
具身ALOHA做什么|FRAPPE:不卷像素、只学逻辑!让具身智能真正理解世界
在具身智能与机器人学习领域,让模型理解环境动态、具备世界建模能力,是实现长时序、强泛化机器人操作的核心。但现有方法要么困在像素级重建的冗余细节里,要么在推理中陷入误差累积,难以真正落地。近日,等机构联合提出FRAPPE—— 一种通过多未来表征对齐 + 并行渐进扩展,把世界建模注入通用机器人策略的高效训练范式。在 RoboTwin 仿真基准与真实机器人任务中,FRAPPE 全面超越 SOTA,还能用

在具身智能与机器人学习领域,让模型理解环境动态、具备世界建模能力,是实现长时序、强泛化机器人操作的核心。但现有方法要么困在像素级重建的冗余细节里,要么在推理中陷入误差累积,难以真正落地。
近日,浙江大学、西湖大学、香港科技大学(广州)等机构联合提出FRAPPE—— 一种通过多未来表征对齐 + 并行渐进扩展,把世界建模注入通用机器人策略的高效训练范式。在 RoboTwin 仿真基准与真实机器人任务中,FRAPPE 全面超越 SOTA,还能用无动作标注的人类视频低成本提升泛化,为大模型机器人落地打开新路径。
项目主页:https://h-zhao1997.github.io/frappe/
论文链接:https://arxiv.org/pdf/2602.17259
使用产品:松灵COBOT MAGIC(ALOHA)
01.模型痛点
当前基于扩散模型的 VLA(视觉 - 语言 - 动作)策略,虽在抓取、摆放等任务表现亮眼,但加入世界建模后仍有硬伤:
-
像素重建陷阱:强制预测未来图像,让模型浪费算力在冗余像素,忽略任务关键语义,分布外场景泛化极差;
-
误差累积死循环:推理依赖显式预测观测,一步错步步错,长时序任务直接崩盘;
-
单一表征偏见:仅对齐单个视觉基座模型,自带任务偏置,无法适配多样机器人任务。
FRAPPE 的核心思路很清晰:不生成像素,只对齐未来隐表征;不串行训练,用并行扩展放大算力与知识。
02.核心设计
FRAPPE 基于开源的RDT 机器人扩散 Transformer基座,用两阶段微调实现世界建模,全程参数高效、训练稳定。
1. 中期训练:单流对齐,打好世界模型基础
先不搞并行,用全参数微调,让模型学习预测未来观测的隐表征:
-
加入可学习 “未来前缀”,替代像素生成;
-
用蒸馏自多个视觉基座的小编码器做教师,对齐未来表征;
-
只优化动作损失 + 表征对齐损失,让模型先学会 “预判环境变化”。
2. 后期训练:并行扩展,混合专家对齐多视觉模型
冻结主干,给模型装多组 LoRA + 专属前缀,形成MiPA(混合前缀 - LoRA 专家):
-
3 个专家分别对齐 CLIP、DINOv2、ViT 三大视觉基座,吸收多元世界知识;
-
轻量级路由网络加权融合专家输出,加负载均衡损失避免单专家垄断;
-
仅训练前缀与 LoRA,参数量极小、显存占用低。
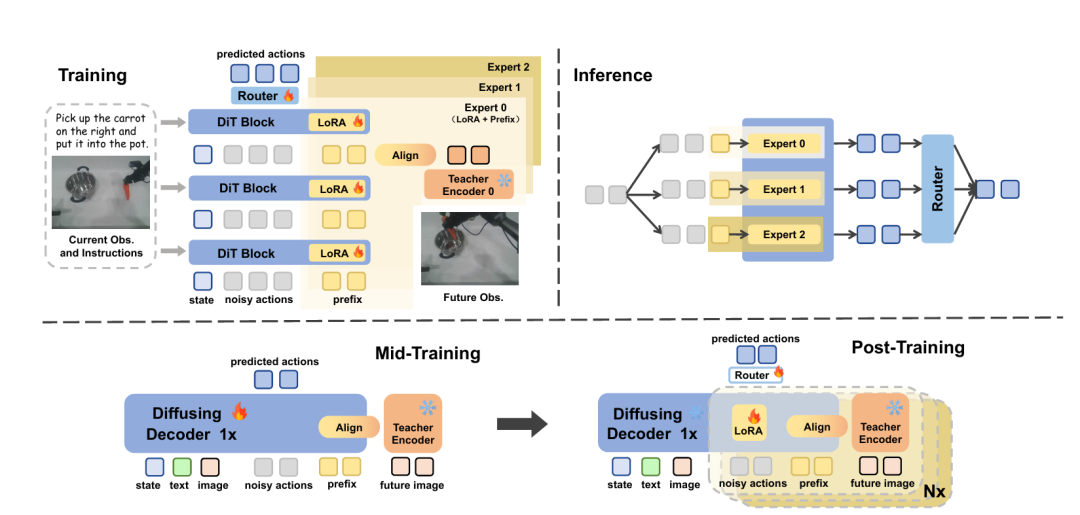
3. 推理阶段:保留并行计算,无额外监督
推理时完全去掉教师模型,复用训练的并行计算图,不增加推理复杂度,还能通过减少扩散步长进一步提速。
03.实验结果
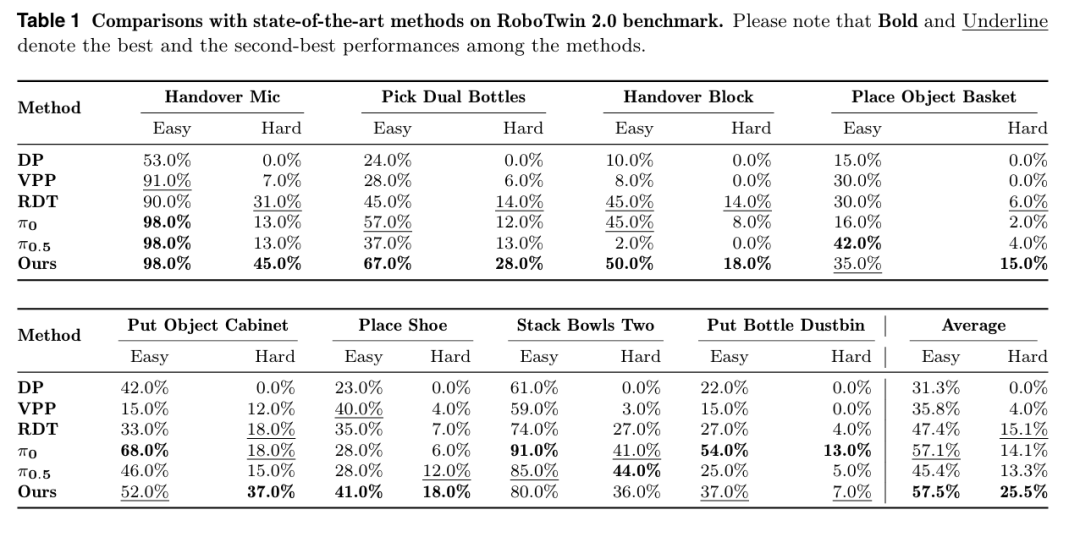
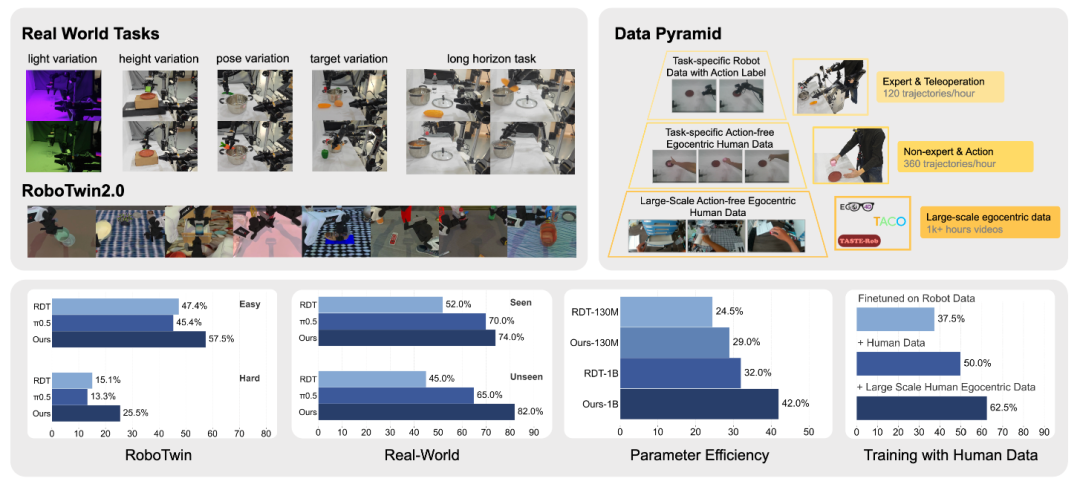
1. 仿真基准:RoboTwin 2.0 全面霸榜
在 8 类双手机器人任务、Easy/Hard 两种难度下:
-
Easy 设置:FRAPPE 平均成功率57.5%,超越 π0、π0.5 等 SOTA;
-
Hard 设置(光照、高度、背景随机):FRAPPE25.5%,比次优模型高出10 + 个百分点,泛化力断层领先。
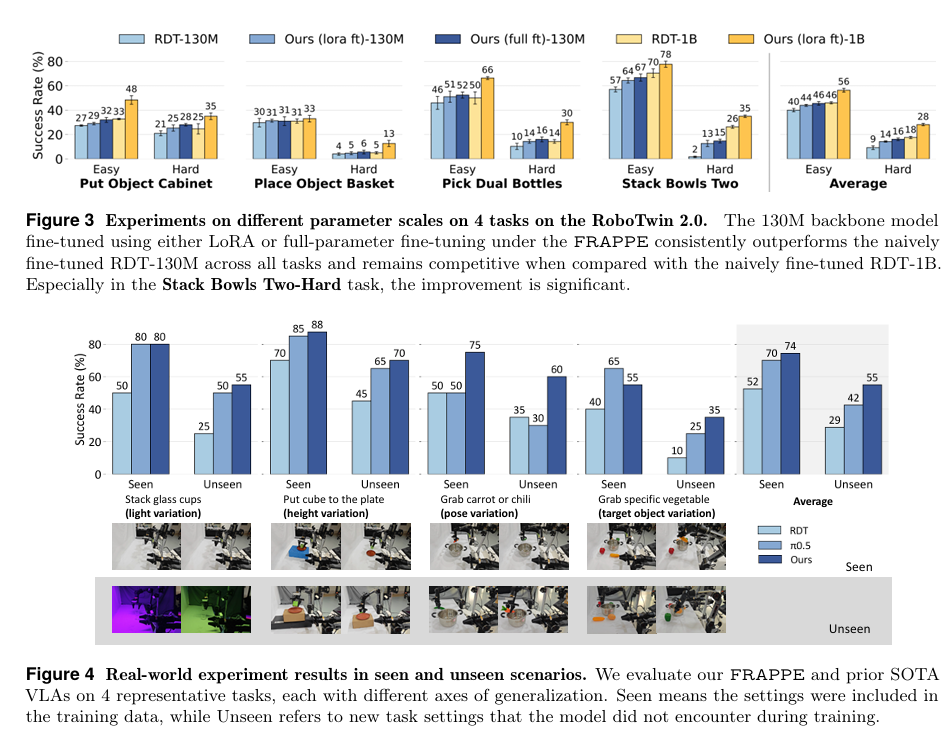
2. 真实机器人:未见场景也能稳操作
在 AgileX ALOHA上测试 4 类泛化任务(光照 / 高度 / 姿态 / 目标变化):
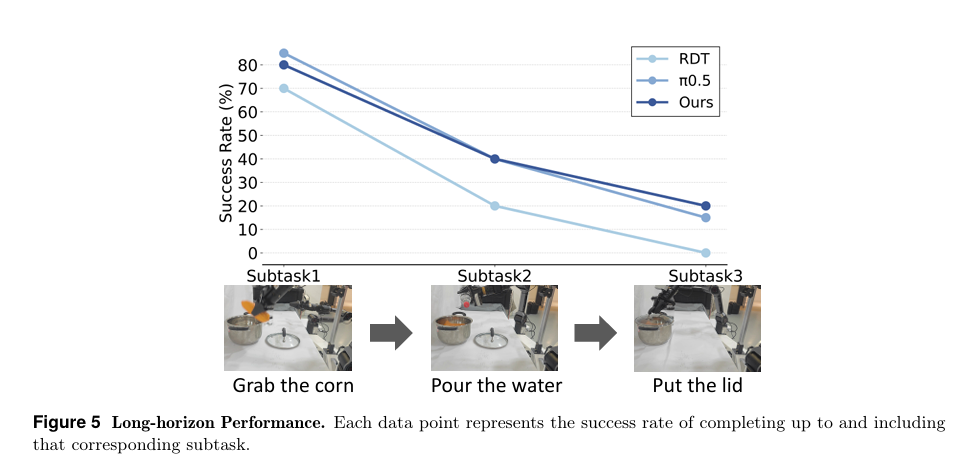
-
未见场景性能大幅领先基线,长时序三阶段任务(抓取玉米→倒水→盖盖子)成功率达20%,原版 RDT 完全失败;
-
推理效率:5 步扩散仅增 20ms 延迟,3 步扩散速度更快、效果仍超基线。
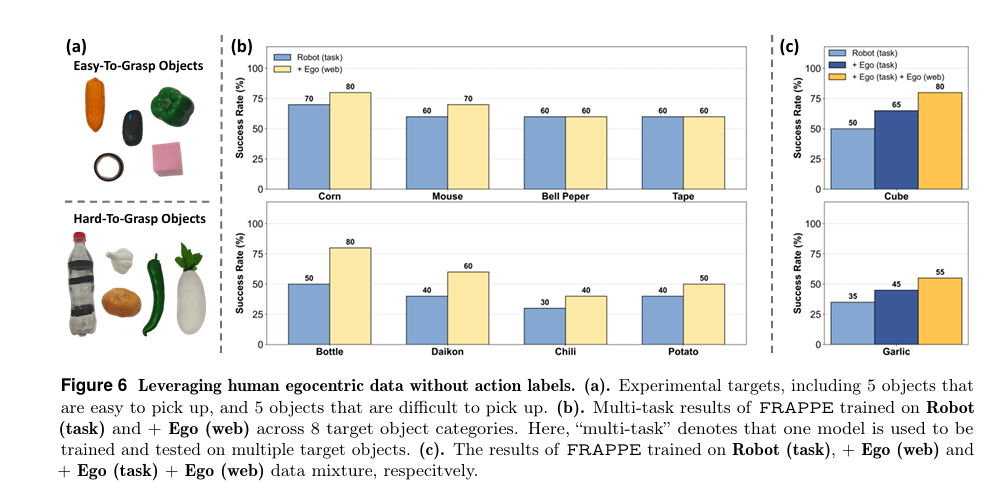
3. 数据效率:无动作标注人类视频,低成本涨点
FRAPPE 革命性支持无动作标注的人类第一视角视频训练:
-
数据金字塔:底层海量互联网人类视频→中层任务级人类操作视频→顶层少量机器人遥操作数据;
-
仅用 5 条机器人轨迹 + 人类视频,比纯机器人数据提升 10-15%,数据收集效率提升 3 倍。
04.关键创新
-
隐式世界建模:放弃像素生成,用表征对齐避开冗余与误差累积;
-
并行渐进扩展:两阶段训练稳定收敛,LoRA + 前缀参数高效;
-
多元知识融合:对齐多视觉基座,消除单一表征偏置;
-
低成本数据 scaling:用人类视频替代昂贵机器人标注,大幅降低落地门槛。
FRAPPE 没有重新设计模型架构,而是用更聪明的训练范式,给现有 VLA 大模型插上 “世界建模” 的翅膀。它证明了:机器人通用策略不必死磕像素预测,对齐未来隐表征 + 并行扩展,就能实现强泛化、高效率、低成本。
从仿真到真机,从少量标注到海量无标注人类视频,FRAPPE 为家庭服务、工业操作等真实场景机器人,提供了一条可规模化的落地路径。
主页:https://h-zhao1997.github.io/frappe
代码:https://github.com/Jbo-Wang/frappe
模型:HuggingFace 搜索 FRAPPE 即可获取

电影级数字人,免显卡端渲染SDK,十行代码即可调用,工业级demo免费开源下载!
更多推荐

 7
7 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)