
qwen3-vl中的架构层面三个创新点:MRoPE-interleave/deepstack/文本时间戳对齐
Qwen3-VL是阿里推出的多模态大模型,通过三大创新优化视觉-文本融合:1)MRoPE-Interleave采用交替编码解决频率分布问题;2)DeepStack机制分阶段多层插入视觉token,避免信息丢失;3)T-RoPE实现帧级时间对齐。这些技术使视觉信息能持续参与深度推理,显著提升多模态理解能力,同时保持参数高效性。相关原理详见《DeepStack》论文及官方技术文档。
·
来自:https://github.com/QwenLM/Qwen3-VL?tab=readme-ov-file
目录
1. 技术背景
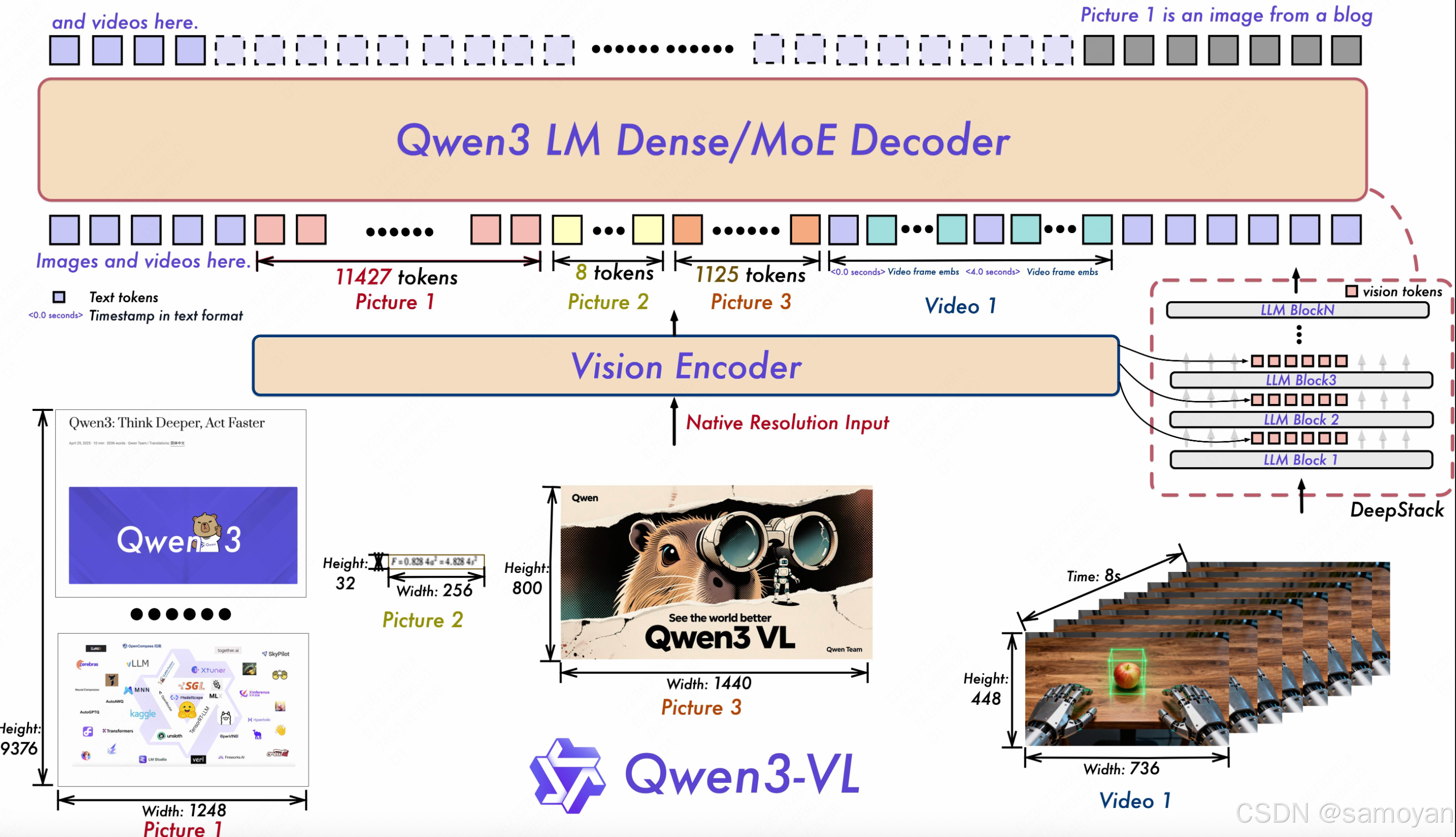
Qwen3-VL 是阿里推出的大型多模态模型(上一版本是Qwen2.5-VL),旨在支持文本与视觉信息的联合理解。在多模态模型中,需要在 Transformer 架构中有效融合视觉特征(如 ViT 输出)和文本特征(如 LLM 输出)。传统方法将视觉 token 与文本 token 拼接后送入 LLM 进行处理,但这种方式可能导致视觉信息在深层网络中逐步丢失。
2. 核心优化架构
Qwen3-VL 通过以下核心优化技术来增强多模态信息的融合:
2.1 MRoPE - Interleave
- 优化目标:解决频率分布不均的问题。
- 原始编码方式:针对时间 t、高度 h、宽度 w 的编码顺序为 [ttt…hhh…www]。
- 优化方案:将编码顺序修改为交替形式 [thw…thw…thw]。
2.2 DeepStack
-
核心思想:分阶段、多层插入视觉特征,而不是一次性将视觉 token 全部拼接到输入层。这样可以让视觉信息在整个模型的推理过程中持续参与,提升多模态融合效果。
-
具体做法:
- 视觉 token 处理:通过视觉编码器(如 ViT)得到一系列视觉 token,包括原始视觉 token 和额外的高分辨率视觉 token。
- 多层插入:在 LLM 的 Transformer 的部分层(如每隔 N 层,从第 lstart 层开始)将视觉 token 重新插入(或融合)到模型的 hidden state 中。
- 堆叠方式:每次插入时,使用不同的视觉 token(如 Xstack),确保视觉信息在模型的不同深度得到补充。
- 伪代码示例:
def forward(H0, X_stack, l_start, n, vis_pos):
H = H0
for idx, TransformerLayer in enumerate(self.layers):
# DeepStack机制
if idx >= l_start and (idx - l_start) % n == 0:
H[vis_pos] += X_stack[(idx - l_start) // n]
# 正常Transformer层
H = TransformerLayer(H)
2.3 T-RoPE 升级为文本时间戳对齐机制
- 优化目标:实现帧级别的时间信息与视觉内容的细粒度对齐。
- 具体做法:采用“时间戳—视频帧”交错的输入形式。
3. 优势
- 视觉信息持续参与:视觉特征不会被“淹没”在深层网络中,而是不断被补充和融合。
- 提升多模态能力:模型能更好地理解复杂的视觉-文本任务,如图片问答、视觉推理等。
- 参数高效:无需大幅增加模型参数,只需在部分层插入视觉 token。
5. 相关论文与官方说明
- DeepStack相关原理可参考论文《DeepStack: Deeply Stacking Visual Tokens for Multimodal Large Language Models》。
- Qwen3-VL官方文档和技术博客也有相关介绍:QwenVL官方技术解读

电影级数字人,免显卡端渲染SDK,十行代码即可调用,工业级demo免费开源下载!
更多推荐


 5
5 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)