
8卡3090使用AWQ量化版基于vllm0.8.5成功启动“Qwen3-235B-A22B“教程(22.7t/s)
8卡3090部署Qwen3-235B-A22B教程
·
本教程使用vllm引擎,sglang0.4.6用awq量化版本会报错出"fusedmoe" 缺失hidesize,要改qwen3moe.py暂时没得多余的机器折腾了,先出个vllm的教程,勉强先用着把,性能肯定不如sglang,8卡3090用awq在sglang上应该能跑40t/s左右(仅猜测)。切记使用30系列以上的卡,这里必须要支持awq_marlin,不支持marlin算子的卡建议别折腾浪费功夫了,总显存要吃掉172G,张量并行建议使用能够整除64的卡数量凑够172G,推理不是很吃nvlink,我这里也是用的pcie。
#张量并行一定要加--enable-expert-parallel这个参数
这里很感谢魔塔社区的swift/Qwen3-235B-A22B-AWQ量化版本
建议使用 docker 进行部署,不使用 docker照抄 command 参数即可。
不会装docker的建议直接用1panel,直接丢编排里
端口根据自己需求放行,把注释删了就行。
欢迎大家用这个启动参数,少走弯路,少用显存。
services:
qw223ba22b:
image: vllm/vllm-openai:v0.8.5.post1
container_name: qw223ba22b
volumes:
#- ${HOME}/.cache/huggingface:/root/.cache/huggingface
# If you use modelscope, you need mount this directory
- /mnt/md0/docker_files/.cache/modelscope:/root/.cache/modelscope #这里根据自己需求修改映射路径
restart: always
# Or you can only publish port 30000
# ports:
# - 23002:30000
environment:
- TZ=Asia/Shanghai
- HF_ENDPOINT=https://hf-mirror.com
- VLLM_USE_MODELSCOPE=True
- CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7
entrypoint: vllm serve
command: /root/.cache/modelscope/hub/models/swift/Qwen3-235B-A22B-AWQ #这里使用的是本地预先下载好的模型,在线下载使用 --model swift/Qwen3-235B-A22B-AWQ
--api-key zqza-abc123 #这里设置你自己的api即可
--trust-remote-code
--tensor-parallel-size 8
--enable-reasoning
--max-model-len 32768
--enforce-eager #节约显存
--dtype half #节约显存
--quantization awq_marlin #节约显存
--enable-expert-parallel
--reasoning-parser deepseek_r1
--served-model-name qw223ba22b
--host 0.0.0.0
--port 30000
ipc: host
privileged: true
# healthcheck:
# test: ["CMD-SHELL", "curl -f http://localhost:30000/health || exit 1"]
deploy:
resources:
reservations:
devices:
- driver: nvidia
device_ids: ["0","1","2","3","4","5","6","7"]
capabilities: [gpu]
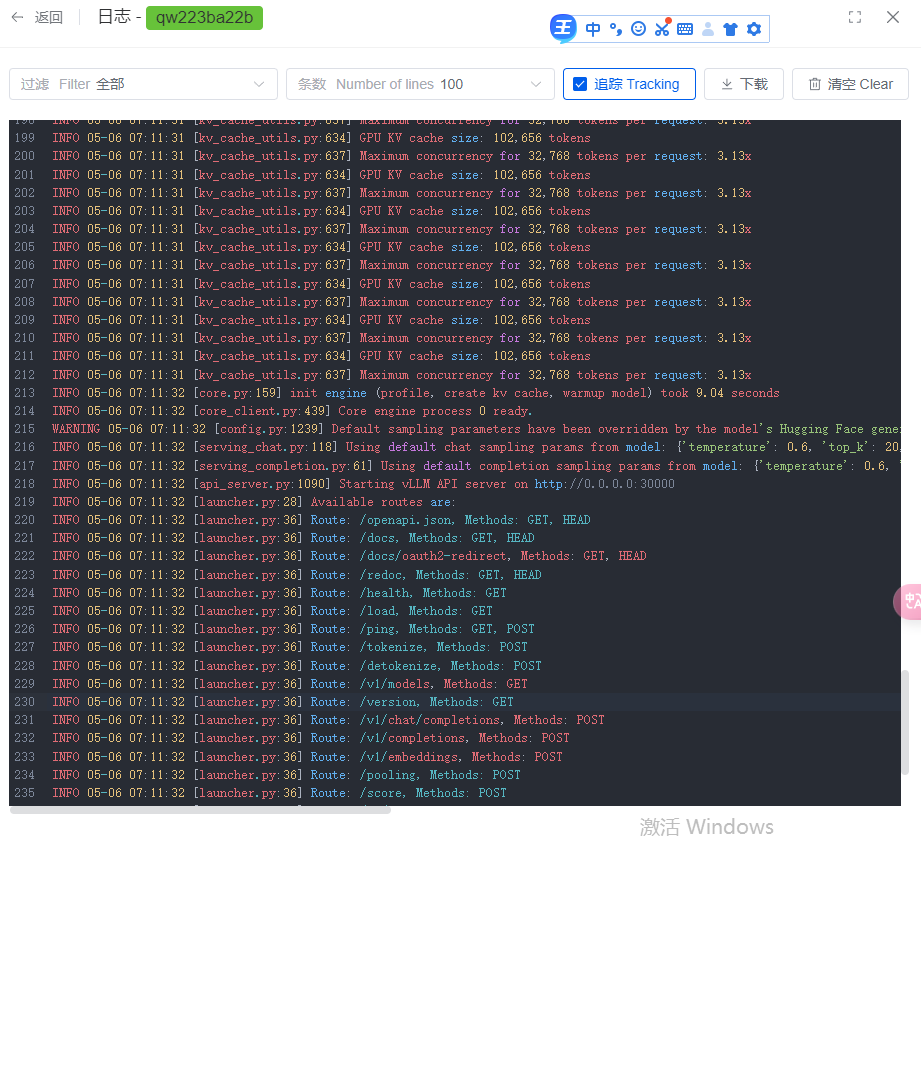
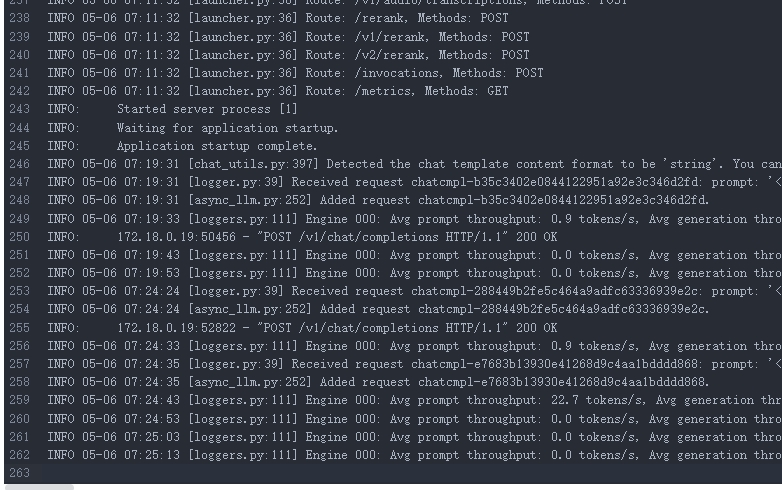
成功运行截图如下

电影级数字人,免显卡端渲染SDK,十行代码即可调用,工业级demo免费开源下载!
更多推荐


 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)