
【具身智能】GR00T N1:通用人形机器人开放基础模型
核心贡献公开了 GR00T-N1-2B 模型权重、训练数据、仿真环境(GitHub+HuggingFace),降低通用机器人研究门槛;技术突破:双系统 VLA 架构解决 “推理慢 + 动作笨” 的矛盾,数据金字塔解决 “数据稀缺”,为后续通用机器人模型提供范式;落地验证:在真实 GR-1 人形机器人上实现 “语言指令控制双手操作”,证明基础模型在人形机器人上的可行性。局限性任务范围:目前仅支持 “
GR00T N1:通用人形机器人开放基础模型
关键词:#具身智能 #VLA #双系统 #人形机器人
- 论文题目:GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
- arXiv:2503.14734
- 单位:NVIDIA
- https://developer.nvidia.com/isaac/gr00t
- 更多论文每日解读关注 v 公众号:https://mp.weixin.qq.com/s/vw4NXRffLgg0WvaprdzWJQ

论文速读
GR00T N1 是 NVIDIA 推出的一个用于通用人形机器人的开放基础模型,其研究目标:
- 构建一个通用的机器人基础模型,让人形机器人能在复杂、多变的人类环境中理解语言指令、感知环境并执行动作。
- 解决机器人数据稀缺的问题,提出异构数据训练策略(包括真实机器人数据、人类视频、合成数据等)。
GR00T N1 希望让不同形态的机器人(从单臂到人形)都能复用同一套 “智能大脑”,且用少量数据就能快速适应新任务。
GR00T N1 模型架构
双系统架构
GR00T N1 的核心是双系统架构(灵感来自于“快慢思考”理论),两个系统端到端联合训练,兼顾 “理解任务” 和 “流畅动作”。
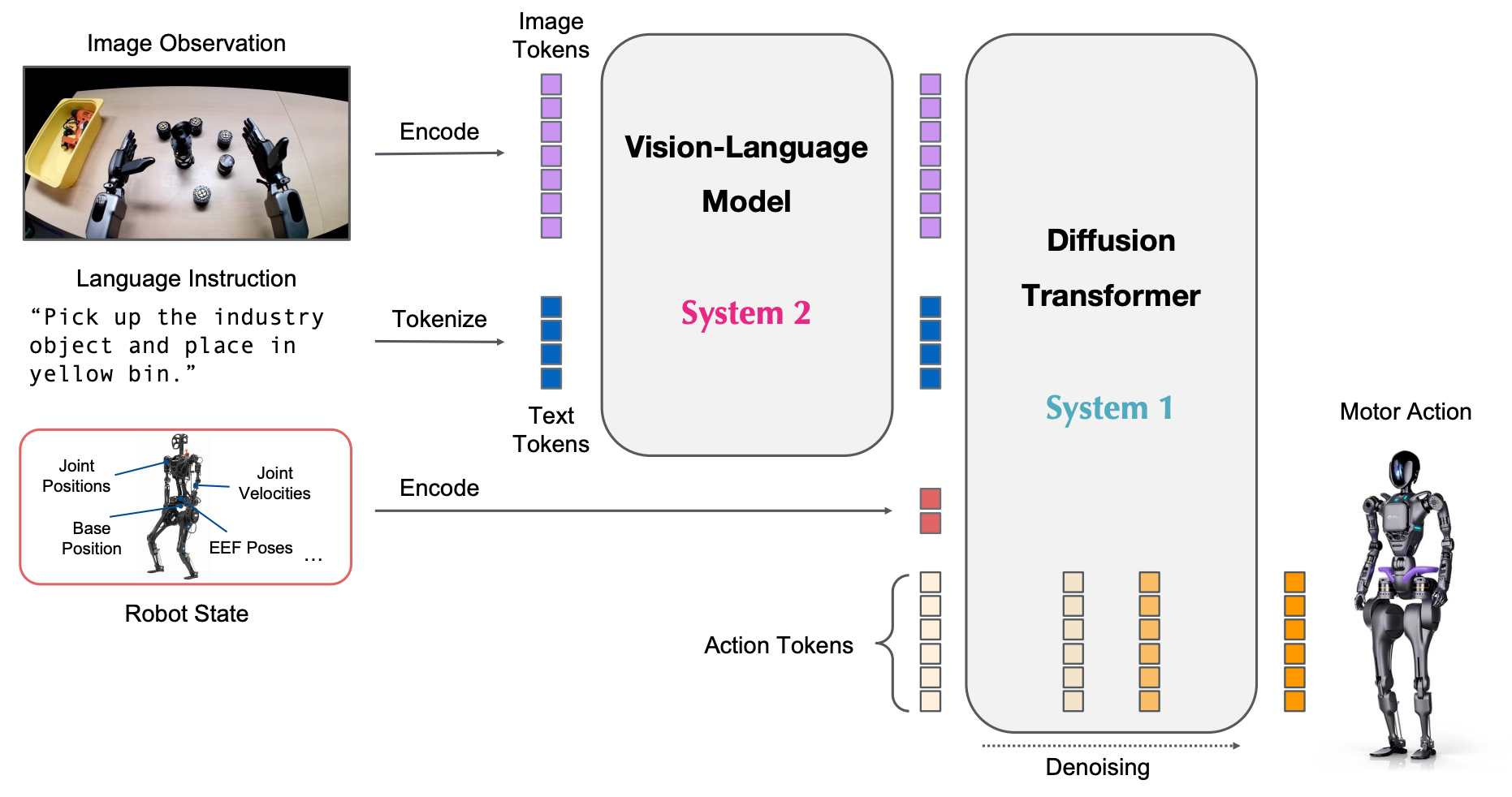
图像观察与语言指令转换为一个 token 序列,供 VLM 主干处理,VLM 的输出与机器人状态和动作编码一起传递给 Diffusion Transformer 模块来生成电机动作。
| 系统 | 核心功能 | 技术方案 | 运行频率 | 作用 |
|---|---|---|---|---|
| System 2(慢思考) | 理解环境与任务 | 预训练视觉语言模型(Eagle-2 VLM) | 10Hz | 处理 “图像 + 语言指令”,比如从 “拿起红色苹果放进篮子” 的指令和摄像头图像中,定位苹果 / 篮子位置,明确 “要做什么” |
| System 1(快动作) | 生成流畅电机动作 | 扩散 Transformer(DiT)+ 动作流匹配 | 120Hz | 接收 System 2 的推理结果,生成机器人关节 / 手部的实时动作,比如 “左手移动到苹果上方→握爪→抬起→递给右手→右手放进篮子” |
关键技术细节
跨形态适配(支持不同机器人)
不同机器人的 “状态 / 动作维度” 不同(比如单臂有 6 个自由度,人形有 50 + 个关节),GR00T 用专属 MLP 编码器将不同机器人的状态(关节角度、手部位置)和动作(电机指令)映射到统一特征空间,实现 “一套模型通用于所有机器人”。
通过特定投影层适配不同机器人
动作生成:用 “流匹配” 替代传统扩散
传统扩散模型生成动作慢,GR00T 用 “动作流匹配”:先给随机噪声加 “动作趋势”,再通过 4 步去噪(K=4)生成连续动作序列(每次生成 16 步动作,对应 16/120≈0.13 秒的动作规划),既保证动作流畅,又提升推理速度。
VLM 的优化
用 Eagle-2 VLM(基于 SmolLM2 语言模型 + SigLIP-2 图像编码器预训练),且特意用中间层特征(而非最后一层),既提升推理速度,又让下游动作生成更精准(实验证明成功率更高)。
数据策略
为了解决“机器人数据不够用”的问题,GR00T 提出数据金字塔策略,用 “低成本数据补高成本数据”,三层数据总时长超 8300 小时:
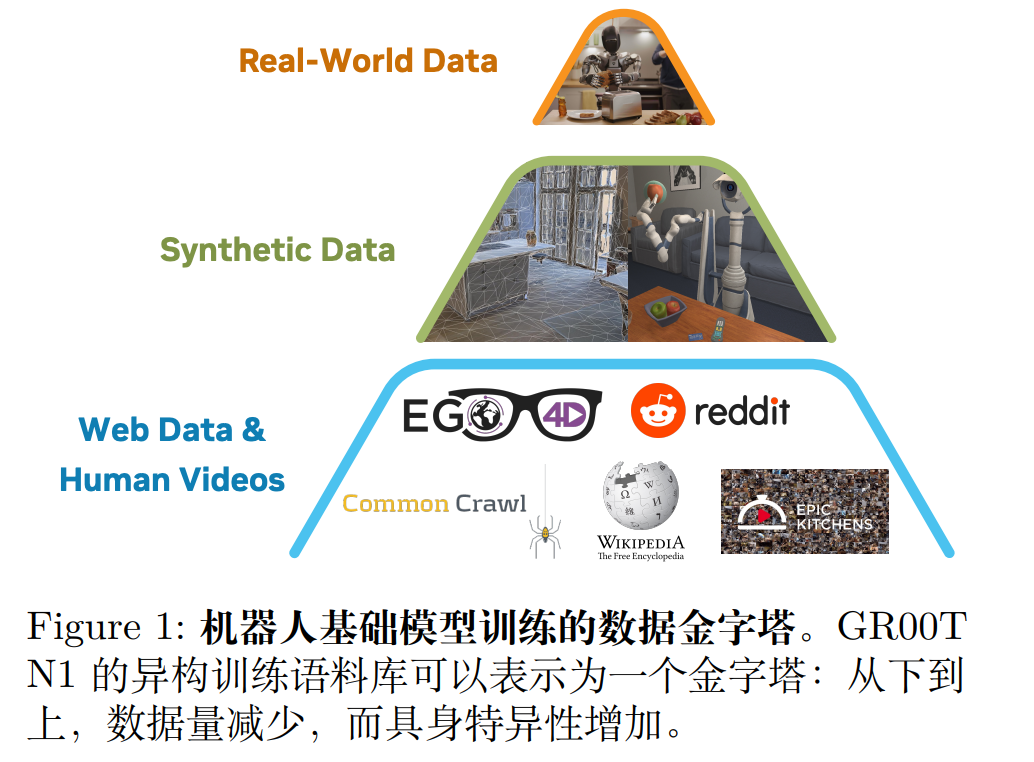
这些数据具体信息如下:

核心创新:把 “非机器人数据” 变成 “机器人可用数据”
使用潜动作学习(Latent Actions) 和逆动力学模型(IDM),从无动作视频中推断伪动作标签。
- 人类视频→潜在动作:用 VQ-VAE 编码器,输入 “当前帧 + 未来帧”,输出 “潜在动作向量”,模型能从人类开冰箱的视频中,学到 “机器人开冰箱的动作逻辑”;
- 神经轨迹→伪动作:用 IDM 模型(基于 GR00T 的 DiT 架构),从生成的视频帧反推机器人动作,让 “纯合成视频” 能直接用于训练。
具体的数据合成方法可以参考原论文。
一些 Tips:
- 由于同时控制双臂和灵巧手具有挑战性,因此为类人机器人扩展真实世界的数据采集非常昂贵。最近的一些研究表明,在仿真中生成训练数据是一种实用的替代方案。我们使用 DexMimicGen 来合成大规模机器人操作轨迹。使用 DexMimicGen,我们将有限的人类演示扩展为大规模的人形机器人操作数据集。
- 训练也是分成了“预训练”和“后训练”。
实验
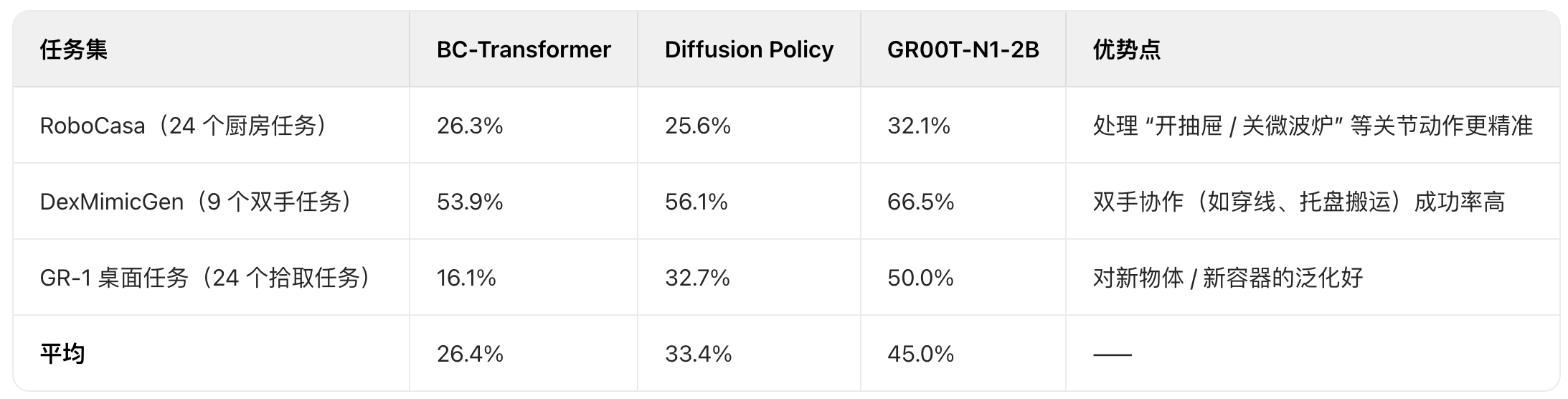
仿真基准:跨机器人形态表现
在三个仿真任务集上,GR00T-N1-2B(22 亿参数)全方面领先基线:
真实世界:GR-1 机器人测试
在 4 类真实任务中,GR00T 展现极强的数据效率(用 10% 数据就能打平基线全数据):
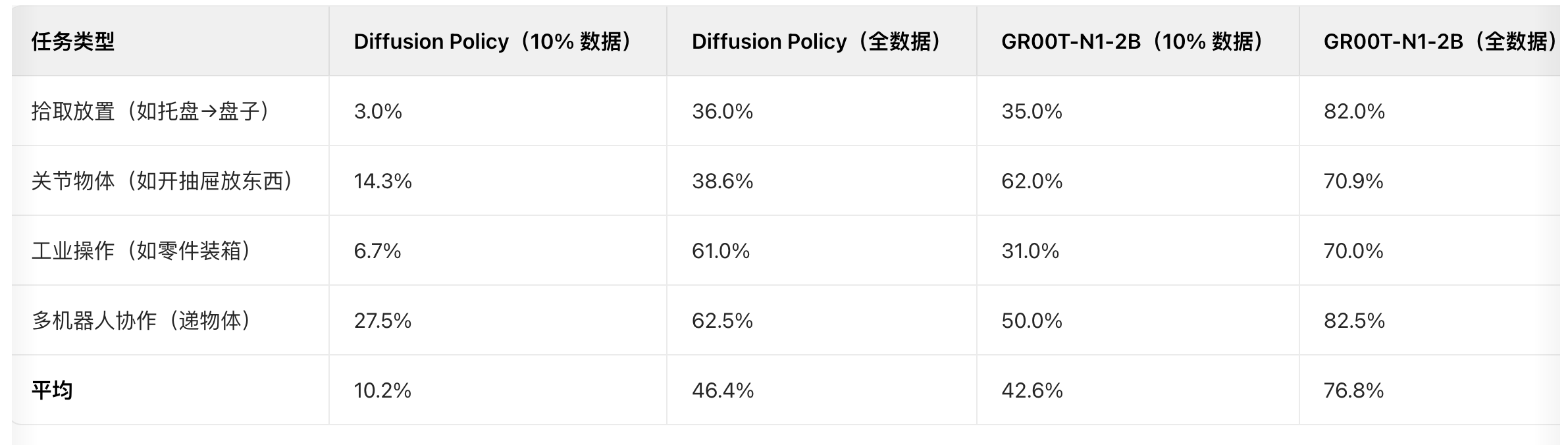
关键结论:
- 数据效率:GR00T 用 10% 真实数据(如某任务仅采集 15 分钟),成功率(42.6%)接近基线用 100% 数据(46.4%);
- 动作质量:GR00T 生成的动作更流畅(无卡顿),抓取准确率比基线高 30%+(比如 “拿柠檬” 任务,基线常抓空,GR00T 几乎不失误);
- 预训练泛化:预训练模型无需微调,就能完成 “双手交接物体”(成功率 76.6%)和 “新物体放进新容器”(73.3%),说明基础常识扎实。
总结
核心贡献:
- 公开了 GR00T-N1-2B 模型权重、训练数据、仿真环境(GitHub+HuggingFace),降低通用机器人研究门槛;
- 技术突破:双系统 VLA 架构解决 “推理慢 + 动作笨” 的矛盾,数据金字塔解决 “数据稀缺”,为后续通用机器人模型提供范式;
- 落地验证:在真实 GR-1 人形机器人上实现 “语言指令控制双手操作”,证明基础模型在人形机器人上的可行性。
局限性:
- 任务范围:目前仅支持 “短时长桌面任务”(如 30 秒内拾取),无法处理 “长时任务”(如做饭:切菜→炒菜→装盘);
- 合成数据质量:神经轨迹偶尔违反物理规律(如物体穿墙),仿真数据与真实物理环境仍有差距;
- 硬件依赖:推理需 NVIDIA L40/H100 GPU,难以部署到低算力机器人(未来需轻量化)。
一句话总结:
GR00T N1 是 NVIDIA 为通用人形机器人打造的 “开源智能大脑”—— 通过 “双系统 VLA 架构” 实现 “理解指令 + 流畅动作”,用 “数据金字塔” 解决数据稀缺,在仿真和真实 GR-1 机器人上证明:一套模型能适配不同机器人,且用少量数据就能快速学会新任务,为通用机器人的普及迈出关键一步。

电影级数字人,免显卡端渲染SDK,十行代码即可调用,工业级demo免费开源下载!
更多推荐
 25
25 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)