
AAAI2025 Oral | ChatTime:零样本 + 多模态,时间序列分析进入多模态时代!
AAAI2025的Oral文章,最新前沿时序技术,文章提出一种统一多模态时间序列基础模型—ChatTime,模型能桥接数值型和文本型数据,解决传统时间序列分析方法的局限性~
本篇论文来自AAAI2025的Oral文章,最新前沿时序技术,文章提出一种统一多模态时间序列基础模型—ChatTime,模型能桥接数值型和文本型数据,解决传统时间序列分析方法的局限性~
顶会优秀技术都值得学习,最新全部55篇AAAI2025前沿时序技术小时已经整理好了,关注工🀄昊“时序大模型”发送“资料”扫码回复“AAAI2025时序合集”即可自取~其他顶会的前沿时序合集也可发送关键词自取哦~
文章信息
论文名称:ChatTime: A Unified Multimodal Time Series Foundation Model Bridging Numerical and Textual Data
论文作者:Chengsen Wang,Qi Qi,Jingyu Wang,Haifeng Sun,Zirui Zhuang,Jinming Wu,Lei Zhang,Jianxin Liao

研究背景
传统的方法存在缺陷,多数深度学习预测模型仅依赖单模态数值数据,且基于固定长度窗口在单一数据集上训练,无法适应不同场景;同时,现有方法难以处理文本信息,缺乏零样本预测能力。
预训练大语言模型通过自回归预训练在文本任务中表现出色,但现有时间序列基础模型存在训练效率低、不支持文本处理或零样本能力不足等问题。
因此可以将时间序列视为一种 “外语”,构建支持时间序列与文本双向输入输出的多模态模型,实现零样本推理。
由此提出了一种名为ChatTime的统一多模态时间序列基础模型,以解决这些问题。
模型框架
核心概念:通过归一化、离散化和添加标记字符(如###),将连续时间序列转换为离散 “外语词汇”,扩展 LLM 的词汇表以支持时间序列处理。
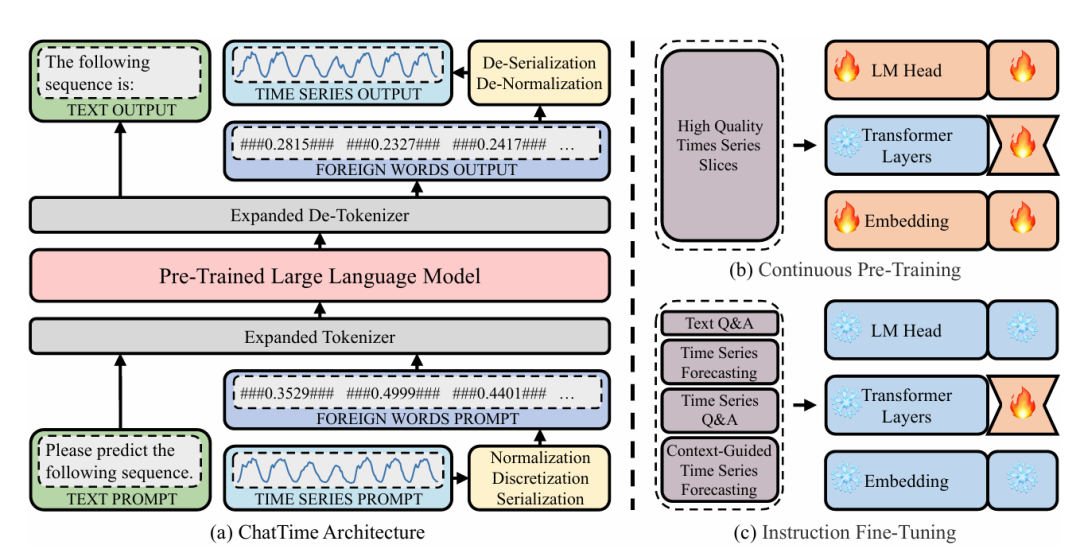
训练过程:
-
持续预训练:使用 100 万个高质量时间序列切片对 LLaMA-2-7B 模型进行预训练,学习时间序列的基本规律。
-
指令微调:结合 4 个任务数据集(文本问答、单模态时间序列预测、上下文引导预测、时间序列问答),微调模型以支持多模态任务。

ChatTime的5个亮点:
-
多模态融合:将时间序列视为 “外语”,支持时间序列与文本的双向输入输出,能结合数值数据与文本信息(如天气、政策等)进行分析。
-
零样本能力:无需针对特定场景重新训练,可直接进行跨数据集、跨任务的预测和问答。
-
高效训练:基于现有预训练大语言模型扩展词汇表,通过持续预训练和指令微调优化,无需从头训练,降低计算成本。
-
缺失值处理:引入 “###Nan###” 标记专门处理时间序列中的缺失数据。
-
任务扩展性:可胜任零样本预测、上下文引导预测、时间序列问答等多种任务,适用范围广。
实验数据
构建的数据集:
-
3 个上下文引导时间序列预测数据集(墨尔本太阳能发电、伦敦电力使用、巴黎交通流量)。
-
1 个时间序列问答数据集(涵盖趋势、波动性、季节性、异常值 4 类特征)。
评估任务:
-
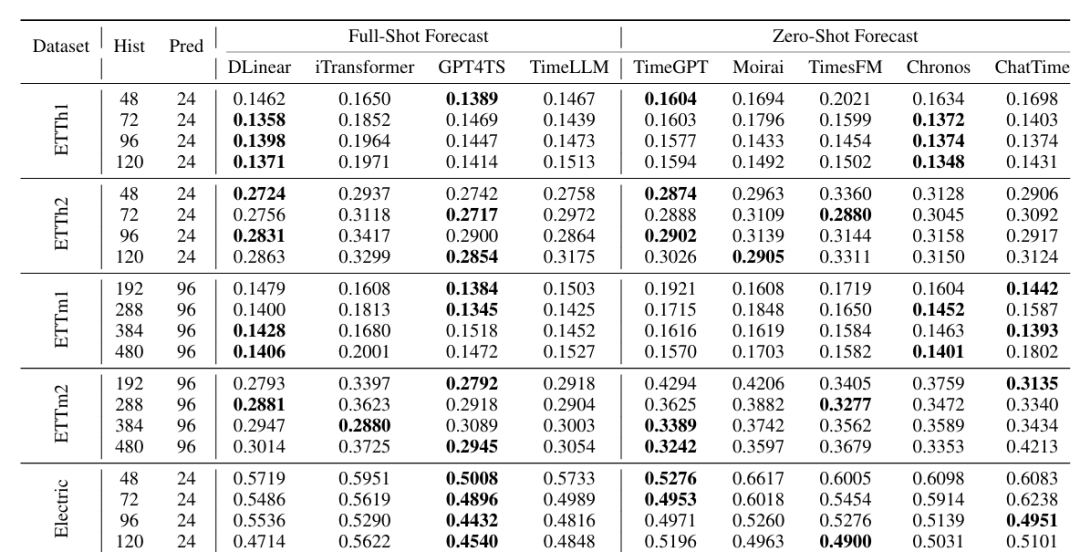
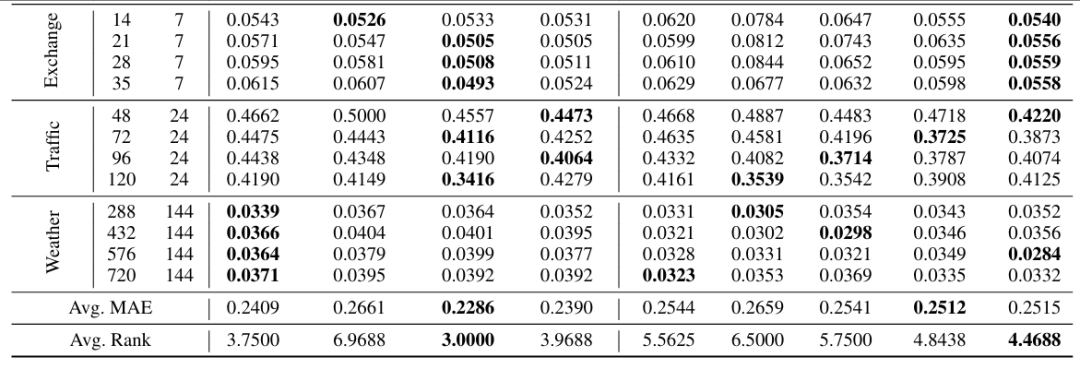
零样本时间序列预测:在 8 个真实世界基准数据集(如电力、汇率、交通)上验证,平均 MAE 接近现有最优模型 Chronos,且训练数据仅为其 4%。
-
上下文引导预测:结合文本辅助信息(如天气、日期),性能优于单模态模型和数据集专用模型,验证了文本信息的增益。
-
时间序列问答:在 4 类特征识别任务中,平均准确率(76.05%)显著高于 GPT4、GLM4 等通用 LLM,证明其对时间序列的深度理解能力。
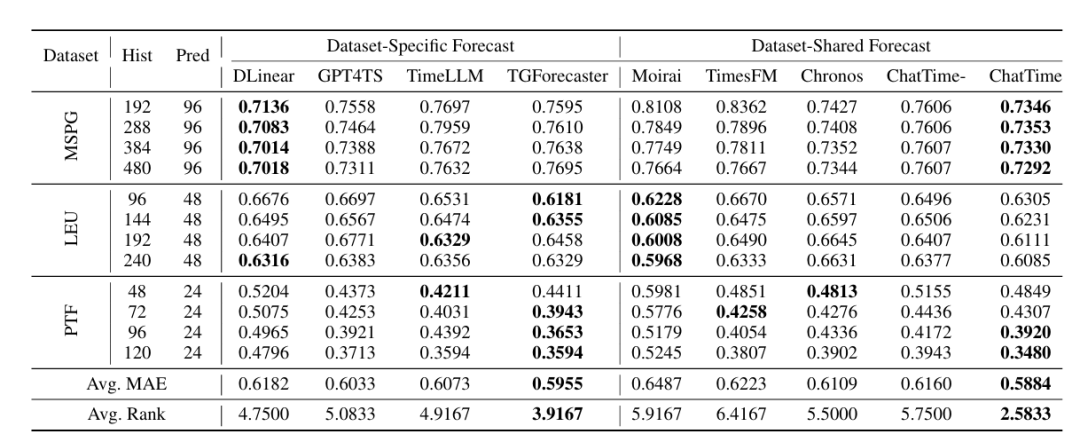
结果对比:
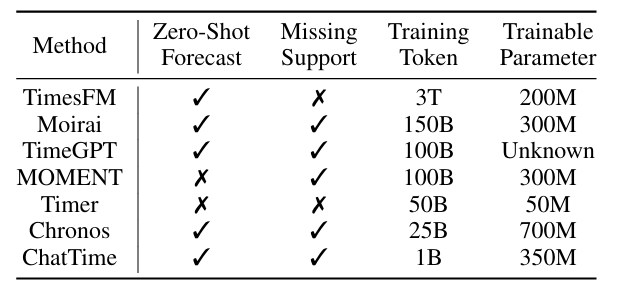
与同类模型对比:ChatTime 在零样本预测、缺失值支持、训练成本(1B token)和参数规模(350M)上综合占优。
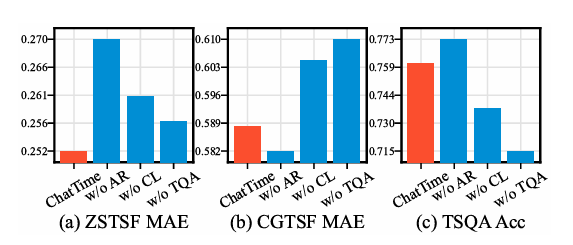
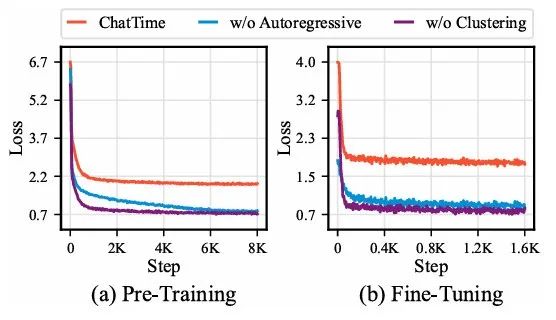
消融实验:验证了自回归预训练、聚类采样高质量数据、文本问答微调对模型性能的必要性。
小小总结
文章构建了支持零样本推理和双模态输入输出的 ChatTime 模型;建立了相关多模态数据集填补领域空白;通过全面实验证明了 ChatTime 在多个时间序列任务中的优势,为时间序列分析提供了创新视角和解决方案~
全部55篇AAAI2025前沿时序技术小时都整理好了~欢迎关注工🀄昊“时序大模型”发送“资料”扫码回复“AAAI2025时序合集”自取~其他顶会前沿时序合集也可以回复对应会议名自取哈(ICML25,ICLR25,ICDE25)

关注小时,持续学习前沿时序技术!

电影级数字人,免显卡端渲染SDK,十行代码即可调用,工业级demo免费开源下载!
更多推荐

 34
34 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)