模态时间序列预测中,文本模态的质量至关重要。作者提出的TeR-TSF框架,通过一个由强化学习优化的LLM,将低质量的原始文本“提纯”为高质量的强化文本。这个强化文本不仅语义上与任务更相关,还能为预测模型提供关于数据动态的深刻洞见。实验证明,这种“先增强、再融合”的策略,能够稳定且显著地提升预测的准确性,效果超越了当前许多先进的方法。
在日常生活中,我们经常需要预测未来,比如明天的天气或者下个月的股票价格。传统的预测方法通常只看历史数据,比如只看过去一周的股价来预测明天的股价。但这样做信息太单一,容易遇到瓶颈。现在的研究发现,如果能结合相关的文本信息(比如新闻、分析报告),预测会更准。然而,现实世界中的文本数据往往质量不高,可能内容不全、有错误,或者和数据对不上号,这反而会误导预测模型。
为了解决这个问题,本文提出了一个名为TeR-TSF的智能框架。它使用一个大型语言模型(Large Language Models, LLMs)来读取原始的时间序列数据和附带的文本,然后“重写”和“增强”这些文本,生成一份质量更高、内容更相关的强化文本。通过一种强化学习(reinforcement learning)的训练方式,模型不断学习如何生成能最大程度提升预测准确率的文本。最终,这个方法在多个领域的真实数据集上都取得了比现有顶尖方法更好的预测效果。
另外我整理了ACMMM 2025 论文+源码合集,感兴趣的自取!
论文基本信息

- 论文标题:Text Reinforcement for Multimodal Time Series Forecasting
- 作者姓名与单位:Chen Su,Yuanhe Tian,Yan Song,Yongdong Zhang
- 论文链接:https://arxiv.org/pdf/2509.00687
- 代码链接:https://github.com/synlp/TeR-TSF
主要贡献与创新
- 首次提出了一个文本增强框架(TeR-TSF),专门用于解决多模态时间序列预测中,文本数据质量不佳导致性能不稳定的问题。
- 创新性地采用了基于强化学习的优化策略,特别是直接偏好优化(DPO),来指导大语言模型生成对下游预测任务最有益的文本。
- 设计了一个双重奖励函数,它同时考虑了预测结果的准确度和生成文本与任务的相关性,确保了强化文本的质量和可解释性。
- 在包含八个不同领域的真实世界基准数据集上进行了全面的实验,结果证明该方法显著优于现有的多种先进模型。
研究方法与原理
该论文提出的模型核心思路是:利用一个大语言模型(TeR)先对原始文本进行“加工和提炼”,生成更有价值的强化文本,再将这份高质量的文本与时间序列数据一同送入预测模型,从而得到更准确的预测结果。
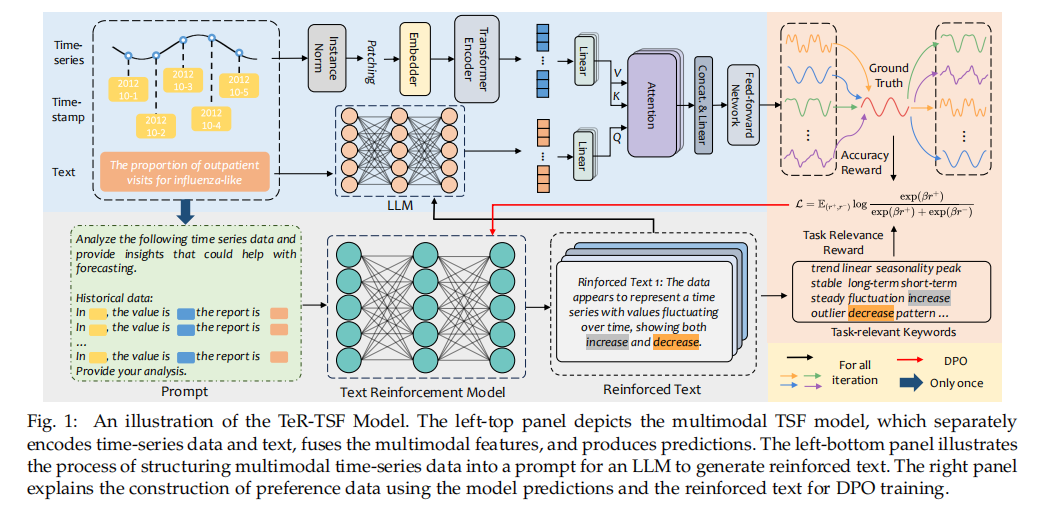
整个流程可以分解为三个主要模块:文本增强、多模态预测和强化学习优化。
1. 文本增强 (Text Reinforcement)
这个模块的目标是生成高质量的强化文本 E aug E_{\text{aug}} Eaug。考虑到LLMs更擅长处理文本而非纯数字,研究者首先将时间序列数据 S S S 转化为文本格式。具体来说,数值被转换为保留四位小数的文本字符串 S txt S_{\text{txt}} Stxt,并辅以包含均值、方差等统计特征的描述性文本 A txt A_{\text{txt}} Atxt。然后,将处理后的时间序列文本( S txt S_{\text{txt}} Stxt 和 A txt A_{\text{txt}} Atxt)、原始附带文本 E E E 以及任务指令 P P P(例如,“请根据以上信息进行预测分析”)拼接在一起,形成一个完整的提示(Prompt)。这个提示被输入到作为文本增强模型 (TeR) 的LLM中,生成最终的强化文本 E aug E_{\text{aug}} Eaug。
E aug = f TeR ( S txt , A txt , E , P ) E_{\text{aug}} = f_{\text{TeR}}(S_{\text{txt}}, A_{\text{txt}}, E, P) Eaug=fTeR(Stxt,Atxt,E,P)
通过这个过程,LLM能够综合理解数值波动和现有文本信息,生成对时间序列动态有更深刻洞察的描述。
2. 使用强化文本进行多模态时序预测
得到强化文本 E aug E_{\text{aug}} Eaug 后,它将和原始的时间序列数据 S S S 一起被送入一个多模态预测模型 f TSF f_{\text{TSF}} fTSF,以预测未来 H H H 个时间步的值 Y ^ \hat{Y} Y^。
Y ^ = f TSF ( S , E aug ) \hat{Y} = f_{\text{TSF}}(S, E_{\text{aug}}) Y^=fTSF(S,Eaug)
该预测模型 f TSF f_{\text{TSF}} fTSF 的内部结构如下:
- 时间序列编码:采用PatchTST模型,它将时间序列数据分割成小块(Patches),然后通过Transformer编码器捕捉序列中的长期和短期依赖关系,得到编码后的时间序列表示 S \mathcal{S} S。
S = PatchTST ( S ) \mathcal{S} = \text{PatchTST}(S) S=PatchTST(S) - 文本编码:使用另一个LLM的嵌入层将强化文本 E aug E_{\text{aug}} Eaug 转换为一系列向量表示 { e i } \{e_i\} {ei},然后通过简单的平均池化得到整个文本的聚合表示 e e e。
e = 1 n ∑ i = 1 n e i e = \frac{1}{n} \sum_{i=1}^{n} e_i e=n1i=1∑nei - 多模态融合:为了让文本信息和时间序列信息相互作用,模型采用了一个交叉注意力机制(cross-attention)。在这里,文本表示 e e e 作为查询(Query),时间序列表示 S \mathcal{S} S 同时作为键(Key)和值(Value)。这样,模型可以根据文本的引导,从时间序列中提取最相关的信息,融合成一个统一的表示 z z z。
z = CrossAttention ( e , S , S ) z = \text{CrossAttention}(e, \mathcal{S}, \mathcal{S}) z=CrossAttention(e,S,S) - 最终预测:融合后的向量 z z z 经过一个前馈神经网络,最终输出对未来时间序列的预测值 Y ^ \hat{Y} Y^。
3. 基于强化学习的优化
这是整个框架的精髓所在。为了让TeR模型学会生成“好”的强化文本,研究者设计了一套基于奖励的优化流程。
奖励计算 (Reward Computation)
这里的“好”体现在两个方面,因此设计了两个奖励信号:
- 预测准确度奖励 ( r 1 r_1 r1):这个奖励直接与最终的预测效果挂钩。它通过计算预测值 Y ^ \hat{Y} Y^ 和真实值 Y Y Y 之间的均方误差(mean squared error, MSE)来衡量。MSE越小,表示预测越准,奖励值就越高。为了方便优化,奖励被定义为负的MSE。
r 1 = − 1 H ∑ i = 1 H ( Y i − Y ^ i ) 2 r_1 = -\frac{1}{H} \sum_{i=1}^{H} (Y_i - \hat{Y}_i)^2 r1=−H1i=1∑H(Yi−Y^i)2 - 任务相关性奖励 ( r 2 r_2 r2):这个奖励确保生成的文本在语言上是“靠谱”的,即包含与时间序列分析相关的专业词汇。研究者预先定义了一个关键词集合 K K K(如 “趋势”、“峰值”、“波动” 等),然后计算生成的文本中包含这些关键词的比例。
r 2 = ∑ w ∈ W I ( w ∈ K ) ∣ K ∣ r_2 = \frac{\sum_{w \in W} I(w \in K)}{|K|} r2=∣K∣∑w∈WI(w∈K)
其中 I ( ⋅ ) I(\cdot) I(⋅) 是一个指示函数,如果关键词 w w w 出现在文本中,则为1,否则为0。最终的总奖励 r r r 是这两个奖励的加权和。
使用DPO进行训练
在每个训练迭代中,TeR模型针对同一份输入数据生成 k k k 个不同的强化文本候选。然后,奖励模型为每个候选文本计算总奖励分数。得分最高和最低的文本分别被标记为正例 ( E aug + E_{\text{aug}}^+ Eaug+) 和负例 ( E aug − E_{\text{aug}}^- Eaug−),形成一个偏好对。
接着,使用直接偏好优化(direct preference optimization, DPO)算法来微调TeR模型。DPO的核心是最大化模型生成正例的概率,同时最小化生成负例的概率。其损失函数如下:
L = E ( r + , r − ) log exp ( β r + ) exp ( β r + ) + exp ( β r − ) \mathcal{L} = \mathbb{E}_{(r^+, r^-)} \log \frac{\exp(\beta r^+)}{\exp(\beta r^+) + \exp(\beta r^-)} L=E(r+,r−)logexp(βr+)+exp(βr−)exp(βr+)
这里的 r + r^+ r+ 和 r − r^- r− 分别是正例和负例的奖励, β \beta β 是一个温度系数。通过最小化这个损失,TeR模型被引导着去生成更可能获得高奖励的文本。这个过程循环进行,使得TeR模型生成强化文本的质量越来越高。
实验设计与结果分析
实验设置
- 数据集:实验使用了公开的Time-MMD基准数据集,它涵盖了农业、气候、经济、能源、环境、健康、社会和交通等八个不同领域。该数据集的特点是文本数据存在稀疏和不相关的问题,非常适合验证本文方法的有效性。
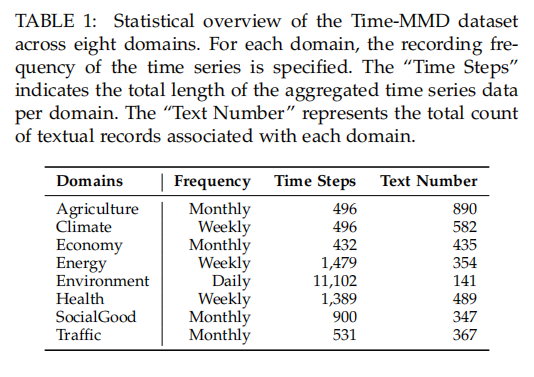
- 评测指标:使用均方误差(MSE) 和 平均绝对误差(MAE) 作为评估预测性能的指标,这两个指标都是值越低越好。
整体结果 (Overall Results)
对比实验:
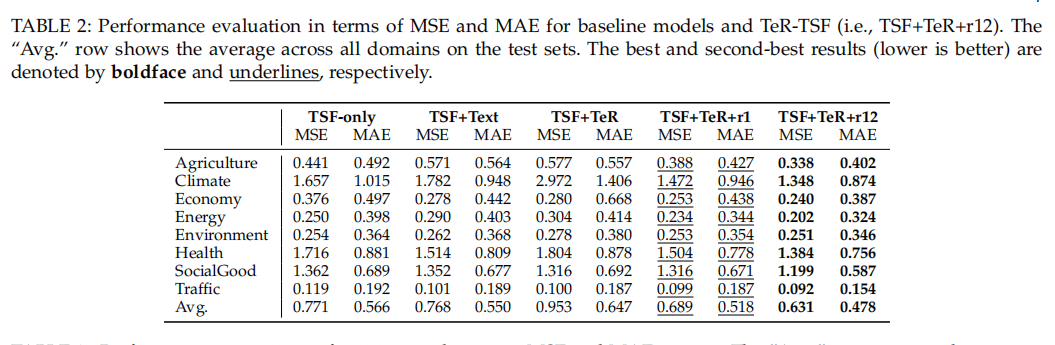
通过与多个基线模型的对比可以发现:
- 简单地加入原始文本(TSF+Text)相较于只用时间序列(TSF-only),平均性能略有提升,但在某些领域效果甚至变差,说明原始文本质量参差不齐。
- 直接用未经优化的LLM生成文本(TSF+TeR)效果最差,证明了无引导的生成会引入噪声,反而有害。
- 引入了基于预测准确度奖励的强化学习(TSF+TeR+r1)后,性能得到显著提升,超过了仅使用原始文本的方法。
- 完整的TeR-TSF模型(TSF+TeR+r12)在加入了任务相关性奖励后,取得了最佳性能,证明双重奖励机制能更好地指导LLM生成高质量文本。
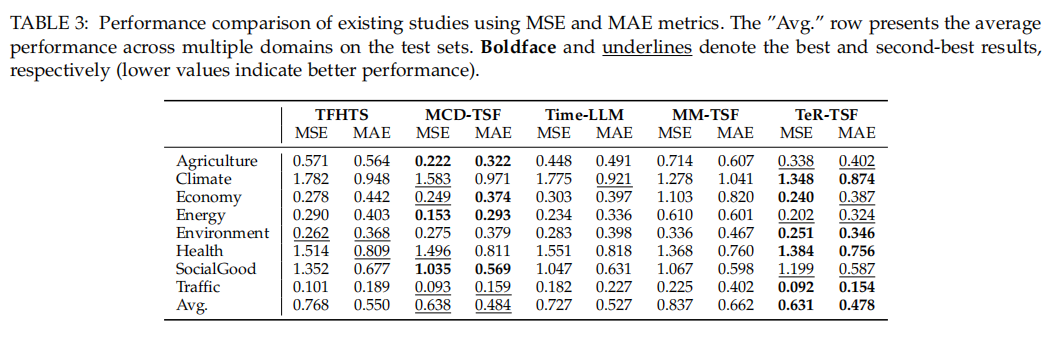
与现有顶尖的多模态预测模型(如TFHTS、MCD-TSF、Time-LLM)相比,TeR-TSF在八个领域的平均MSE和MAE均为最低或次低,综合性能排名第一。这充分证明了通过主动增强文本质量来提升预测性能的策略是极其有效的。
生成的强化文本数量的影响 (Effect of Generated Reinforced Text Number)
消融实验:
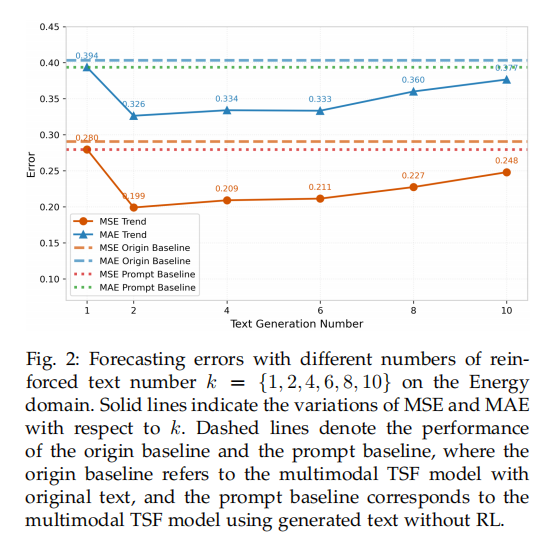
这部分实验探究了在DPO训练中,每次迭代生成候选文本的数量 k k k 对模型性能的影响。结果显示,当 k k k 从1增加到2时,模型性能显著提升,因为 k = 2 k=2 k=2 才能构成偏好对进行DPO训练。然而,当 k k k 继续增大时,性能反而下降。研究者认为,这是因为生成更多文本时会产出更多低质量样本,导致正负例的奖励差距过大,使得模型在优化时“步子迈得太大”,忽略了中间质量的样本,不利于精细学习。因此, k = 2 k=2 k=2 是最佳选择 。
强化学习轮数的影响 (Effect of RL Rounds)
消融实验:
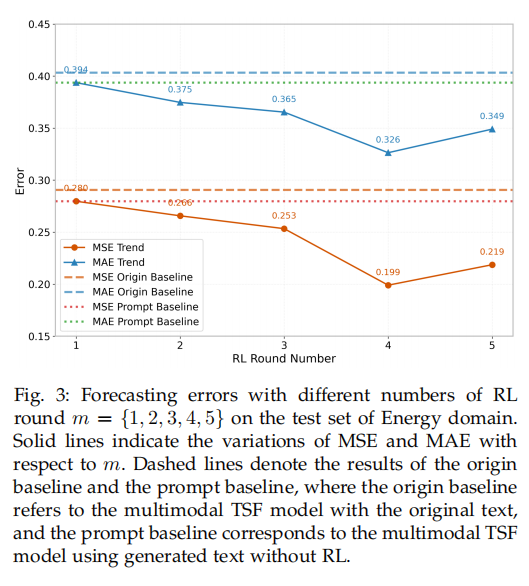
实验探究了强化学习训练轮数 m m m 的影响。结果显示,随着训练轮数的增加,模型性能先是持续提升,在 m = 4 m=4 m=4 时达到最佳。这表明适当的训练能让模型充分学习文本生成的策略。但当 m > 4 m>4 m>4 时,性能开始下降,这是典型的过拟合现象,即模型过度学习了训练数据中的偏好,导致泛化能力变差。
文本增强LLM的影响 (Effect of Text Enhanced LLM)
消融实验与可视化对比:
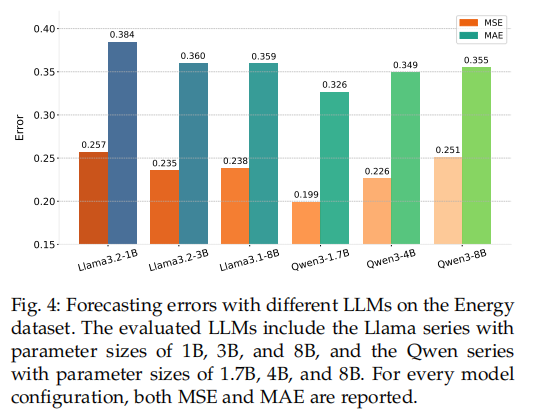
实验比较了使用不同大小的Llama和Qwen系列LLM作为TeR模型时的性能。有趣的是,并非模型越大越好。Qwen3-1.7B模型取得了最佳效果。这可能是因为时间序列预测任务的数据规模远小于LLM预训练时的海量文本,过大的模型更容易在该任务上过拟合。
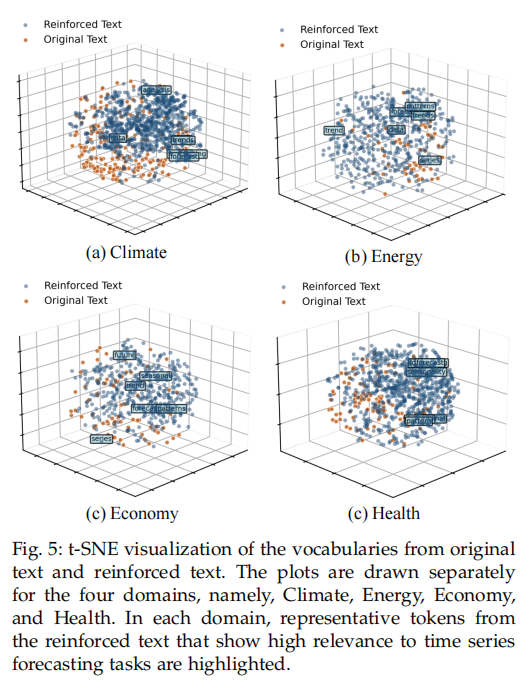
通过t-SNE可视化可以发现,原始文本中的词汇和强化文本中的词汇在向量空间中形成了两个泾渭分明的簇。这表明TeR模型确实对文本的分布进行了重构。更重要的是,在强化文本的簇中,出现了大量如“trend (趋势)”、“seasonality (季节性)”、“fluctuation (波动)”等与时间序列分析高度相关的词汇,这直观地证明了我们的方法成功地将无关信息过滤掉,并生成了对预测任务更有价值的文本内容。
案例分析 (Case Study)
可视化对比:
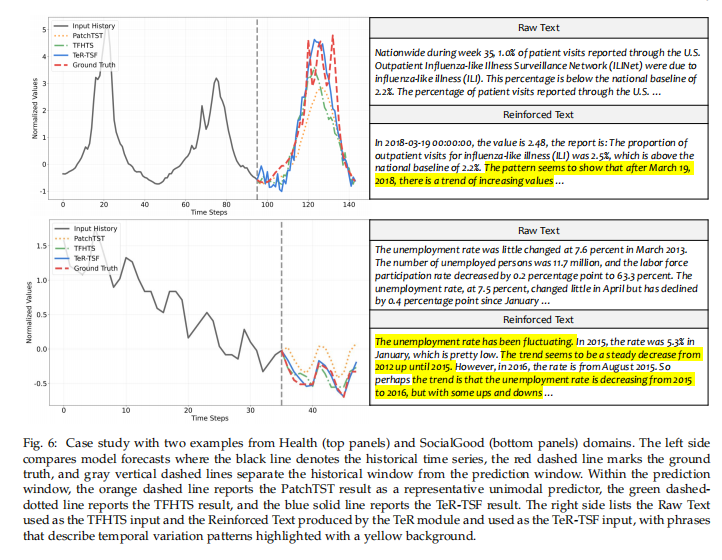
在健康和社会公益两个领域的案例中,可以清晰地看到:
- 只用时间序列的PatchTST模型预测偏差较大。
- 加入了原始文本的TFHTS模型预测曲线更贴近真实值,说明文本确实有帮助。
- 使用了强化文本的TeR-TSF模型预测曲线几乎与真实值完美贴合,效果最好。
通过对比左右两侧的文本可以发现,原始文本只是对过去事实的简单陈述,而TeR-TSF生成的强化文本则对历史数据的变化模式进行了分析和总结(如“失业率一直在波动”、“呈稳步下降趋势”),为预测模型提供了更有深度的洞察。
论文结论与评价
总结
本文的研究结论非常明确:在多模态时间序列预测中,文本模态的质量至关重要。作者提出的TeR-TSF框架,通过一个由强化学习优化的LLM,将低质量的原始文本“提纯”为高质量的强化文本。这个强化文本不仅语义上与任务更相关,还能为预测模型提供关于数据动态的深刻洞见。实验证明,这种“先增强、再融合”的策略,能够稳定且显著地提升预测的准确性,效果超越了当前许多先进的方法。
评价
这项研究为多模态学习领域提供了一个非常有价值的新思路。它告诉我们,当一个模态的数据质量不高时,我们不应仅仅被动地接受或降低其在模型中的权重,而可以主动地利用其他模态的信息去增强它。
优点:
- 创新性强:将强化学习中的DPO算法巧妙地应用于文本生成,并以预测任务的性能作为奖励信号,构成了高效的闭环优化系统。
- 实用性高:直面了真实世界中多模态数据质量不佳的痛点,提出的方法具有很强的实践意义。
- 效果显著:在多个领域的实验中都验证了方法的优越性,鲁棒性好。
缺点:
- 计算成本高:整个流程涉及多次调用LLM进行生成和微调,相比传统模型,训练和推理的开销会大得多。
- 奖励设计有局限:任务相关性奖励依赖于一个预定义的关键词列表,这需要一定的领域知识,并且可能不够全面。
批判性讨论与建议:
这篇论文的方法虽然有效,但其效率和自动化程度仍有提升空间。一个可能的改进方向是探索更自动化的奖励机制,例如,可以训练一个判别器模型来评估文本质量,而不是依赖手动设定的关键词。此外,未来可以研究如何用更轻量级的模型或者更高效的微调技术(如LoRA之外的其他方法)来降低计算成本,从而让这个强大的框架更容易在实际应用中部署。总的来说,这项工作为处理不完美多模态数据开辟了新的道路,极具启发性。

电影级数字人,免显卡端渲染SDK,十行代码即可调用,工业级demo免费开源下载!
更多推荐

 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)