
NVIDIA Cosmos 3:全模态世界基础模型开启物理AI新纪元,8项物理AI基准测试开放模型排名第一
Cosmos 3系列全模态世界模型通过创新的Mixture-of-Transformers双塔架构,首次实现了语言、图像、视频、音频和动作序列的统一处理。该模型采用共享骨干网络中的分离参数设计,通过联合注意力机制实现理解与生成的协同工作。统一动作表征体系覆盖了从机器人到自动驾驶的多样化场景,而多模态位置编码确保了跨模态时间一致性。NVIDIA提供了40亿到640亿参数的三种模型变体,在多项任务中达
统一语言、图像、视频、音频与动作,构建物理AI的通用基础模型
2026年6月 | 技术报告深度解读
核心摘要
NVIDIA于2026年6月发布了Cosmos 3系列全模态世界模型(Omnimodal World Models),这是首个在单一架构内统一处理语言、图像、视频、音频和动作序列的物理AI基础模型。通过创新的Mixture-of-Transformers(MoT)双塔架构,Cosmos 3无缝融合了视觉语言模型、视频生成器、世界模拟器与世界动作模型。在多项权威评测中,Cosmos 3在文本到图像、图像到视频、机器人策略等任务上均取得开源模型最优成绩,部分指标超越闭源商业模型。NVIDIA已将该模型权重、代码、合成数据集及评测基准以OpenMDW-1.1许可证开源,旨在加速物理AI领域的研究与应用落地。
一、物理AI的范式变革:从碎片化到统一化
物理AI(Physical AI)代理需要具备感知、推理与行动三大核心能力,以在真实世界中完成复杂任务。然而,传统的技术路线将这三项能力割裂开来:视觉语言模型(VLM)负责感知与推理,视频生成模型负责世界模拟,视觉语言动作模型(VLA)负责执行控制。这种碎片化的架构不仅导致计算资源的浪费,更使得各模块之间的信息传递存在语义损失,难以形成对世界一致且连贯的理解。
以家庭服务机器人为例,在现有范式下,机器人需要串联多个独立模型:VLM定位餐具并生成执行计划,VLA或世界动作模型(WAM)生成动作序列,前向动力学模型模拟未来状态。这种拼接式的架构在计算效率与任务连贯性方面均存在明显瓶颈。Cosmos 3的设计哲学正是为了解决这一根本性问题——通过统一架构同时实现理解与生成,让模型在推理时能够预判世界演变,在生成时能够依托结构化的世界表征。
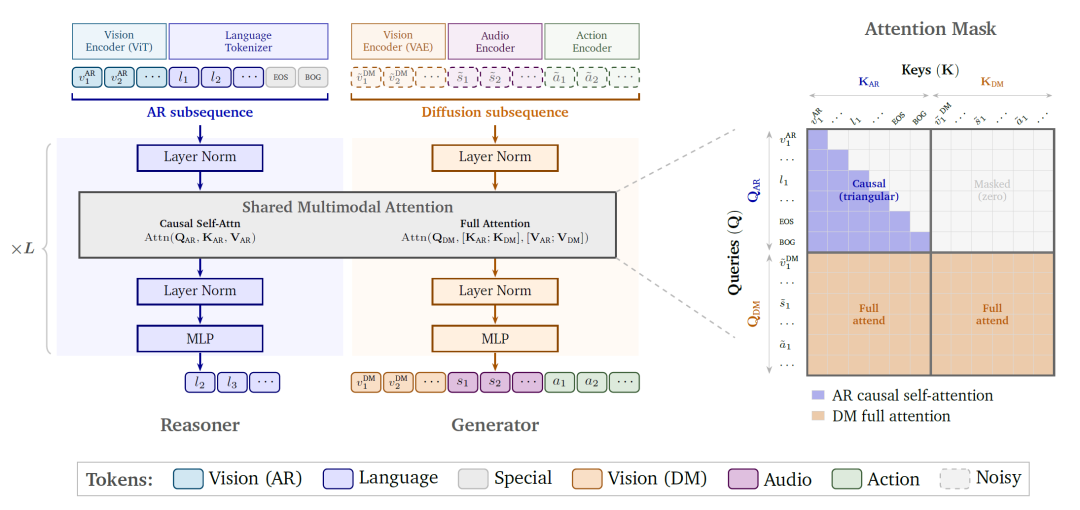
图1:Cosmos 3作为物理AI的通用基础模型,统一了视觉语言模型、图像生成模型、音视频生成模型、策略/世界动作模型、前向动力学模型与逆动力学模型(来源:NVIDIA Cosmos 3技术报告)
如图1所示,Cosmos 3通过灵活的输入输出配置,可在多种操作模式间无缝切换:作为视觉语言模型进行多模态理解与推理;作为文本到图像/视频生成器进行视觉内容合成;作为世界动作模型联合预测动作与环境演变;作为前向/逆动力学模型建立动作与视觉状态之间的因果联系。这种统一性消除了对碎片化、任务专用流水线的依赖,使模型能够通过共享表征与联合多任务学习实现可扩展的训练。
Cosmos 3的发布标志着世界模型研究进入全模态统一的新阶段。通过将语言理解、视觉感知、视频模拟、音频合成与动作控制整合在单一架构中,Cosmos 3为物理AI代理提供了一个可共享、可扩展、可 specialization 的基础模型。其在图像生成、视频生成、机器人策略与自动驾驶仿真等任务上的领先性能,验证了统一架构相较于碎片化方案的技术优势。
二、Mixture-of-Transformers:理解与生成的一体化架构
Cosmos 3的核心架构创新在于Mixture-of-Transformers(MoT)设计。该架构在单一Transformer骨干网络中设置了两套参数:一套用于处理自回归(AR)子序列的推理任务,另一套用于处理扩散(DM)子序列的生成任务。尽管两个塔(Tower)使用独立的层归一化、注意力投影矩阵与前馈网络参数,但它们通过共享的多模态注意力机制进行信息交互。
2.1 双塔联合注意力机制
在MoT的每一层中,AR子序列中的语言与视觉理解令牌通过因果自注意力进行编码,确保模型保留预训练视觉语言模型的文本生成能力。与此同时,DM子序列中的扩散令牌使用全双向注意力,能够同时关注AR子序列中的文本提示以及DM子序列中的条件与噪声令牌。这种设计使得扩散生成过程能够充分 Conditioning 于推理塔输出的语义理解结果,同时保持推理塔的因果完整性不受扩散过程的干扰。
具体而言,推理塔中的查询(Query)仅对推理塔内部的键(Key)和值(Value)执行因果自注意力,形成标准的下三角掩码。而生成塔的查询则对推理塔与生成塔拼接后的键和值执行全双向注意力,这意味着每个生成令牌都可以访问完整的文本提示和条件视觉信息。这种分离但交互的设计,使Cosmos 3在保持语言推理能力的同时,获得了强大的多模态生成能力。
2.2 统一动作表征
Cosmos 3将动作视为与语言、视觉、音频并列的核心模态,引入了专用的动作令牌类别。针对自动驾驶、相机运动、机器人操作及第一人称人体运动等不同具身形态,模型设计了统一的动作接口:将各领域的原生控制空间(如关节轨迹、转向指令、身体姿态)映射为共享的几何结构。具体而言,自车姿态与末端执行器姿态采用9维相对位姿伪动作(3维平移加6维旋转),抓取状态则直接编码当前操作状态(如手指位置或夹爪开合值)。
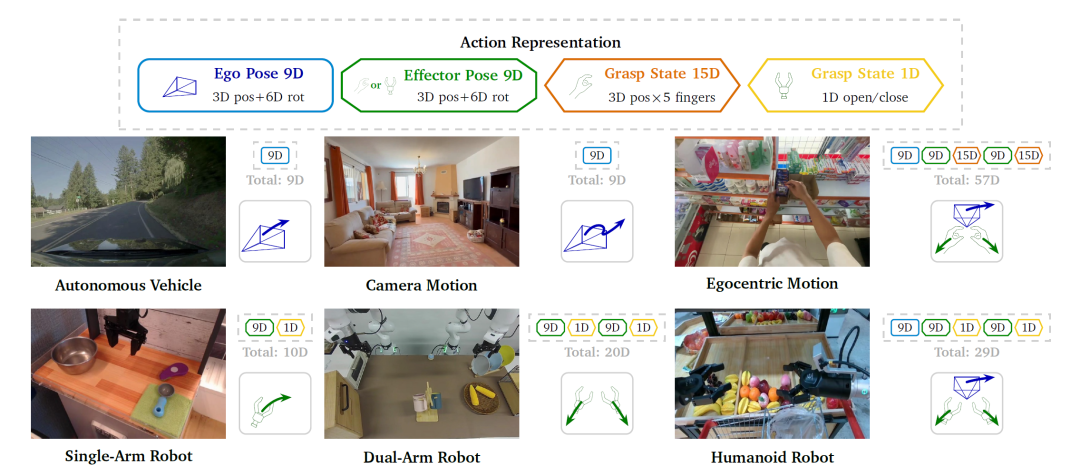
图2:Cosmos 3的统一动作表征体系,将异构具身控制映射为共享几何组件构成的紧凑动作向量(来源:NVIDIA Cosmos 3技术报告)
如图2所示,该表征体系覆盖了从自动驾驶车辆到双机械臂机器人、从人形机器人到第一人称手部操作的广泛场景。通过领域感知的输入输出投影层,不同具身形态的动作向量可在共享的潜动作空间中保持一致性,而MoT骨干网络则实现跨领域的参数共享。这种设计使得Cosmos 3能够在不修改架构的情况下,处理从单臂机器人到双机械臂、从人形机器人到自动驾驶车辆的多样化动作空间。
2.3 多模态位置编码与绝对时间调制
由于Cosmos 3需要同时处理视频、音频与动作令牌,且这些模态可能以不同的帧率或采样率生成,传统的一维位置编码已无法满足需求。模型采用扩展的3D多模态旋转位置编码(MRoPE),为语言、视觉、音频和动作令牌分配独立的时空坐标。特别地,模型引入了绝对时间调制机制(Absolute Temporal Modulation),将不同帧率(如16FPS、24FPS、30FPS)的视频令牌对齐到统一的物理时间轴上,确保跨模态的时间一致性。
在实现层面,Cosmos 3定义了每秒时间步数(TPS)来表征物理时间分辨率。对于视频令牌,TPS由视频帧率除以时间压缩因子(本模型中为4)得到;对于音频令牌,TPS为采样率除以跳步大小(48000Hz除以1920采样,约为25);对于动作令牌,TPS即为动作数据的采样频率。当需要沿时间维度增加一个单位步长时,实际的时间增量通过基础TPS与当前模态TPS的比值进行调制。由于视频数据占训练数据的主体,且24FPS是最常见的帧率,模型将基础TPS设为6(即24除以4)。这一机制确保了即使不同模态的令牌以不同速率进入序列,它们仍能在统一的物理时间坐标系中对齐。
2.4 模型变体与规模设计
Cosmos 3提供了三种模型规模,覆盖从边缘设备到大型数据中心的广泛部署需求。Edge变体为40亿参数模型(基于20亿参数稠密Transformer),Nano变体为160亿参数(基于80亿参数稠密Transformer),Super变体为640亿参数(基于320亿参数稠密Transformer)。所有变体均从预训练的视觉语言模型初始化,并采用MoT架构。
|
|
|
|
|
|
|
|
|---|---|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Edge模型使用Megatron代码库从头训练,架构基本遵循Qwen3-1.7B设计,但移除了QK归一化并采用ReLU平方作为FFN激活函数。Nano和Super模型则分别基于Qwen3-VL 8B和32B架构进行适配。这种分层设计使Cosmos 3既能满足资源受限场景的边缘部署需求,又能在数据中心环境中发挥最大性能。
三、数据引擎:从十亿级样本到物理AI专用语料
训练全模态世界模型需要前所未有的数据规模与质量。Cosmos 3的数据基础设施SILA(Scalable Infrastructure for Large-scale data processing and Annotation)支持从数十亿候选样本中迭代式地筛选、标注与管理训练数据。整个数据管线涵盖语义去重、AI质量评判、结构化标注与可视化调试等环节。
3.1 推理器数据课程
Cosmos 3推理器(Reasoner)的训练数据包含约2420万样本,分为2200万预训练样本与220万监督微调样本。预训练阶段以图像-文本和纯文本数据为主,涵盖OCR、视觉问答、空间定位、推理与描述等能力流。其中OCR是最大的组成部分,贡献944万样本(42.9%),其次是2D空间定位362万样本(16.5%)、视觉问答248万样本(11.3%)和图像推理166万样本(7.5%)。这种组成强调强大的图像-文本对齐、阅读与空间定位能力,同时保留轻量的视频组件,为后续监督微调中的时序与视频推理做准备。
为确保数据质量,NVIDIA采用Gemma-4作为AI评判模型,从忠实性(Faithfulness)、完整性(Completeness)与正确性(Correctness)三个维度对样本进行评分。忠实性确保所有回应声明都基于提供的图像、视频或文本上下文;完整性确保回应充分回答指令而无重要遗漏;正确性确保回应在事实、逻辑和任务层面均正确。在预训练阶段,模型采用阈值为2的保守过滤策略,在过滤明显低质量标注的同时最小化能力分布的偏移。在监督微调阶段,则采用阈值为5的严格过滤,仅保留最高置信度的监督样本。经此过滤,预训练数据保留了78%的样本,监督微调数据保留了46%。
3.2 生成器数据课程
生成器(Generator)的训练遵循渐进式多阶段课程。预训练阶段使用7.67亿张图像与3.48亿个视频片段,覆盖256p至720p多种分辨率。数据经过严格的预处理流程:首先通过场景变换检测将长视频分割为时序一致的片段,然后使用ffmpeg去除黑边并重新编码为规范格式。在嵌入与去重阶段,图像使用Qwen3-VL-Embedding-8B进行嵌入,视频使用nvidia/Cosmos-Embed1-448p进行嵌入,通过K-Means聚类与余弦相似度阈值去除近似重复内容。
中期训练阶段引入高质量物理AI数据,包括机器人操作、自动驾驶、人体活动及物理仿真场景。此外,NVIDIA还构建了五大合成数据集(SDG-PhyxSim、SDG-RobotSim、SDG-DriveSim、SDG-SynHuman、SDG-Warehouse),专门用于弥补真实世界数据在长尾物理场景中的不足。SDG-PhyxSim聚焦于刚体碰撞、铰接物体动力学、可变形材料、流体动力学与光学效应;SDG-RobotSim涵盖6至8种机器人具身形态的操作与移动序列;SDG-DriveSim覆盖常规与极端交通场景;SDG-SynHuman用于改善人体动力学、相机运动先验与多角色交互的建模;SDG-Warehouse则针对仓储安全中的人车交互场景。

图3:Cosmos 3的三阶段训练范式:预训练+中期训练建立通用能力,后训练实现特定领域的专家化(来源:NVIDIA Cosmos 3技术报告)
如图3所示,Cosmos 3在预训练与中期训练后,通过后训练(Post-training)进一步 specialization 为特定领域的专家模型。技术报告中展示了三种后训练变体:Cosmos3-Super-Text2Image(文本到图像)、Cosmos3-Super-Image2Video(图像到视频)以及Cosmos3-Nano-Policy-DROID(机器人策略)。这些变体与基础模型共享完全相同的架构,仅在数据与训练目标上有所差异,体现了Cosmos 3架构的灵活性与可扩展性。
3.3 结构化标注体系
Cosmos 3采用结构化的JSON标注格式替代传统的自由文本描述,以提升生成质量。图像标注模式涵盖主体、背景、光照、美学、摄影、风格、文本标识等静态属性,并通过四象限扫描机制(将图像分为左上、右上、左下、右下及中心区域分别描述)提升对复杂布局的空间覆盖。视频标注模式则在此基础上扩展了动作、状态变化、相机运动、时间片段、转场与音频描述等动态字段。
为定量评估标注质量,NVIDIA设计了专门的图像与视频标注质量基准。精度通过将生成的标注分解为原子声明并由VLM验证其是否得到源媒体支持来评估;召回率则通过将视觉内容分解为原子声明列表,并由LLM交叉引用生成标注与真实声明列表来确定。在这一基准上,结构化标注方法显著提升了召回率,同时保持了高精度。
四、训练配方:从通用先验到物理AI专家
4.1 推理器训练
推理器训练分为大规模多模态预训练与物理AI任务监督微调两个阶段。预训练阶段,模型从语言模型与ViT编码器开始,通过多模态投影器连接。Nano模型使用Qwen3-VL-8B初始化,Super模型使用Qwen3-VL-32B初始化。与先前分阶段对齐的做法不同,Cosmos 3从预训练开始就联合训练所有组件,发现这种端到端训练方式无需单独的冻结投影器阶段即可达到良好效果。
预训练使用下一令牌预测目标,在完整预训练混合数据上训练两个轮次。由于物理AI应用需要高效推理与低延迟,序列长度限制在16k令牌以内,其中图像令牌不超过2048,视频令牌不超过8192。优化采用AdamW,语言模型与投影器的峰值学习率为5e-5,ViT为5e-6,学习率遵循余弦衰减至峰值的0.1倍,前10%步数为线性预热。
监督微调阶段在220万高质量样本上进行,采用重要性感知采样策略,根据数据集的重要性、质量与规模分配固定采样预算。为防止下游专化导致通用能力退化,模型以1:4的比例混入预训练数据。训练使用AdamW,语言模型与投影器峰值学习率为1e-5,ViT为1e-6,经过1000步线性预热后余弦衰减。
4.2 生成器训练
生成器采用渐进式多模态课程,从大规模图像、视频与音频预训练开始,逐步引入动作与迁移数据。训练目标为整流流匹配(Rectified Flow Matching),对于目标潜变量,通过线性插值构造噪声潜变量,训练去噪器预测恒定速度。不同模态(图像、视频、音频、动作)独立采样噪声水平,图像、音频与动作使用对数正态噪声分布,视频使用模态采样。
预训练阶段采用多分辨率训练策略,同时在256p、480p、720p三个分辨率层级以及五种宽高比上训练。每个分辨率层级设定不同的最大帧预算:256p与480p最多400帧,720p最多300帧(受序列长度限制)。训练批次按图像、视频-256p、视频-480p、视频-720p的1:1:2:1比例组成。为防止因可变序列长度导致的频繁重编译开销,模型使用令牌打包策略,在固定的74,000令牌上下文窗口内打包不同分辨率的序列,最大化GPU利用率。
中期训练阶段引入动作与视频迁移数据。动作数据包含前向动力学、逆动力学与策略三种模式,视频迁移数据包括边缘、模糊、深度、分割与世界场景地图控制。各模态的混合比例经过精心调整:图像10%、视频32%、视频+音频8%、动作25%、通用迁移20%、驾驶迁移5%。动作损失乘以10倍以补偿归一化动作向量较小的每元素均方误差。
4.3 后训练专化
文本到图像后训练采用两阶段监督微调。第一阶段在高质量数据集上微调20k步,混合45%真实图像、40%合成图像与15%文本渲染图像,基础学习率1e-4。第二阶段在47万超高质量图像-描述对上执行2k步精炼,进一步提升视觉美学、提示遵循、文本渲染质量与人类偏好对齐。
图像到视频后训练针对480p分辨率、189帧(约8秒)的目标配置进行专化。训练混合包含过滤后的预训练数据、1000条人工精选视频与约20k条合成视频片段。虽然所有视频序列均使用I2V形式训练,但混合中仍包含20%的T2I图像令牌以保持语义对齐能力。训练运行10k迭代,学习率1e-5,处理约500亿令牌。
机器人策略后训练以DROID数据集为试点。DROID平台使用Franka Panda 7自由度机械臂与Robotiq 2F-85平行夹爪,在多样化的真实环境中执行桌面操作任务。数据集包含76k条轨迹、350小时交互数据、86项任务与564个场景。模型输入包括当前本体感知状态与三视角视觉观测(腕部视角360x640,两个外部视角各180x320,拼接为540x640画布),输出为32个未来绝对关节位置动作,工作频率15Hz。推理时使用4步扩散采样与移位噪声调度,配合分类器自由引导,可在2块NVIDIA RTX Pro 6000 GPU上部署策略服务器。
五、工程基础设施:支撑大规模训练与高效推理
5.1 数据基础设施SILA
为支撑数十亿级样本的多模态数据管理,NVIDIA开发了SILA平台。该平台采用统一的Lance列式存储格式,将样本内容、元数据、嵌入向量与处理状态整合在同一数据层中,取代了早期架构中每个流水线写入独立Postgres表的设计。通过片段级协调与故障恢复机制,SILA将大规模数据整理任务的启动延迟从30-60分钟缩短至约5分钟,整体吞吐量较上一代架构提升10倍。
SILA的核心设计包括:统一数据层,将数据整理组织为列式Lance数据集,每行代表一个样本,每列代表一个整理信号;片段级协调,分布式工作者通过Lance元数据发现未完成片段并获取限时租约,心跳停止时租约过期自动回收;分阶段Ray执行,将数据加载、解码、模型推理、后处理、写入与提交分离到独立的工作池;节点本地模型服务端点,使用vLLM等系统在节点本地启动模型服务,避免集中式推理瓶颈;机会性集群利用,支持在DGX Cloud Lepton与Slurm等后端上利用碎片化GPU资源。
5.2 训练基础设施
Cosmos 3的训练采用混合分片数据并行(HSDP)与上下文并行(CP)的组合策略。HSDP在副本组内分片优化器状态、梯度与模型参数,同时在组间复制,以适度的组内通信换取训练多十亿参数模型所需的内存空间。CP则沿序列维度分片,处理单GPU内存无法容纳的超大上下文窗口。两种策略正交组合,根据模型规模、序列长度与集群拓扑动态配置。
针对MoT架构中推理塔与生成塔的不同注意力需求,团队联合设计了双向扁平注意力机制。该机制将计算分解为两次独立的变长SDPA调用:第一次处理推理塔的因果注意力,第二次处理生成塔对拼接后的推理与生成键值流的双向注意力。键值流按样本粒度扁平交错排列为[R0,G0,R1,G1,…]顺序,使每个生成查询仅在其自身样本的[Ri,Gi]块内双向关注。这一设计消除了固定长度实现中的填充开销,相较FlexAttention基线实现22%的端到端训练吞吐量提升。
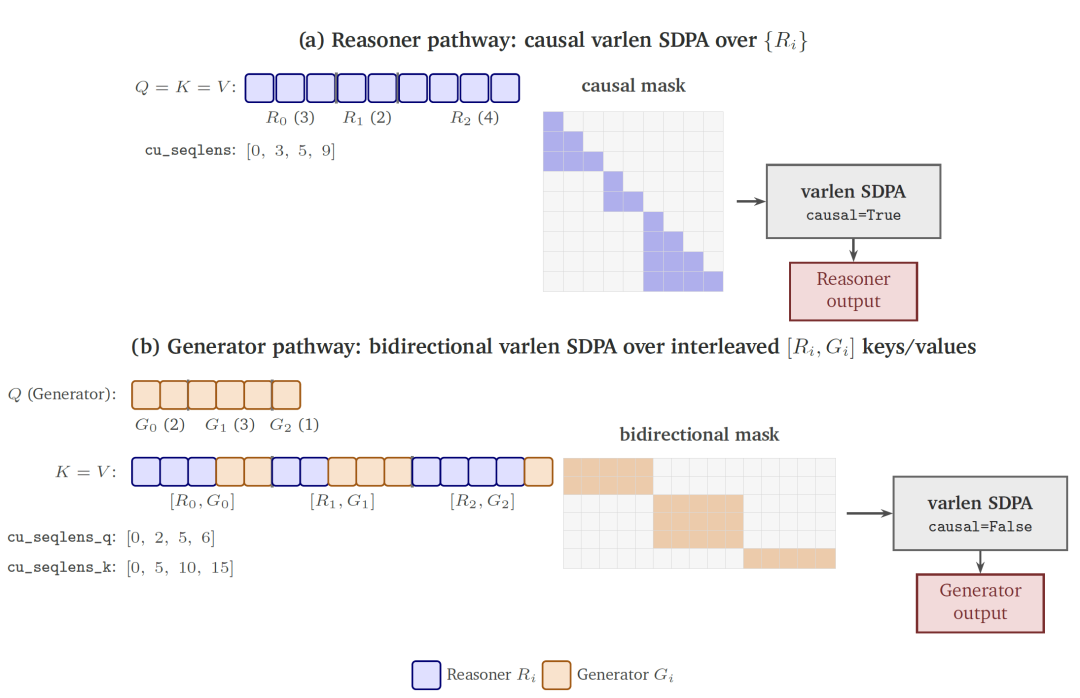
图4:双向扁平注意力机制。(a)推理塔使用标准因果变长SDPA;(b)生成塔对交错排列的推理-生成键值流执行双向变长SDPA(来源:NVIDIA Cosmos 3技术报告)
如图4所示,该注意力机制在Hopper级GPU(H100、H200)上使用FlashAttention-3,在Blackwell级GPU(GB200)上使用NATTEN,两者均通过通用调度接口访问,对训练栈的其余部分透明。上下文并行采用Ulysses方案,在注意力层外沿令牌维度分片,每层通过两次all-to-all集合操作在分片轴间转换。第一次将Q/K/V激活从序列维度重分布到注意力头维度,使每个rank持有完整序列的互斥子集;第二次在注意力输出上恢复原始序列分片布局。该方案与序列打包和双向注意力机制 cleanly 集成,最大支持的CP度数为查询头数量(Nano为32,Super为64)。
5.3 选择性激活检查点与编译优化
计算Transformer反向传播需要前向传播产生的中间激活,但同时在GPU内存中实例化所有激活在Cosmos 3的模型规模与上下文长度下是不可行的。标准缓解方案是激活检查点,仅存储每个Transformer块的输入并在反向时重新计算,但这会引入额外的前向传播,将每步FLOP增加约33%。
为减少重计算开销,Cosmos 3应用选择性激活检查点(SAC),在内存预算内额外保留部分中间张量。选择由简单的成本-收益启发式指导:按FLOP与内存比排序候选操作,优先实例化比值最高的操作,直至激活内存预算耗尽。对于Cosmos 3,注意力输出是此策略的主要受益者——注意力重计算成本随序列长度平方增长,而注意力输出张量本身相对较小(随序列长度与隐藏大小线性增长),使其成为FLOP-内存比最高的操作。实测表明,在Nano模型、每批次74,000令牌预算下,SAC带来13%的端到端训练吞吐量提升。
此外,Cosmos 3对Transformer块应用torch.compile(fullgraph=True, dynamic=True),消除CPU开销并启用算子融合,同时处理混合模态批次中的可变序列长度。该优化为Nano生成器带来41%的训练吞吐量提升。视频分词器方面,通过分块编码(256p用68帧、480p用24帧、720p用12帧)和AOTInductor预编译,将启动预热时间从约15分钟缩短至1分钟以内。
5.4 检查点与异步持久化
为消除保存导致的停滞,检查点通过专用Gloo进程组完全与训练重叠,隔离I/O流量与承载训练集合通信的NCCL通信器。异步保存机制在构造时启动长期子进程,通过多进程队列通信。保存计划在首次检查点保存时计算并复用于后续保存,避免重复的元数据通信,将检查点开销降低约60%。
在对象存储优化方面,通过设置dedup_to_lowest_rank=True,仅在对应子网格的最低编号rank上存储重复张量。加载时每个rank仅读取自身分片与rank-0分片,显著减少检查点加载时间,尤其对包含大量小重复张量的优化器状态字典效果显著。实测显示,异步检查点相较同步检查点,为Nano模型节省4%的端到端训练时间,为Super模型节省9%。
5.5 推理服务优化
Cosmos 3集成了多种生产级推理框架。推理器支持TensorRT-LLM与vLLM,生成器通过vLLM-Omni提供扩散式多模态生成服务。针对视频生成中的重复去噪步骤,模型支持推理塔输出缓存(Reasoner Tower Caching),在文本到图像/视频等任务中避免每步重复计算条件嵌入。分类器自由引导(CFG)并行技术将条件与无条件前向传播分配到不同GPU,几乎将每步延迟减半。
在B200 GPU上,720p文本到视频任务的延迟从单GPU的约400秒降低至8 GPU并行下的约60秒。批处理机制复用训练时的变长序列打包,将异构形状的样本拼接为单个打包张量,在吞吐量导向的部署中提升GPU利用率。实测显示,在256p T2V任务上,批处理为Nano模型带来8%至40%的吞吐量增益,为Super模型带来9%至55%的增益。
六、生成能力评测:图像、视频与音频的全方位突破
6.1 文本到图像:开源模型的最优成绩
Cosmos3-Super-Text2Image在UniGenBench评测中取得了91.36分的整体成绩,在开源模型中排名第一。该评测涵盖600个原始提示与570个物理AI专用提示,从语义对齐、场景文本渲染、物理合理性等维度进行全面评估。在Artificial Analysis的文本到图像公开排行榜上,Cosmos3-Super-Text2Image在所有开源权重模型中位列第一,整体排名第四。

图5:Cosmos3-Super-Text2Image生成的图像示例,涵盖农业无人机、机器人操作、自动驾驶场景、工业制造等物理AI相关领域(来源:NVIDIA Cosmos 3技术报告)
如图5所示,模型生成的图像在物理合理性与照片级真实感方面表现突出,能够呈现连贯的物体几何结构、一致的环境交互关系以及清晰的场景文本。这对于机器人、自动驾驶等需要严格遵循物理定律的应用场景尤为重要。在CVTG(复杂视觉文本生成)评测中,模型在英语长提示渲染(CVTG-500L)上取得GNED 80.88、PNED 89.08的成绩,在物理AI专用提示集上表现尤为出色。
6.2 视频生成:物理一致性的新标杆
在视频生成评测中,Cosmos 3在PAIBench-G、RBench、Physics-IQ等多项权威基准上取得领先成绩。PAIBench-G覆盖人类活动、自动驾驶、常识推理、机器人操作、物理现象与工业场景六大物理AI领域,Cosmos3-Super在文本到视频与图像到视频两个赛道均取得开源模型最高分。Physics-IQ则专门评估模型对物理定律的遵循程度,涵盖固体力学、流体力学、光学、热力学与电磁学五大类别。Cosmos3-Super在图像到视频模式下取得43.8分的直接成绩,结合WMReward重排序后进一步提升至48.9分,超越包括Sora 2在内的现有基准。
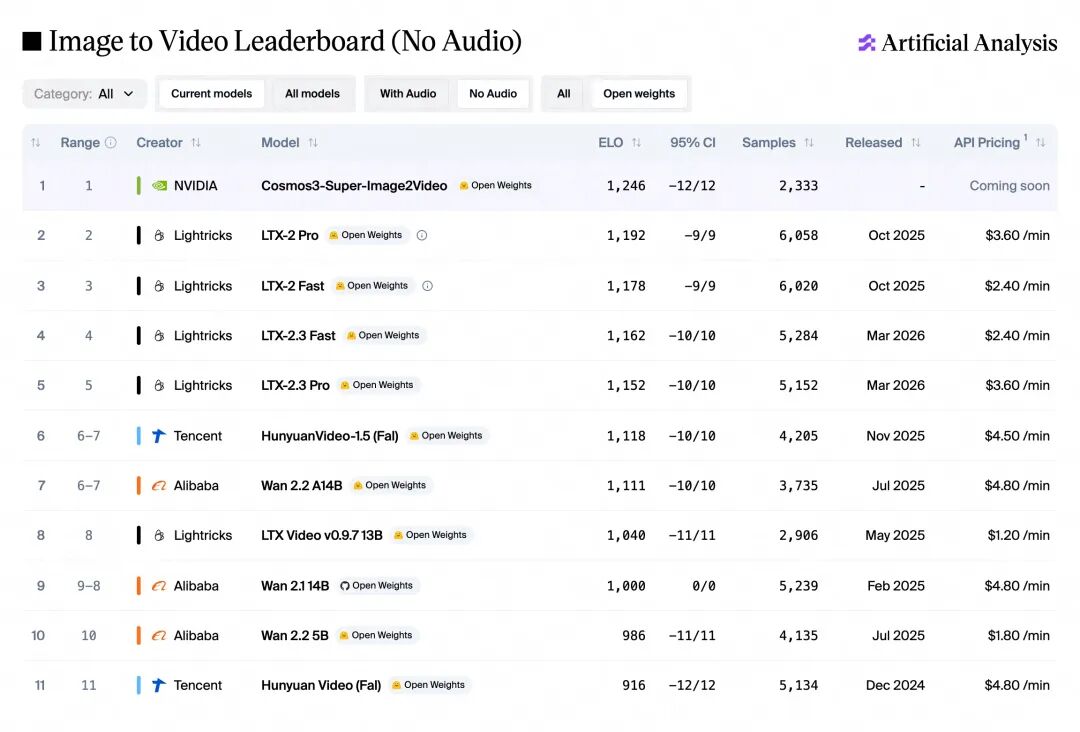
图6:Cosmos3-Super-Image2Video在Artificial Analysis图像到视频排行榜(无音频)中位列开源模型第一(来源:NVIDIA Cosmos 3技术报告)
如图6所示,在Artificial Analysis的公开众测排名中,Cosmos3-Super-Image2Video以1246分的ELO评分位居开源模型榜首。该模型在480p分辨率、189帧(约8秒)的配置下,能够生成具有高时间连贯性与物理合理性的视频内容。在人类评测协议Cosmos-HUE中,Cosmos3-Super在文本到视频任务上取得89.3分,图像到视频任务上取得89.6分,均为开源模型最优。在Human World Bench(HWB)评测中,Cosmos3-Super以71.9分的成绩超越所有评测模型,包括闭源商业模型Veo-3.1(67.8分)。
6.3 音视频同步生成:事件驱动的声音建模
Cosmos 3支持联合视频与音频生成,这在物理AI场景中具有重要意义——碰撞声揭示材料属性,工具声指示正在进行的操作,环境音提供场景上下文。在Cosmos-SoundBench评测中,Cosmos3-Nano在语义音频正确性(SA)、音视频对齐(AVAlign)与视觉支持(Visual Support)三项指标上均取得最优成绩,表明模型能够有效将声音事件与视觉源进行关联,并在正确的时间点生成对应的声学事件。

图7:Cosmos3-Nano生成的音视频对齐示例。彩色帧表示锤子敲击时刻,其时间标记与频谱图中的尖锐瞬态信号精确对应,灰色帧表示非接触时刻,无显著声学瞬态(来源:NVIDIA Cosmos 3技术报告)
图7展示了模型在铁匠打铁场景中的音视频同步能力。当锤子与铁砧接触时,频谱图中出现清晰的能量峰值;而在两次敲击之间的间隔期,声学信号保持平稳。这种精确的时间对齐对于物理仿真与具身智能的闭环训练至关重要。值得注意的是,Cosmos 3在音频-视觉语义 grounding 方面表现最强,但在低级别音频保真度上仍有提升空间,这表明模型已掌握事件级声音生成,后续可进一步优化声学质量。
6.4 迁移生成:从控制信号到逼真视频
Cosmos 3支持以边缘图、深度图、分割图、模糊图与世界场景地图为控制条件的视频迁移生成。在PAIBench-C评测中,模型在四种空间控制模态(深度、分割、模糊、边缘)上均匹配或超越专门的Cosmos-Transfer2.5基线。Cosmos3-Nano在感知质量(DOVER)与分割(mIoU)上领先,Cosmos3-Super在几何要求较高的边缘(F1)与深度(si-RMSE)任务上占优。
在自动驾驶专用的AVBench-C评测中,给定包含车道线、道路边界、交通信号灯及动态3D边界框的世界场景地图,Cosmos 3能够生成与地图结构严格一致的逼真驾驶视频。在人类评测中,Cosmos3-Super与Cosmos3-Nano的视频质量评分(2.86与2.82)显著优于基线(2.59),车道线保真度则与基线相当。这表明统一 backbone 在保持几何与结构保真度的同时,能够生成视觉上更高质量的驾驶场景。
七、物理AI应用:从模拟到真实世界的闭环
7.1 自动驾驶:世界场景地图到视频生成
Cosmos 3在自动驾驶领域展示了世界场景地图(World Scenario Map)条件化的视频生成能力。给定包含车道线、道路边界、交通信号灯及动态3D边界框的控制输入,模型能够生成与地图结构严格一致的逼真驾驶视频。在AVBench-C评测中,Cosmos3-Super与Cosmos3-Nano在动态物体对应、静态结构保持、环境一致性等自动评测指标上均优于专门的Cosmos-Transfer2.5基线模型;在人类评测中,视频质量评分也显示出明显优势。
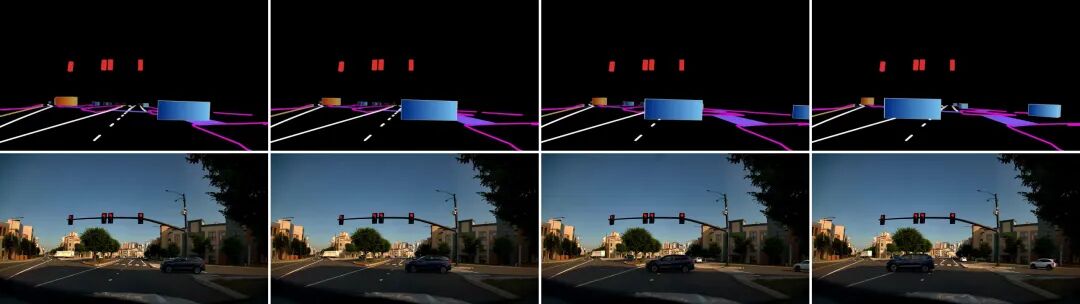
图8:Cosmos3-Nano根据720p控制视频(上排)生成对应的驾驶场景视频(下排)。控制视频编码了高精地图元素与动态交通参与者(来源:NVIDIA Cosmos 3技术报告)
如图8所示,模型生成的驾驶视频在纹理真实感、代理行为时间一致性与车道线位置准确性方面均达到较高水准。这种能力对于自动驾驶系统的闭环仿真测试具有重要意义——开发者可以在不依赖昂贵路测的情况下,生成无限多样的物理一致交通场景,用于验证感知、预测与规划算法的鲁棒性。
7.2 机器人操作:策略学习的统一基础
Cosmos 3在机器人领域的应用是其全模态设计最具代表性的体现。通过中期训练中的动作数据(涵盖第一人称运动、机器人操作、自动驾驶与相机运动四大领域,总计8.4M片段、6.13万小时),模型建立了可迁移的世界动作先验。在DROID数据集上的后训练实验表明,从中期训练检查点初始化的策略模型(Cosmos3-Nano-Policy-DROID)在RoboLab仿真基准与RoboArena真实世界基准上均取得最优成绩。

图9:机器人前向动力学定性比较。给定初始帧与动作指令,Cosmos3-Nano(MT-init)生成的未来帧更准确地遵循动作命令,且机械臂与织物的交互更为真实(来源:NVIDIA Cosmos 3技术报告)
图9展示了在布料操作任务中的前向动力学生成结果。与基线模型Ctrl-World相比,Cosmos3-Nano生成的机械臂运动更加平滑,与布料的物理交互(如褶皱、遮挡)更加符合真实世界的物理规律。绿色框标注了基线输出中可见的失真区域,而Cosmos3-Nano的对应区域则保持了视觉一致性。
在RoboLab仿真基准上,Cosmos3-Nano-Policy-DROID在120项语言条件任务中取得39.7%的平均成功率(特定指令条件下),超越π0.5(28.1%)与DreamZero(25.2%)。在RoboArena真实世界基准上,该模型截至2026年5月30日位居分布式众测排行榜首位。模型能够可靠完成简单的拾取放置任务,也能处理需要多步骤顺序执行的长程任务,并对未见过的物体与任务展现出良好的泛化能力。
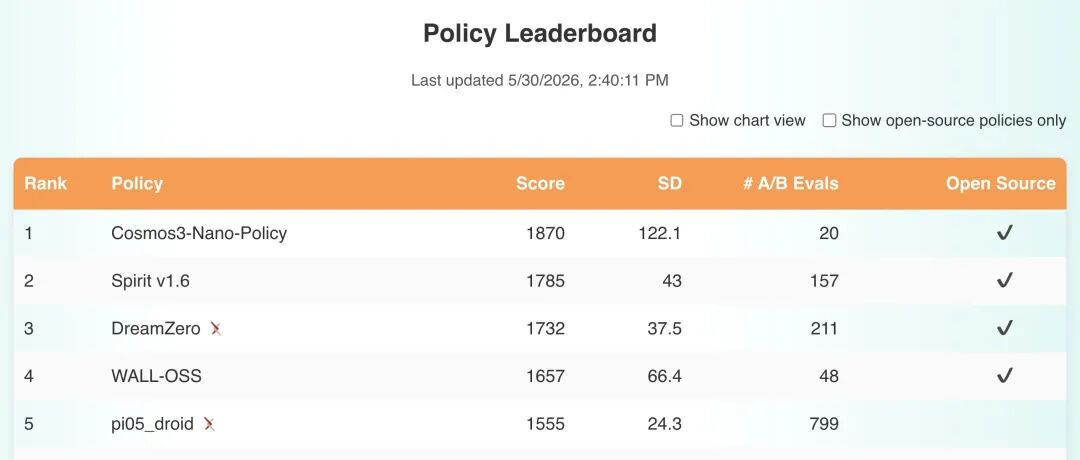
图10:Cosmos3-Nano-Policy-DROID在RoboArena真实世界机器人策略排行榜上位列第一(来源:NVIDIA Cosmos 3技术报告)
7.3 跨域动作协同:统一训练的正向迁移
技术报告中的协同研究(Synergy Study)揭示了跨领域动作训练的价值。实验表明,相机运动数据与机器人操作数据之间存在显著的正向迁移:将Google Robot数据与WidowX-250数据联合训练,后者的前向动力学PSNR提升1.39dB,策略PSNR提升2.29dB。此外,第一人称人体运动数据作为机器人适应的先验也显示出积极作用——在AgiBot机器人操作任务中,使用人体运动数据进行预热训练可使中期训练初始化模型的表现持续优于直接从预训练检查点初始化的模型。
在LIBERO-10环境的快速适应实验中,中期训练初始化模型在500次迭代后即达到24.6%的成功率,而预训练初始化模型仍为0%;至2000次迭代时,中期训练初始化模型达到97.4%的成功率,预训练初始化模型为95.2%。这表明统一动作中期训练不仅改善孤立领域,还产生了可复用的动作域先验,加速跨下游设置的收敛。
7.4 视觉语言推理: grounded 物理世界理解
Cosmos 3推理器在48项基准上进行了评估,涵盖通用多模态理解、机器人、智能基础设施与自动驾驶四大类别。在通用基准上,Cosmos 3与开源模型具有竞争力,在机器人、智能基础设施与自动驾驶领域则超越包括RynnBrain、Mimo-Embodied与Gemma-4在内的开源与闭源模型。
在机器人领域,Cosmos 3在Cosmos-ER、Cosmos-CS、RefSpatial、VSI-Bench、SparBench等17项基准上表现优异,涵盖具身常识与任务推理、空间定位与场景几何、机器人导向感知与动作理解等能力。在智能基础设施领域,VANTAGE-Bench与TAR评测覆盖仓库物流、交通与固定摄像头场景中的语义、空间、时序与时空理解。在驾驶领域,LingoQA与两项内部安全关键驾驶事件分类基准评测显示Cosmos 3在碰撞预测与停车行为分类上的强大能力。
八、提示工程与使用指南
8.1 结构化提示与提示上采样
Cosmos 3生成器在结构化JSON提示上训练,涵盖场景想象、时间描述、音频描述、主体、背景、光照、美学、摄影、风格、文本标识等字段。为降低用户的提示工程负担,模型支持提示上采样(Prompt Upsampling)模式:由Cosmos 3推理器或Claude Opus将简短的自然语言请求扩展为丰富的结构化场景描述,再提供给生成器作为条件输入。
提示上采样不仅重写提示,更将稀疏的用户输入扩展为物理上 grounded 的控制语言,捕获场景布局、时间演化与音频线索。上采样器首先想象一个连贯的世界状态,然后将其映射为时间展开,最后推导与可见事件同步的音频线索。这种分离使提示理解成为可独立检查的组件,而非与渲染过程纠缠在一起。
8.2 采样配置与负提示
Cosmos 3针对不同模态与任务优化了采样超参数。对于基础Nano与Super生成器,音视频生成使用50步去噪、引导尺度6、时间移位10与全范围分类器自由引导。后训练的Text2Image模型使用引导尺度4、时间移位3;Image2Video模型使用时间移位5。动作生成的前向/逆动力学模式使用引导尺度1、时间移位5;策略模式使用4步去噪、引导尺度3。
负提示经过自动化基准迭代调优。基础生成器使用详细的结构化负提示,涵盖模糊主体、不自然姿态、帧间不连续、压缩伪影、物理不合理等描述。后训练变体则根据任务采用空字符串或从用户提示自动推导的负提示。对于视频迁移任务,模型采用双权重分类器自由引导,分别控制文本与条件视频的权重,实现结构遵循与语义保真之间的独立调节。
九、开源生态与社区贡献
NVIDIA将Cosmos 3系列模型以OpenMDW-1.1许可证开源,涵盖代码、模型检查点、精选合成数据集及评测基准。社区可通过HuggingFace获取模型权重(Cosmos3-Nano、Cosmos3-Super及其后训练变体),通过GitHub获取训练与推理代码。发布的合成数据集包括物理交互场景(SDG-PhyxSim)、机器人操作场景(SDG-RobotSim)、自动驾驶场景(SDG-DriveSim)、数字人场景(SDG-SynHuman)与仓储作业场景(SDG-Warehouse),总计数百万样本,为物理AI研究提供了宝贵的训练资源。
模型与资源获取
**HuggingFace模型仓库:nvidia/Cosmos3 合集GitHub开源代码:github.com/NVIDIA/cosmos技术报告:**research.nvidia.com/labs/cosmos-lab/cosmos3/**评测基准:**Cosmos-HUE(人类评测)、Cosmos-SoundBench(音频评测)、SDG系列合成数据集
开源生态的建设对于物理AI领域的发展至关重要。通过提供预训练权重、训练代码与大规模合成数据,Cosmos 3降低了研究者和开发者进入物理AI领域的门槛。无论是希望构建机器人策略的研究团队,还是需要生成自动驾驶仿真数据的工程团队,都可以基于Cosmos 3进行快速原型开发与领域适配。
十、结语:迈向通用物理智能
Cosmos 3的发布标志着世界模型研究进入全模态统一的新阶段。通过将语言理解、视觉感知、视频模拟、音频合成与动作控制整合在单一架构中,Cosmos 3为物理AI代理提供了一个可共享、可扩展、可 specialization 的基础模型。其在图像生成、视频生成、机器人策略与自动驾驶仿真等任务上的领先性能,验证了统一架构相较于碎片化方案的技术优势。
随着模型权重、训练数据与评测工具的开源,Cosmos 3有望成为连接合成世界与真实世界的桥梁——为机器人研究提供高质量的合成训练数据,为具身智能模型提供更强的初始化起点,为闭环策略训练提供物理一致的仿真环境。在通往通用物理智能的道路上,统一的世界模型正成为不可或缺的基础设施。
从技术架构到数据基础设施,从训练配方到推理优化,从生成质量到物理一致性,Cosmos 3展现了NVIDIA在物理AI领域的系统性布局。这不仅是一次模型发布,更是一场关于如何构建能够理解、模拟并作用于物理世界的智能系统的范式探索。未来,随着社区基于Cosmos 3的持续创新,我们有理由期待物理AI代理在真实世界中展现出更强的通用性与可靠性。
本文基于NVIDIA Cosmos 3技术报告及相关公开资料整理
参考文献:[1] NVIDIA. Cosmos 3: Omnimodal World Models for Physical AI. Technical Report, 2026.
具身智能&世界模型blog: https://jinxindeep.github.io/blog/blog2026.html

电影级数字人,免显卡端渲染SDK,十行代码即可调用,工业级demo免费开源下载!
更多推荐



 10
10 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)